MySQL特定表全量、增量数据同步到消息队列-解决方案
目录
- 1、原始需求
- 2、解决方案
- 3、canal介绍、安装
- canal的工作原理
- 架构
- 安装
- 4、验证
1、原始需求
既要同步原始全量数据,也要实时同步MySQL特定库的特定表增量数据,同时对应的修改、删除也要对应。
数据同步不能有侵入性:不能更改业务程序,并且不能对业务侧有太大性能压力。
应用场景:数据ETL同步、降低业务服务器压力。
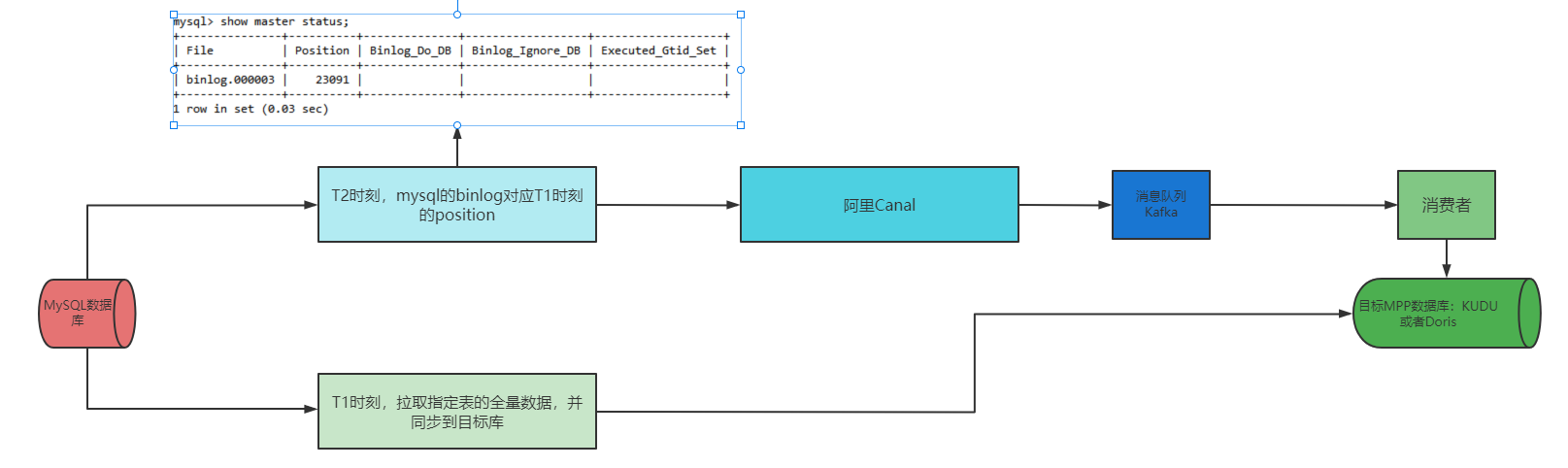
2、解决方案
3、canal介绍、安装
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
工作原理:mysql主备复制实现
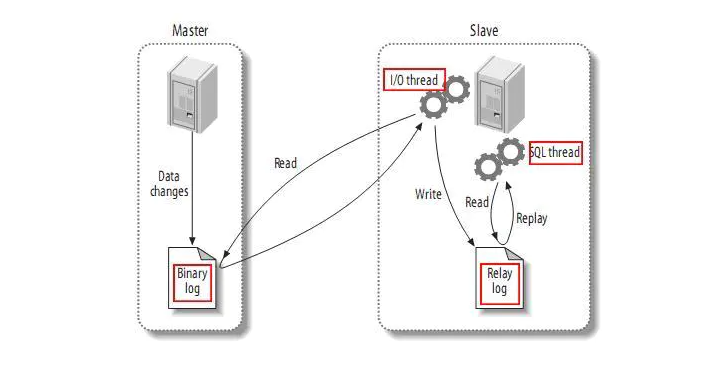
从上层来看,复制分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
canal的工作原理
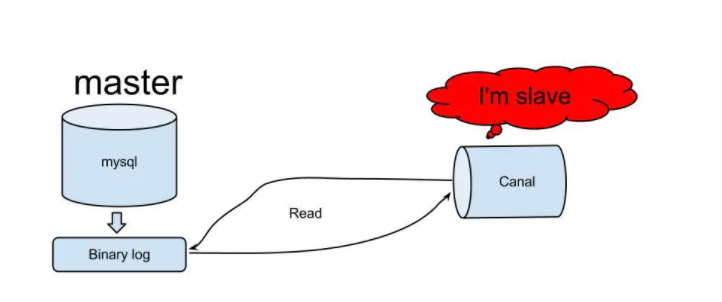
原理相对比较简单:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
架构
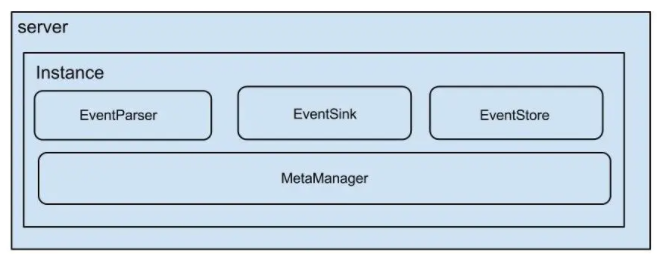
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
安装
1、mysql、kafka环境准备
2、canal下载:wget https://github.com/alibaba/canal/releases/download/canal-1.1.3/canal.deployer-1.1.3.tar.gz
3、解压:tar -zxvf canal.deployer-1.1.3.tar.gz
4、对目录conf里文件参数配置
对canal.properties配置:
