Python Django 数据库的相关操作详解
目录
- 前言
- 创建对象
- 方式一:
- 方式二:
- 更新对象
- 方式一:
- 方式二:
- 方式三:
- 查询
- 检索全部对象:
- 条件过滤:
- 方式一:
- 方式二:
- 检索单个对象:
- 总结
前言
上篇已经介绍过模型相关操作,并创建好了数据库及相关表字段,接下来将通过以下表在Django中进行表数据的增改查。
from django.db import models
class Student(models.Model):
"""
学生表
"""
name = models.CharField('学生姓名', max_length=200, unique=True, help_text='学生姓名')
gender = models.SmallIntegerField('性别', default='1', help_text='性别')
hobby = models.CharField('爱好', max_length=200, null=True, blank=True, help_text='兴趣爱好')
create_time = models.DateTimeField('创建时间', auto_now_add=True, help_text='创建时间')
class Meta:
"""
元数据,
"""
db_table = 'student' # 指定当前模型创建的表明,不写默认当前的模型名Student
verbose_name = '学生信息表' # 注释
verbose_name_plural = verbose_name # 指定为复数
ordering = ['-create_time'] # 使用创建时间倒序排序,不加-为正序
def __str__(self):
return self.name # 方便于调式,下面操作数据库时会体现出来

为了更方便调试,接下来通过控制台输出的形式进行相关操作,通过python manage.py shell命令会导入当前项目的django环境,在此前需要配置下日志输出的相关信息,将以下配置在settings.py文件中:
# 日志配置
LOGGING = {
'version': 1,
'handlers': {
'console': {
'class': 'logging.StreamHandler'
}
},
'loggers': {
'django': {
'handlers': ['console'],
'level': 'DEBUG',
'propagate': False
}
}
}

创建对象
前面介绍过一个模型类代表一张表,而类的实例则代表表中的一条记录,所以可以通过实例化模型类的形式来进行表记录创建,如下:
方式一:
实例化时创建传入字段,然后通过save方法保存
# 导入模型类
In [1]: from project2s.models import Student
# 实例化对象,传入必传字段
In [2]: s = Student(name='test',hobby='打篮球')
# 调用save方法保存到数据库,
In [3]: s.save()
# 输出内容如下:其底层还是使用的INSERT语句
(0.031) INSERT INTO `student` (`name`, `gender`, `hobby`, `create_time`) VALUES ('test', 1, '打篮球', '2021-11-10 12:49:13.814987') RETURNING `student`.`id`; args=('test', 1, '打篮球',
'2021-11-10 12:49:13.814987')
数据库插入成功:

方式二:
先实例化然后通过给属性赋值的形式,在通过save方法保存
In [2]: s1 = Student()
In [3]: s1.name = 'test1'
In [4]: s1.hobby = '唱歌'
In [5]: s1.save()
(0.031) INSERT INTO `student` (`name`, `gender`, `hobby`, `create_time`) VALUES ('test1', 1, '唱歌', '2021-11-10 13:13:41.183826') RETURNING `student`.`id`; args=('test1', 1, '唱歌', '
2021-11-10 13:13:41.183826')
数据库插入成功:

更新对象
更新时会检索对象的id是否存在,存在即修改。
修改实例属性,并通过save方法保存到数据库,底层使用UPDATE语句
方式一:
In [6]: s1.name = '测试'
In [7]: s1.save()
(0.031) UPDATE `student` SET `name` = '测试', `gender` = 1, `hobby` = '唱歌', `create_time` = '2021-11-10 13:13:41.183826' WHERE `student`.`id` = 2; args=('测试', 1, '唱歌', '2021-11-1
0 13:13:41.183826', 2)
数据库更新成功:
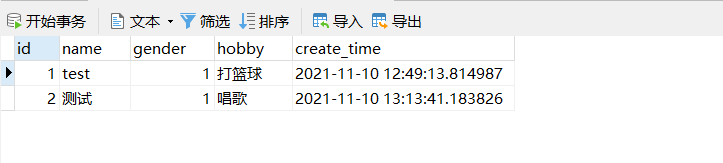
但只是修改了一个字段,可见UPDATE语句执行时修改了全部字段会造成性能问题,可以通过以下方式指定字段更新。
方式二:
save时通过update_fields指定字段
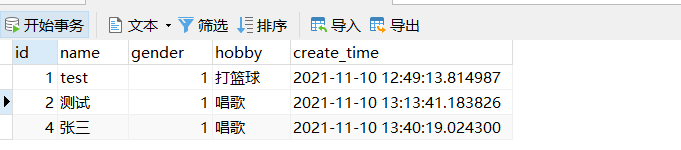
# 前面已经实例化过s2=Student(name='张三',hobby='唱歌')
In [11]: s2.name = '李四'
In [12]: s2.save(update_fields=['name'])
(0.047) UPDATE `student` SET `name` = '李四' WHERE `student`.`id` = 4; args=('李四', 4)
数据库更新成功:

