Python多进程之进程同步及通信详解
目录
- 进程同步
- Lock(锁)
- 进程通信
- Queue(队列)
- Pipe(管道)
- Semaphore(信号量)
- Event(事件)
- 总结
上篇文章介绍了什么是进程、进程与程序的关系、进程的创建与使用、创建进程池等,接下来就来介绍一下进程同步及进程通信。
进程同步
当多个进程使用同一份数据资源的时候,因为进程的运行没有顺序,运行起来也无法控制,如果不加以干预,往往会引发数据安全或顺序混乱的问题,所以要在多个进程读写共享数据资源的时候加以适当的策略,来保证数据的一致性问题。
Lock(锁)
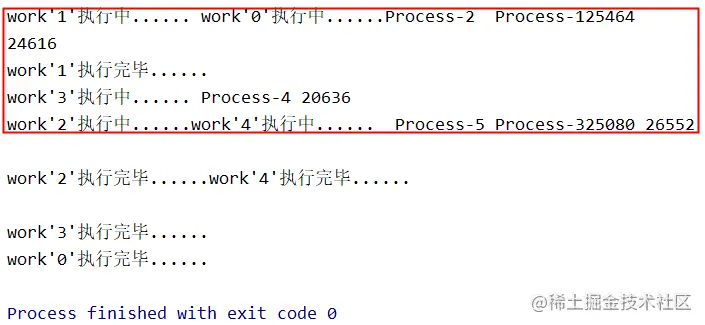
一个Lock对象有两个方法:acquire()和release()来控制共享数据的读写权限, 看下面这张图片,使用多进程的时候会经常出现这种情况,这是因为多个进程都在抢占输出资源,共享同一打印终端,从而造成了输出信息的错乱。
那么就可以使用Lock机制:
import multiprocessing
import random
import time
def work(lock, i):
lock.acquire()
print("work'{}'执行中......".format(i), multiprocessing.current_process().name, multiprocessing.current_process().pid)
time.sleep(random.randint(0, 2))
print("work'{}'执行完毕......".format(i))
lock.release()
if __name__ == '__main__':
lock = multiprocessing.Lock()
for i in range(5):
p = multiprocessing.Process(target=work, args=(lock, i))
p.start()
由于引入了Lock机制,同一时间只能有一个进程抢占到输出资源,其他进程等待该进程结束,锁释放到,才可以抢占,这样会解决多进程间资源竞争导致数据错乱的问题,但是由并发执行变成了串行执行,会牺牲运行效率。
进程通信
上篇文章说过,进程之间互相隔离,数据是独立的,默认情况下互不影响,那要如何实现进程间通信呢?Python提供了多种进程通信的方式,下面就来说一下。
Queue(队列)
multiprocessing模块提供的Queue多进程安全的消息队列,可以实现多进程之间的数据传递。
说明
- 初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最⼤可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头)。
Queue.qsize():返回当前队列包含的消息数量。Queue.empty():如果队列为空,返回True,反之False。Queue.full():如果队列满了,返回True,反之False。Queue.get(block, timeout):获取队列中的⼀条消息,然后将其从列队中移除,block默认值为True。如果block使⽤默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为⽌,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出Queue.Empty异常;如果block值为False,消息列队如果为空,则会⽴刻抛出Queue.Empty异常。Queue.get_nowait():相当Queue.get(False)。Queue.put(item, block, timeout):将item消息写⼊队列,block默认值为True,如果block使⽤默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写⼊,此时程序将被阻塞(停在写⼊状态),直到消息列队腾出空间为⽌,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出Queue.Full异常;如果block值为False,消息列队如果没有空间可写⼊,则会⽴刻抛出Queue.Full异常。Queue.put_nowait(item):相当于Queue.put(item, False)。
from multiprocessing import Process, Queue
import time
def write_task(queue):
"""
向队列中写入数据
:param queue: 队列
:return:
"""
for i in range(5):
if queue.full():
print("队列已满!")
message = "消息{}".format(str(i))
queue.put(message)
print("消息{}写入队列".format(str(i)))
def read_task(queue):
"""
从队列读取数据
:param queue: 队列
:return:
"""
while True:
print("从队列读取:{}".format(queue.get(True)))
if __name__ == '__main__':
print("主进程执行......")