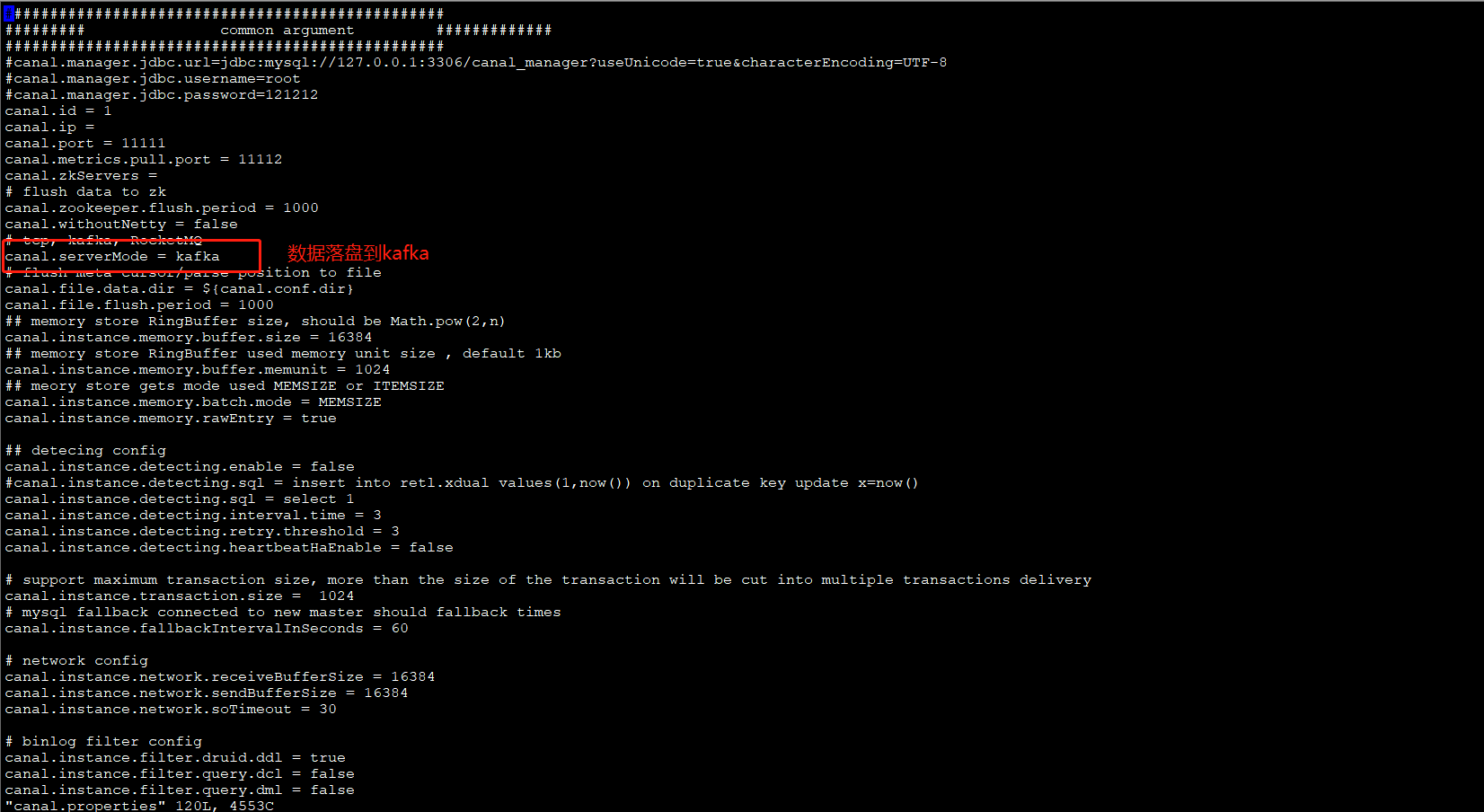
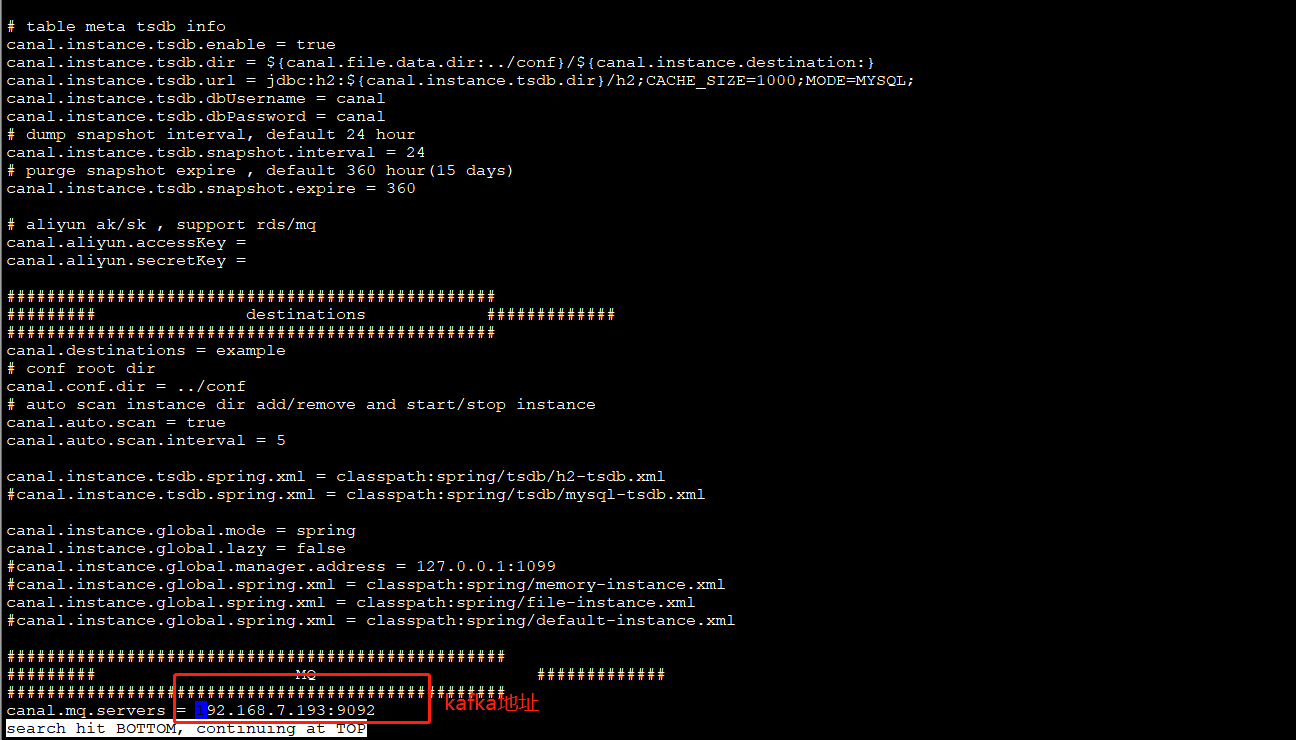
进入conf/example里,对instance.properties配置:
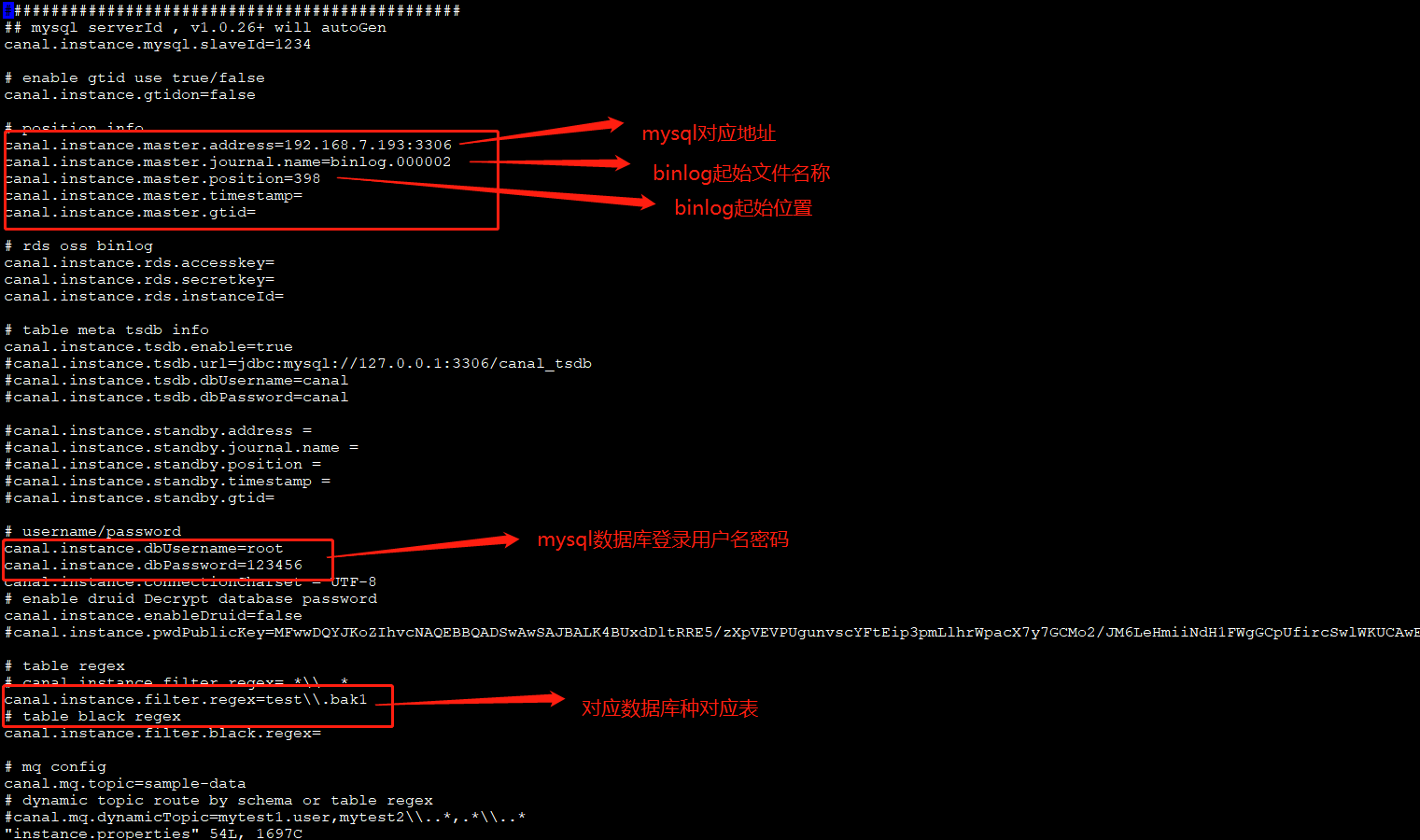
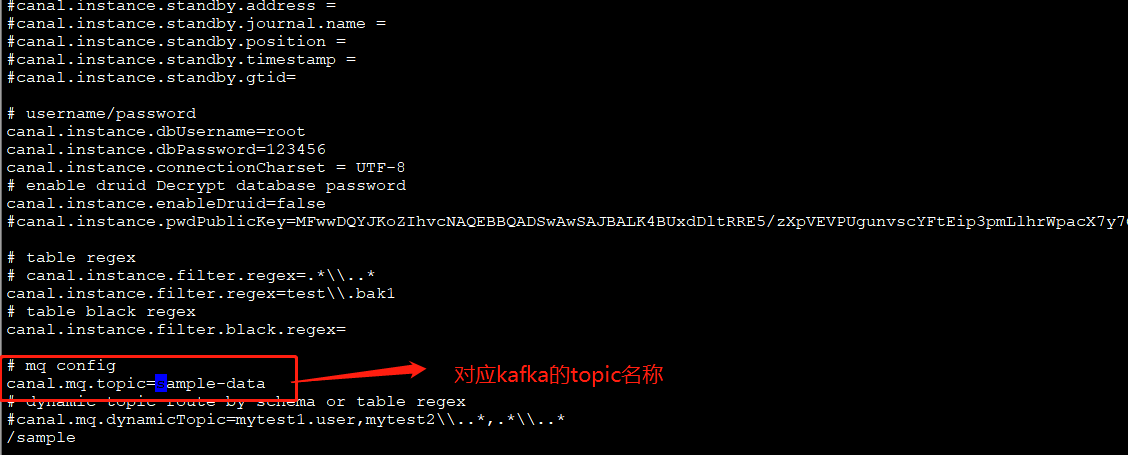
5、启动:bin/startup.sh
6、日志查看:

4、验证
1、开发对应的kafka消费者
package org.kafka;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
/**
*
* Title: KafkaConsumerTest
* Description:
* kafka消费者 demo
* Version:1.0.0
* @author pancm
* @date 2018年1月26日
*/
public class KafkaConsumerTest implements Runnable {
private final KafkaConsumer<String, String> consumer;
private ConsumerRecords<String, String> msgList;
private final String topic;
private static final String GROUPID = "groupA";
public KafkaConsumerTest(String topicName) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.7.193:9092");
props.put("group.id", GROUPID);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("auto.offset.reset", "latest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<String, String>(props);