方式三:
批量修改,通过模型类管理器objects,查询到所有记录,在调用update方法
In [2]: Student.objects.all().update(hobby='玩游戏')
(0.031) UPDATE `student` SET `hobby` = '玩游戏'; args=('玩游戏',)
Out[2]: 3
数据库更新成功:

查询
查询使用模型类的管理器objects,前面批量更改时已经用到过,当通过管理器查询,会生成一个QuerySet对象,代表了数据库中对象的集合,它可以迭代,支持切片,不支持负索引,还可以用list转换成列表。在sql的层面上个代表了select语句。
检索全部对象:
Stutent.objects.all() 得到的是QuerySet对象,模型类中定义了__ str __方法,输出了name。
In [4]: Student.objects.all() Out[4]: (0.094) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 21; a rgs=() <QuerySet [<Student: 李四>, <Student: 测试>, <Student: test>]> # 转换成列表 In [5]: list(Student.objects.all()) (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC; args=() Out[5]: [<Student: 李四>, <Student: 测试>, <Student: test>] # 通过索引 In [6]: Student.objects.all()[0] (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 1; args=() Out[6]: <Student: 李四> # 通过切片 In [5]: Student.objects.all()[:2] # 等价于 LIMIT 2 Out[5]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 2; ar gs=() <QuerySet [<Student: 李四>, <Student: 测试>]> In [4]: Student.objects.all()[1:2] # 等价于 LIMIT 1 OFF SET 1 Out[4]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 1 OFF SET 1; args=() <QuerySet [<Student: 测试>]>
条件过滤:
方式一:
filter(**kwargs),包含满足给定查询参数的对象
In [4]: Student.objects.all().filter(name='李四')
Out[4]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` WHERE `student`.`name` = '李四' ORDER BY `student
`.`create_time` DESC LIMIT 21; args=('李四',)
<QuerySet [<Student: 李四>]>
方式二:
exclude(**kwargs) ,不包含满足给定查询参数的对象
In [4]: Student.objects.all().exclude(name='李四')
Out[4]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` WHERE NOT (`student`.`name` = '李四') ORDER BY `s
tudent`.`create_time` DESC LIMIT 21; args=('李四',)
<QuerySet [<Student: 测试>, <Student: test>]>
检索单个对象:
通过get方法如果检索超过1条数据会报错,所以一般配合pk使用
In [4]: Student.objects.all().get(pk=1) (0.047) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` WHERE `student`.`id` = 1 LIMIT 21; args=(1,) Out[4]: <Student: test>
返回第一条数据:
Stutent.objects.all().first()
In [5]: Student.objects.all().first() (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 1; args=() Out[5]: <Student: 李四>
返回最后一条数据:
Stutent.objects.all().last()
In [6]: Student.objects.all().last() (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` ASC LIMIT 1; args=() Out[6]: <Student: test>
由于模型类Meta内设置了通过时间倒序排序,所以查询结果会相反。
排序:
order_by(*fields),根据给定的字段进行排序。默认按照模型类中的Meta类来排序。
正序:
In [3]: Student.objects.all().order_by('name')
Out[3]: (0.047) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`name` ASC LIMIT 21; args=()
<QuerySet [<Student: test>, <Student: 李四>, <Student: 测试>]>
倒序:
In [4]: Student.objects.all().order_by('-name')
Out[4]: (0.047) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`name` DESC LIMIT 21; args=()
<QuerySet [<Student: 测试>, <Student: 李四>, <Student: test>]>
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Django-Model数据库操作(增删改查、连表结构)详解
一.数据库操作 1.创建model表 基本结构 from django.db import models class userinfo(models.Model): #如果没有models.AutoField,默认会创建一个id的自增列 name = models.CharField(max_length=30) email = models.EmailField() memo = models.TextField() 更多字段: 1.models.AutoField 自增列= int(11)
-

Django基于ORM操作数据库的方法详解
本文实例讲述了Django基于ORM操作数据库的方法.分享给大家供大家参考,具体如下: 1.配置数据库 vim settings #HelloWorld/HelloWorld目录下 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', #mysql数据库中第一个库test 'NAME': 'test', 'USER': 'root', 'PASSWORD': '123456', 'HOST':'127.0.0.1', '
-
Django框架ORM数据库操作实例详解
本文实例讲述了Django框架ORM数据库操作.分享给大家供大家参考,具体如下: 测试数据:BookInfo表 PeopleInfo表 一.增加 1.save: 对象 = 模型类( 字段名 = 值, 字段名 = 值, - ) 对象.save() 例: >>> book = BookInfo( ... name='python入门', ... pub_date='2010-1-1' ... ) >>> book.save() >>> book <B
-
django inspectdb 操作已有数据库数据的使用步骤
inspectdb使用步骤 1.配置项目setting文件 2.配置项目__init__.py 使用pymysql连接数据库 import pymysql pymysql.version_info = (1, 20, 23) pymysql.install_as_MySQLdb() 3.在terminal中执行语句 python manage.py inspectdb > [your app name]\models.py 4.执行迁移 python manage.py makemigratio
-
Django项目优化数据库操作总结
目录 合理的创建索引 设置数据库持久连接 减少SQL的执行次数 仅获取需要的字段数据 使用批量创建.更新和删除,不随意对结果排序 参考网址:Django官方数据库优化 使用 QuerySet.explain() 来了解你的数据库是如何执行特定的 QuerySet 的. 你可能还想使用一个外部项目,比如 django-debug-toolbar ,或者一个直接监控数据库的工具. 合理的创建索引 索引可能有助于加快查询速度,但是也要注意索引会占用磁盘空间,创建不必要的索引只会形成浪费.数据库表中的主
-
Django 数据库同步操作技巧详解
同步数据库: 使用上述两条命令同步数据库 1.认识migrations目录: migrations目录作用:用来存放通过makemigrations命令生成的数据库脚本,里面的生成的脚本不要轻易修改. 要正常的使用数据库同步的功能,app目录下必须要有migrations目录,且目录下存在__init__.py文件. 2.认识一张数据表(django_migrations) 表中的字段: app:app名字 name:执行的脚本文件的名称 applied:脚本执行的时间也显示了 hello_ap
-
Python Django 数据库的相关操作详解
目录 前言 创建对象 方式一: 方式二: 更新对象 方式一: 方式二: 方式三: 查询 检索全部对象: 条件过滤: 方式一: 方式二: 检索单个对象: 总结 前言 上篇已经介绍过模型相关操作,并创建好了数据库及相关表字段,接下来将通过以下表在Django中进行表数据的增改查. from django.db import models class Student(models.Model): """ 学生表 """ name = models.Ch
-
python框架django项目部署相关知识详解
这篇文章主要介绍了python框架django项目部署相关知识详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一:项目部署的框架 nginx和uWSGI在生产服务器上进行的部署 二:什么是nginx? nginx是一个web服务器. 什么是web服务器? web服务器则主要是让客户可以通过浏览器进行访问,处理HTML文件,css文件,js文件,图片等资源.web服务器一般要处理静态文件.对接服务器. 什么是静态文件? css,js,html
-
Python Pandas学习之基本数据操作详解
目录 1索引操作 1.1直接使用行列索引(先列后行) 1.2结合loc或者iloc使用索引 1.3使用ix组合索引 2赋值操作 3排序 3.1DataFrame排序 3.2Series排序 为了更好的理解这些基本操作,下面会通过读取一个股票数据,来进行Pandas基本数据操作的语法介绍. # 读取文件(读取保存文件后面会专门进行讲解,这里先直接调用下api) data = pd.read_csv("./data/stock_day.csv") # 读取当前目录下一个csv文件 # 删
-
Python读写JSON文件的操作详解
目录 JSON JSON 起源 JSON 样例 Python 原生支持 JSON 序列化 JSON 简单的序列化示例 JSON 反序列化 简单的反序列化示例 应用案例 编码和解码 JSON JSON 起源 JSON 全称 JavaScript Object Notation .是处理对象文字语法的 JavaScript 编程语言的一个子集.JSON 早已成为与语言无关的语言,并作为自己的标准存在. JSON 样例 { "data":[ { "id": "1
-
Python实现数据的序列化操作详解
目录 Json 模块 dumps()函数 dump()函数 loads()函数 load()函数 Pickle 模块 dumps()函数 dump()函数 loads()函数 load()函数 总结 在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块.这两个模块主要区别如下: json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式: json 是我们可以直观阅读的,而 p
-
Python YAML文件的读写操作详解
目录 YAML格式 YAML文件 YAML操作 读取 存储 示例 转字典 转列表 YAML是一种数据序列化格式,方便人类阅读,且容易和脚本语言交互.常用于配置文件,也用于数据存储或传输. YAML格式 YAML三种基本数据类型: 1.标量:如字符串.整数和浮点数.日期 布尔值:“true”.“True”.“TRUE”.“yes”.“Yes"和"YES”,“false”.“False”.“FALSE”.“no”.“No"和"NO” 空:null.Null.~或不指定值
-
MySQL数据库中表的操作详解
目录 1.Mysql中的数据类型 2.创建数据表 3.删除表 4.插入数据 5.更新数据 6.删除数据 7.快速复制表 8.快速删除表数据 1.Mysql中的数据类型 varchar 动态字符串类型(最长255位),可以根据实际长度来动态分配空间,例如:varchar(100) char 定长字符串(最长255位),存储空间是固定的,例如:char(10) int 整数型(最长11位) long 长整型 float 单精度 double 双精度 date 短日期,只包括年月日 datetime
-
Python处理键映射值操作详解
目录 1. 问题背景 2. collections 概述 2.1 什么是collections 2.2 Collections 内部结构 2.3 collections 使用方法 3. defaultdict 方法 setdefault(),对字典key值赋默认值 defaultdict(),对字典进行查找取值 4. Counter 方法 总结 作为一个学完Python基础知识的测试,暗喜终于可以像RD们自己写脚本处理任何场景吧,如何优雅地写出来代码,接下来开启进阶版的Python. 本期浅谈一
-
Python学习之字符串常用操作详解
目录 1.查找字符串 2.分割字符串 3.连接字符串 4.替换字符串 5.移除字符串的首尾字符 6.转换字符串的大小写 7.检测字符串(后续还会更新) 1.查找字符串 除了使用index()方法在字符串中查找指定元素,还可以使用find()方法在一个较长的字符串中查找子串.如果找到子串,返回子串所在位置的最左端索引,否则返回-1. 语法格式: str.find(sub[,start[,end]]) 其中,str表示被查找的字符串.sub表示查找的子串.start表示开始索引,缺省时为0.end表
-
python数据类型_字符串常用操作(详解)
这次主要介绍字符串常用操作方法及例子 1.python字符串 在python中声明一个字符串,通常有三种方法:在它的两边加上单引号.双引号或者三引号,如下: name = 'hello' name1 = "hello bei jing " name2 = '''hello shang hai haha''' python中的字符串一旦声明,是不能进行更改的,如下: #字符串为不可变变量,即不能通过对某一位置重新赋值改变内容 name = 'hello' name[0] = 'k' #通