# 主进程创建Queue,最大消息数量为3
queue = Queue(3)
pw = Process(target=write_task, args=(queue, ))
pr = Process(target=read_task, args=(queue, ))
pw.start()
pr.start()
运行结果为:

从结果我们可以看出,队列最大可以放入3条消息,后面再来消息,要等read_task从队列里取出后才行。
Pipe(管道)
Pipe常用于两个进程,两个进程分别位于管道的两端,Pipe(duplex)方法返回(conn1,conn2)代表一个管道的两端,duplex参数默认为True,即全双工模式,若为False,conn1只负责接收信息,conn2负责发送。
send()和recv()方法分别是发送和接受消息的方法。
import multiprocessing
import time
import random
def proc_send(pipe):
"""
发送消息
:param pipe:管道一端
:return:
"""
for i in range(10):
print("process send:{}".format(str(i)))
pipe.send(i)
time.sleep(random.random())
def proc_recv(pipe):
"""
接收消息
:param pipe:管道一端
:return:
"""
while True:
print("Process recv:{}".format(pipe.recv()))
time.sleep(random.random())
if __name__ == '__main__':
# 主进程创建pipe
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=proc_send,args=(pipe[0], ))
p2 = multiprocessing.Process(target=proc_recv,args=(pipe[1], ))
p1.start()
p2.start()
p1.join()
p2.terminate()
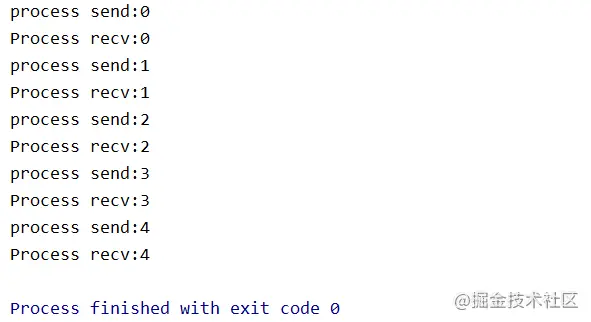
执行结果为:
Semaphore(信号量)
Semaphore用来控制对共享资源的访问数量,和进程池的最大连接数类似。
import multiprocessing
import random
import time
def work(s, i):
s.acquire()
print("work'{}'执行中......".format(i), multiprocessing.current_process().name, multiprocessing.current_process().pid)
time.sleep(i*2)
print("work'{}'执行完毕......".format(i))
s.release()
if __name__ == '__main__':
s = multiprocessing.Semaphore(2)
for i in range(1, 7):
p = multiprocessing.Process(target=work, args=(s, i))
p.start()
上面的代码中使用Semaphore限制了最多有2个进程同时执行,那么来一个进程获得一把锁,计数加1,当计数等于2时,后面再来的进程均需要等待,等前面的进程释放掉,才可以获得锁。
信号量与进程池的概念上类似,但是要区分开来,信号量涉及到加锁的概念。
Event(事件)
Event用来实现进程间同步通信的。运行的机制是:全局定义了一个flag,如果flag值为False,当程序执行event.wait()方法时就会阻塞,如果flag值为True时,程序执行event.wait()方法时不会阻塞继续执行。
Event常⽤函数:
event.wait():在进程中插入一个标记(flag),默认为False,可以设置timeout。event.set():使flag为Ture。event.clear():使flag为False。event.is_set():判断flag是否为True。
import multiprocessing
import time
def wait_for_event(e):
print("wait_for_event执行")
e.wait()
print("wait_for_event: e.is_set():{}".format(e.is_set()))
def wait_for_event_timeout(e, t):
print("wait_for_event_timeout执行")
# 只会阻塞2s
e.wait(t)
print("wait_for_event_timeout:e.is_set:{}".format(e.is_set()))
if __name__ == "__main__":
e = multiprocessing.Event()
p1 = multiprocessing.Process(target=wait_for_event, args=(e,))
p1.start()
p2 = multiprocessing.Process(target=wait_for_event_timeout, args=(e, 2))
p2.start()