this.topic = topicName;
this.consumer.subscribe(Arrays.asList(topic));
}
@Override
public void run() {
int messageNo = 1;
System.out.println("---------开始消费---------");
try {
for (; ; ) {
msgList = consumer.poll(1000);
if (null != msgList && msgList.count() > 0) {
for (ConsumerRecord<String, String> record : msgList) {
//消费100条就打印 ,但打印的数据不一定是这个规律的
System.out.println(messageNo + "=======receive: key = " + record.key() + ", value = " + record.value() + " offset===" + record.offset());
// String v = decodeUnicode(record.value());
// System.out.println(v);
//当消费了1000条就退出
if (messageNo % 1000 == 0) {
break;
}
messageNo++;
}
} else {
Thread.sleep(11);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
public static void main(String args[]) {
KafkaConsumerTest test1 = new KafkaConsumerTest("sample-data");
Thread thread1 = new Thread(test1);
thread1.start();
}
/*
* 中文转unicode编码
*/
public static String gbEncoding(final String gbString) {
char[] utfBytes = gbString.toCharArray();
String unicodeBytes = "";
for (int i = 0; i < utfBytes.length; i++) {
String hexB = Integer.toHexString(utfBytes[i]);
if (hexB.length() <= 2) {
hexB = "00" + hexB;
}
unicodeBytes = unicodeBytes + "\\u" + hexB;
}
return unicodeBytes;
}
/*
* unicode编码转中文
*/
public static String decodeUnicode(final String dataStr) {
int start = 0;
int end = 0;
final StringBuffer buffer = new StringBuffer();
while (start > -1) {
end = dataStr.indexOf("\\u", start + 2);
String charStr = "";
if (end == -1) {
charStr = dataStr.substring(start + 2, dataStr.length());
} else {
charStr = dataStr.substring(start + 2, end);
}
char letter = (char) Integer.parseInt(charStr, 16); // 16进制parse整形字符串。
buffer.append(new Character(letter).toString());
start = end;
}
return buffer.toString();
}
}
2、对表bak1进行增加数据
CREATE TABLE `bak1` ( `vin` varchar(20) NOT NULL, `p1` double DEFAULT NULL, `p2` double DEFAULT NULL, `p3` double DEFAULT NULL, `p4` double DEFAULT NULL, `p5` double DEFAULT NULL, `p6` double DEFAULT NULL, `p7` double DEFAULT NULL, `p8` double DEFAULT NULL, `p9` double DEFAULT NULL, `p0` double DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 show create table bak1; insert into bak1 select '李雷abcv', `p1` , `p2` , `p3` , `p4` , `p5` , `p6` , `p7` , `p8` , `p9` , `p0` from moci limit 10
3、查看输出结果:
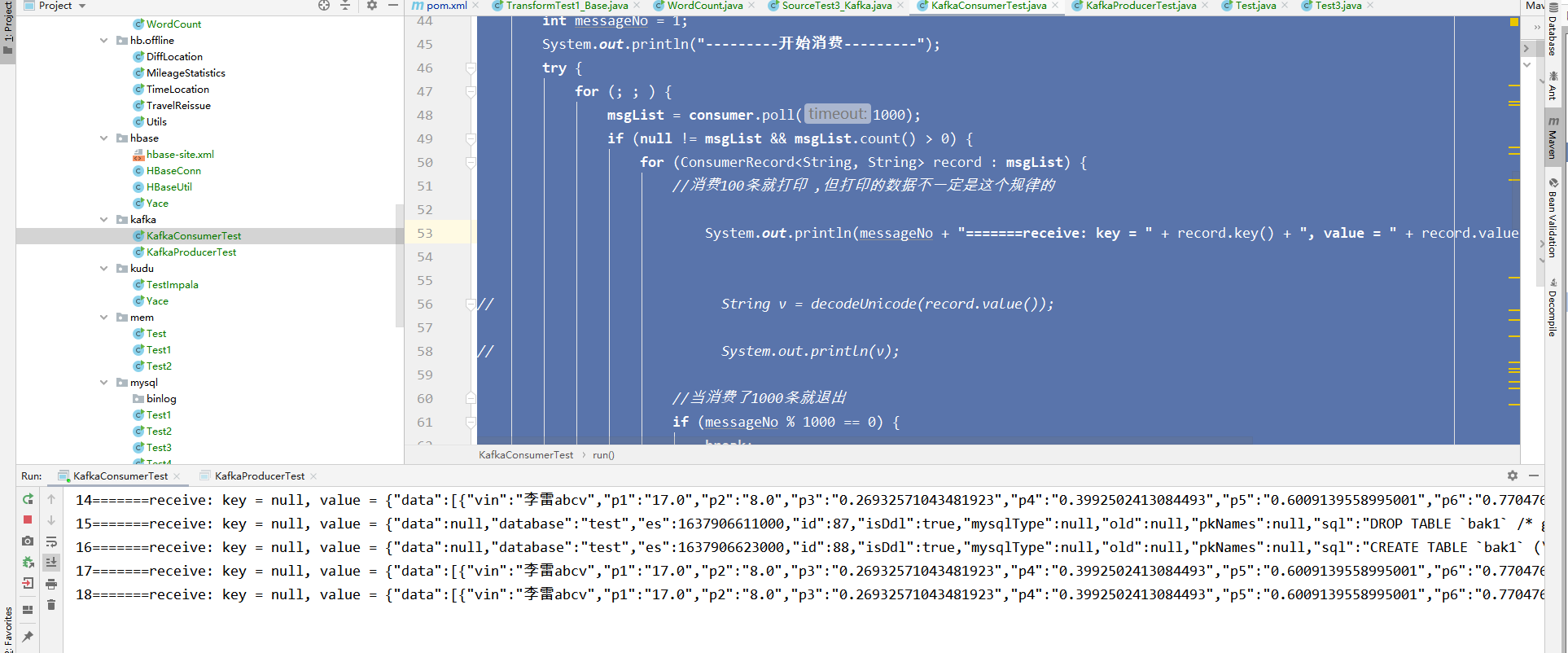
到此这篇关于MySQL特定表全量、增量数据同步到消息队列-解决方案的文章就介绍到这了,更多相关MySQL特定表数据同步内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL5.6主从复制(mysql数据同步配置)
规划 master 192.168.56.2 slave 192.168.56.5 1.在主库上,设置一个复制使用的账户rep1,并授予REPLICATION SLAVE权限. mysql> grant replication slave on *.* to 'rep1'@'192.168.56.2' identified by '123456'; Query OK, 0 rows affected (0.01 sec) 2.修改主数据库服务器的配置文件my.cnf,开启BINLOG,并设置s
-

详解Mysql如何实现数据同步到Elasticsearch
目录 一.同步原理 二.logstash-input-jdbc 三.go-mysql-elasticsearch 四.elasticsearch-jdbc 五.logstash-input-jdbc实现同步 六.go-mysql-elasticsearch实现同步 七.elasticsearch-jdbc实现同步 一.同步原理 基于Mysql的binlog日志订阅:binlog日志是Mysql用来记录数据实时的变化 Mysql数据同步到ES中分为两种,分别是全量同步和增量同步 全量同步表示第一次
-
用python简单实现mysql数据同步到ElasticSearch的教程
之前博客有用logstash-input-jdbc同步mysql数据到ElasticSearch,但是由于同步时间最少是一分钟一次,无法满足线上业务,所以只能自己实现一个,但是时间比较紧,所以简单实现一个 思路: 网上有很多思路用什么mysql的binlog功能什么的,但是我对mysql了解实在有限,所以用一个很呆板的办法查询mysql得到数据,再插入es,因为数据量不大,而且10秒间隔同步一次,效率还可以,为了避免服务器之间的时间差和mysql更新和查询产生的时间差,所以在查询更新时间条件时是
-
mysql 数据同步 出现Slave_IO_Running:No问题的解决方法小结
下面写一下,这两个要是有no了,怎么恢复.. 如果是slave_io_running no了,那么就我个人看有三种情况,一个是网络有问题,连接不上,像有一次我用虚拟机搭建replication,使用了nat的网络结构,就是死都连不上,第二个是有可能my.cnf有问题,配置文件怎么写就不说了,网上太多了,最后一个是授权的问题,replication slave和file权限是必须的.如果不怕死就all咯.. 一旦io为no了先看err日志,看看爆什么错,很可能是网络,也有可能是包太大收不了,这个时
-
怎么使 Mysql 数据同步
怎么使 Mysql 数据同步 先假设有主机 A 和 B ( Linux 系统),主机 A 的 IP 分别是 1.2.3.4 (当然,也可以是动态的),主机 B 的 IP 是 5.6.7.8 .两个主机都装上了 PHP+Mysql ,现在操作的是主机 A 上的资料,如果另外一个主机 B 想跟 A 的资料进行同步,应该怎么做呢? OK,我们现在就动手. 首先,如果要想两个主机间的资料同步,一种方法就是主机 A 往主机 B 送资料,另外一种主法就是主机 B 到主机 A 上拿资料,因为 A 的 IP 是
-
MYSQL5 masterslave数据同步配置方法第1/3页
测试环境.基本上数据是瞬间同步,希望对大家有帮助 RedHat ES 3 update 3 MYSQL 5.0.15 MYSQL数据同步备份 A服务器: 192.168.1.2 主服务器master B服务器: 192.168.1.3 副服务器slave A服务器设置 #mysql –u root –p mysql>GRANT FILE ON *.* TO backup@192.168.1.3 IDENTIFIED BY '1234'; mysql>exit 上面是Master开放一个账号ba
-
mysql 备份与迁移 数据同步方法
不过最近发现这个可视化操作有点点问题,就是当数据条数超过一定数目EMS SQL Manager就挂了,也不知道是否是软件问题--当然该开始我是将大的数据库文件分拆成小份小份的,多次导入. 刚才发现同事用了mysql 自带的mysqldump 工具就不存在这个问题. (羞愧,不过我平时极少接触数据库) 这里记录下操作方式: 1. 进入bin目录,执行命令: mysqldump -hlocalhost -uroot -padmin local_db > a.sql 2. 这时发现在bin目录生成了
-
mysql 触发器实现两个表的数据同步
mysql通过触发器实现两个表的同步 目前,在本地测试成功. 假设本地的两个数据库a和b,a下有表table1(id, val) b下有表table2(id, val) 假设希望当table1中数据更新,table2中数据同步更新. 代码: DELIMITER $$ CREATE /*[DEFINER = { user | CURRENT_USER }]*/ TRIGGER `a`.`触发器名` BEFORE UPDATE ON `a`.`table1` FOR EACH ROW BEGIN I
-
减少mysql主从数据同步延迟问题的详解
基于局域网的master/slave机制在通常情况下已经可以满足'实时'备份的要求了.如果延迟比较大,就先确认以下几个因素: 1. 网络延迟2. master负载3. slave负载一般的做法是,使用多台slave来分摊读请求,再从这些slave中取一台专用的服务器,只作为备份用,不进行其他任何操作,就能相对最大限度地达到'实时'的要求了 另外,再介绍2个可以减少延迟的参数 –slave-net-timeout=seconds 参数含义:当slave从主数据库读取log数据失败后,等待多久重新
-
node.js将MongoDB数据同步到MySQL的步骤
前言 最近由于业务需要,APP端后台需要将MongoDB中的数据同步到Java端后台的MySQL中,然后又将MySQL中算好的数据,同步到MongoDB数据库. 这个过程看是很繁琐,实际上这就是一个互相写表的过程. 接下来就看看node.js将MongoDB中的数据批量插入到MySQL数据库的实现过程.话不多说了,来一起看看详细的介绍吧. 环境 node.js MongoDB MySQL npm 需要的模块 mongoose MySQL 准备好MongoDB中的数据 比如说:我这里要同步的是用户