time.sleep(4)
# 4s之后使用e.set()将flag设为Ture
e.set()
print("主进程:flag设置为True")
执行结果如下:

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
python实现多进程通信实例分析
操作系统会为每一个创建的进程分配一个独立的地址空间,不同进程的地址空间是完全隔离的,因此如果不加其他的措施,他们完全感觉不到彼此的存在.那么进程之间怎么进行通信?他们之间的关联是怎样的?实现原理是什么?本文就来借助Python简单的聊一下进程之间的通信?还是那句话,原理是相同的,希望能透过具体的例子来体会一下本质的东西. 下面尽量以简单的方式介绍一下每一类通信方式,具体的细节可以参照文档使用: 1. 管道 先来看一下最简单.古老的一种IPC:管道.通常指的是无名管道,本质上可以看做一种文件,只存
-
Python多进程同步Lock、Semaphore、Event实例
同步的方法基本与多线程相同. 1) Lock 当多个进程需要访问共享资源的时候,Lock可以用来避免访问的冲突. 复制代码 代码如下: import multiprocessing import sys def worker_with(lock, f): with lock: fs = open(f,"a+") fs.write('Lock acquired via with\n') fs.close() def
-
python多进程实现进程间通信实例
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程.Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情.借助这个包,可以轻松完成从单进程到并发执行的转换.multiprocessing支持子进程.通信和共享数据.执行不同形式的同步,提供了Process.Queue.Pipe.Lock等组件. multiprocessing.Queue() 以Queue为例,
-

python多进程间通信代码实例
这篇文章主要介绍了python多进程间通信代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里使用pipe代码如下: import time from multiprocessing import Process import multiprocessing class D: @staticmethod def test(pipe): while True: for i in range(10): pipe.send(i) time.s
-
Python多进程同步简单实现代码
本文讲述了Python多进程同步简单实现代码.分享给大家供大家参考,具体如下: #encoding=utf8 from multiprocessing import Process, Lock def func(lock, a): lock.acquire() print a lock.release() if __name__ == '__main__': lock = Lock() workers = [] # 创建两个进程 for i in range(0, 2): p = Process
-
python 多进程通信模块的简单实现
多进程通信方法好多,不一而数.刚才试python封装好嘅多进程通信模块 multiprocessing.connection. 简单测试咗一下,效率还可以,应该系对socket封装,效率可以达到4krps,可以满足好多方面嘅需求啦. 附代码如下: client 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*-""" download - slave"""__author__ = 'Zagfai
-
Python多进程通信Queue、Pipe、Value、Array实例
queue和pipe的区别: pipe用来在两个进程间通信.queue用来在多个进程间实现通信. 此两种方法为所有系统多进程通信的基本方法,几乎所有的语言都支持此两种方法. 1)Queue & JoinableQueue queue用来在进程间传递消息,任何可以pickle-able的对象都可以在加入到queue. multiprocessing.JoinableQueue 是 Queue的子类,增加了task_done()和join()方法. task_done()用来告诉queue一个tas
-
Python多进程之进程同步及通信详解
目录 进程同步 Lock(锁) 进程通信 Queue(队列) Pipe(管道) Semaphore(信号量) Event(事件) 总结 上篇文章介绍了什么是进程.进程与程序的关系.进程的创建与使用.创建进程池等,接下来就来介绍一下进程同步及进程通信. 进程同步 当多个进程使用同一份数据资源的时候,因为进程的运行没有顺序,运行起来也无法控制,如果不加以干预,往往会引发数据安全或顺序混乱的问题,所以要在多个进程读写共享数据资源的时候加以适当的策略,来保证数据的一致性问题. Lock(锁) 一个Loc
-
Python多进程并发(multiprocessing)用法实例详解
本文实例讲述了Python多进程并发(multiprocessing)用法.分享给大家供大家参考.具体分析如下: 由于Python设计的限制(我说的是咱们常用的CPython).最多只能用满1个CPU核心. Python提供了非常好用的多进程包multiprocessing,你只需要定义一个函数,Python会替你完成其他所有事情.借助这个包,可以轻松完成从单进程到并发执行的转换. 1.新建单一进程 如果我们新建少量进程,可以如下: import multiprocessing import t
-
python 多进程共享全局变量之Manager()详解
Manager支持的类型有 list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和Array. 但当使用Manager处理list.dict等可变数据类型时,需要注意一个陷阱,即Manager对象无法监测到它引用的可变对象值的修改,需要通过触发__setitem__方法来让它获得通知. 而触发__setitem__方法比较直接的办法就是增加一个中间变量,如同在C语言中交换两个变量
-
对Python的多进程锁的使用方法详解
很多时候,我们需要在多个进程中同时写一个文件,如果不加锁机制,就会导致写文件错乱 这个时候,我们可以使用multiprocessing.Lock() 我一开始是这样使用的: import multiprocessing lock = multiprocessing.Lock() class MatchProcess(multiprocessing.Process): def __init__(self, threadId, mfile, lock): multiprocessing.Proces
-
Python中协程用法代码详解
本文研究的主要是python中协程的相关问题,具体介绍如下. Num01–>协程的定义 协程,又称微线程,纤程.英文名Coroutine. 首先我们得知道协程是啥?协程其实可以认为是比线程更小的执行单元. 为啥说他是一个执行单元,因为他自带CPU上下文.这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程. 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的. Num02–>协程和线程的差异 那么这个过程看起来和线程差不多.其实不然, 线程切换从系统层面远不止保存和恢复 CP
-
基于python中的TCP及UDP(详解)
python中是通过套接字即socket来实现UDP及TCP通信的.有两种套接字面向连接的及无连接的,也就是TCP套接字及UDP套接字. TCP通信模型 创建TCP服务器 伪代码: ss = socket() # 创建服务器套接字 ss.bind() # 套接字与地址绑定 ss.listen() # 监听连接 inf_loop: # 服务器无限循环 cs = ss.accept() # 接受客户端连接 comm_loop: # 通信循环 cs.recv()/cs.send() # 对话(接收/发
-
python对于requests的封装方法详解
由于requests是http类接口的核心,因此封装前考虑问题比较多: 1. 对多种接口类型的支持: 2. 连接异常时能够重连: 3. 并发处理的选择: 4. 使用方便,容易维护: 当前并未全部实现,后期会不断完善.重点提一下并发处理的选择:python的并发处理机制由于存在GIL的原因,实现起来并不是很理想,综合考虑多进程.多线程.协程,在不考虑大并发性能测试的前提下使用了多线程-线程池的形式实现.使用的是 concurrent.futures模块.当前仅方便支持webservice接口. #
-
python爬虫泛滥的解决方法详解
我们可以把互联网上搬运数据的程序看成小蚂蚁,它们需要采集不同的食物带回洞里存储.但是大家也知道白蚁泛滥的事件,在我们的网络环境里,如果爬虫都集中在某几个位置,最直接的结果就是这个网站的拥挤.对于我们这些网站访问者而言也不是好事情,首先网页的页面会被卡住.网站的管理人员面对爬虫过多,这时候就要进行一系列的限制措施了,这里小编分了两个大的应对方向,从不同的角度进 行分析爬虫过多的解决思路. 一.识别爬虫 1. HTTP请求头 这算是最基础的网络爬虫识别了,正常的网络访问者都是通过浏览器对网站进行访问
-
Python的信号库Blinker用法详解
作为一个信号库,使用时候是支持一对一以及一对多的订阅模式,可以实现发送数据等,一般情况下,只要能够使用到Blinker的,一般都是应用在技术设计以及垃圾回收上等等,以上就是关于Blinker库的基本信息,具体的情况,小编将详细的为大家介绍讲解,好啦一起来了解看下吧. 安装环境: Python 3.6.4 安装方式: pip install blinker 使用实例: In [1]: from blinker import signal In [2]: a = signal('signal_tes
-
Python进度条tqdm的用法详解
前言 有时候在使用Python处理比较耗时操作的时候,为了便于观察处理进度,这时候就需要通过进度条将处理情况进行可视化展示,以便我们能够及时了解情况.这对于第三方库非常丰富的Python来说,想要实现这一功能并不是什么难事. tqdm就能非常完美的支持和解决这些问题,可以实时输出处理进度而且占用的CPU资源非常少,支持windows.Linux.mac等系统,支持循环处理.多进程.递归处理.还可以结合linux的命令来查看处理情况,等进度展示. 大家先看看tqdm的进度条效果: tqdm安装: