pgsql之pg_stat_replication的使用详解
pg_stat_replication是一个视图,主要用于监控一个基于流的设置,建议您 注意系统上称作pg_stat_replication的视图。(注:当前版本为pg 10.0,10.0以下版本,字段名会有差异)此视图包含以下信息:
\d pg_stat_replication
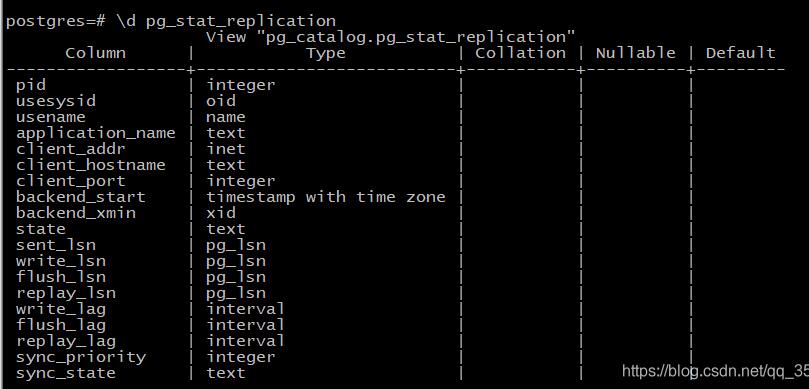
每个字段代码的含义:
• pid 这代表负责流连接的wal_sender进程的进程ID。如果您在您的操作系统上检查您进程表,您应该会找到一个带有那个号码的PostgreSQL进程。
• usesysid 每个内部用户都有一个独一无二的编号。该系统的工作原理很像UNIX。 usesysid 是 (PostgreSQL) 用户连接到系统的唯一标识符。
• usename (不是用户名, 注意少了 r)它存储与用户相关的 usesysid 的名字。这是客户端放入到连接字符串中的东西。
• application_name这是同步复制的通常设置。它可以通过连接字符串传递到master。
• client_addr它会告诉您流连接从何而来。它拥有客户端的IP地址。
• client_hostname除了客户端的IP,您还可以这样做,通过它的主机名来标识客户端。您可以通过master上的postgresql.conf中的log_hostname启用DNS反向查找。
• client_port这是客户端用来和WALsender进行通信使用的TPC端口号。 如果不本地UNIX套接字被使用了将显示-1。
• backend_start它告诉我们slave什么时间创建了流连接。
• state此列告诉我们数据的连接状态。如果事情按计划进行,它应该包含流信息。
• sent_lsn这代表发送到连接的最后的事务日志的位置。
• write_lsn这是写到standby系统磁盘上最后的事务日志位置。
• flush_lsn这是被刷新到standby系统的最后位置。(这里注意写和刷新之间的区别。写并不意味着刷新 。)
• replay_lsn这是slave上重放的最后的事务日志位置。
• sync_priority这个字段是唯一和同步复制相关的。每次同步复制将会选择一个优先权 —sync_priority—会告诉您选择了那个优先权。
• sync_state最后您会看到slave在哪个状态。这个状态可以是
async, sync, or potential。当有一个带有较高优先权的同步slave时,PostgreSQL会把slave 标记为 potential。
在这个系统视图中每个记录只代表一个slave。因此,可以看到谁处于连接状态,在做什么任务。pg_stat_replication也是检查slave是否处于连接状态的一个好方法。
上面说到pid代表负责流连接的wal_sender进程的进程ID,我们在机器上通过ps命令查看该进程的状态:
ps -aux|grep 8225

在Linux上我们可以看到那个进程不仅有自己的作用 (在这种情况下, wal_sender),而且还带有终端用户的名字以及相关的网络连接信息。在上图中我们可以看到已经有人从192.168.47.127(对应pg_stat_replication的client_addr字段)通过51519(对应pg_stat_replication的client_port字段))端口连接到了master。
bonus:
上面我们提到replay_lsn是slave上重放的最后的事务日志位置。
pg_current_wal_lsn()函数的作用是获取当前的wal log的写位置。
pg_wal_lsn_diff()函数的作用是计算两个wal日志之间的差距。
所以我们可以通过下面的方法获取高可用架构下从库的复制延迟情况:
SELECT pg_wal_lsn_diff(A .c1, replay_lsn) /(1024 * 1024) AS slave_latency_MB FROM pg_stat_replication, pg_current_wal_lsn() AS A(c1) WHERE client_addr='%s' and application_name = '%s' ORDER BY slave_latency_MB LIMIT 1;
补充:PostgreSQL pg_stat_replication sync_state introduce
PostgreSQL 9.2引入同步复制后, pg_stat_replication的sync_state列有3种状态.
sync
async
potential
分别代表同步standby, 异步standby, 可升级为同步的standby.
状态来自以下函数 : pg_stat_get_wal_senders
[测试]
环境:
1个 primary, 3个 standby.
第一种配置 :
primary配置
postgresql.conf synchronous_standby_names = 'test1,test2,test3'
standby1配置
primary_conninfo = 'application_name=test1 host=127.0.0.1 port=1999 user=postgres keepalives_idle=60'
standby2配置
primary_conninfo = 'application_name=test2 host=127.0.0.1 port=1999 user=postgres keepalives_idle=60'
standby3配置
primary_conninfo = 'application_name=test3 host=127.0.0.1 port=1999 user=postgres keepalives_idle=60'
primary查询
digoal=# select pid,application_name,client_addr,sync_state from pg_stat_replication; pid | application_name | client_addr | sync_state ------+------------------+-------------+------------ 6311 | test1 | 127.0.0.1 | sync 6321 | test2 | 127.0.0.1 | potential 6391 | test3 | 127.0.0.1 | potential (3 rows)
如果sync节点挂掉, 按synchronous_standby_names的顺序, 第一个potential节点会变成sync状态.
pg_ctl stop -m fast -D /pgdata11999 digoal=# select pid,application_name,client_addr,sync_state from pg_stat_replication; pid | application_name | client_addr | sync_state ------+------------------+-------------+------------ 6564 | test2 | 127.0.0.1 | sync 6568 | test3 | 127.0.0.1 | potential (2 rows)
当test1重新起来后又会变成sync状态.
pg93@db-172-16-3-33-> pg_ctl start -D /pgdata11999 server starting digoal=# select pid,application_name,client_addr,sync_state from pg_stat_replication; pid | application_name | client_addr | sync_state ------+------------------+-------------+------------ 6564 | test2 | 127.0.0.1 | potential 6605 | test1 | 127.0.0.1 | sync 6568 | test3 | 127.0.0.1 | potential (3 rows)
第二种配置 :
primary配置
synchronous_standby_names = 'test1,test2'
standby1配置不变
standby2配置不变
standby3配置不变
primary查询
digoal=# select pid,application_name,client_addr,sync_state from pg_stat_replication; pid | application_name | client_addr | sync_state ------+------------------+-------------+------------ 6470 | test1 | 127.0.0.1 | sync 6472 | test3 | 127.0.0.1 | async 6474 | test2 | 127.0.0.1 | potential (3 rows)
test3变成异步了. 因为test3没有配置在primary的synchronous_standby_names 中.
第三种配置 :
primary配置
synchronous_standby_names = 'test1'
standby1配置不变
standby2配置不变
standby3配置不变
primary查询
digoal=# select pid,application_name,client_addr,sync_state from pg_stat_replication; pid | application_name | client_addr | sync_state ------+------------------+-------------+------------ 6519 | test2 | 127.0.0.1 | async 6521 | test3 | 127.0.0.1 | async 6523 | test1 | 127.0.0.1 | sync (3 rows)
test2,test3变成异步了. 因为test2,test3没有配置在primary的synchronous_standby_names 中.
1. src/backend/replication/walsender.c
/*
* Returns activity of walsenders, including pids and xlog locations sent to
* standby servers.
*/
Datum
pg_stat_get_wal_senders(PG_FUNCTION_ARGS)
{
...略
/*
* More easily understood version of standby state. This is purely
* informational, not different from priority.
*/
if (sync_priority[i] == 0)
values[7] = CStringGetTextDatum("async");
else if (i == sync_standby)
values[7] = CStringGetTextDatum("sync");
else
values[7] = CStringGetTextDatum("potential");
...略
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

pgsql批量修改sequences的start方式
修改为指定值 DO $$DECLARE r record; BEGIN FOR r IN SELECT sequence_name FROM information_schema."sequences" LOOP EXECUTE 'ALTER SEQUENCE '|| r.sequence_name ||' restart WITH 10000'; END LOOP; END$$; 根据表的id修改 DO $$ DECLARE r record; start_value integer
-
pgsql 如何删除仍有活动链接的数据库
删除数据库的命令: drop database if exists testdb; 但是这个命令可能会报错: 类似于: database "xxx" is being accessed by other users. DETAIL: There is x other session using database. 如: 表示要删除的数据库上还有其他活动链接. 解决方法: 断开该数据库上所有链接. sql: select pg_terminate_backend(pid) from pg
-
pgsql锁表后kill进程的操作
如下: select * from pg_stat_activity 查询系统中的进程 如果怀疑哪张表被锁了,可以执行如下sql: select oid from pg_class where relname='table_name' 然后将拿到的oid 放入如下sql执行: select pg_cancel_backend('oid '):: 搞定! 此sql是kill作用 补充:PostgreSQL - 如何杀死被锁死的进程 前言 在一次系统迭代后用户投诉说无法成功登陆系统,经过测试重现和日
-
PGSQL 实现把字符串转换成double类型(to_number())
今天写sql的时候,发现PG里有一张表的面积字段竟然设置成字符串类型,这样就不能统计使用sum函数了,所以需要将字符串转换成double类型再相加. select sum(to_number(mj,9999.99)) as amountmj from table group by area 其中9999.99就是不管是mj字段的值还是amountmj的值不能超过9999.99,且保留两位小数. 补充:postgresql科学计数法转浮点或字符串 科学计数法转浮点 select '2.93985E
-
pgsql添加自增序列、设置表某个字段自增操作
添加自增序列 CREATE SEQUENCE 表名_id_seq START WITH 1 INCREMENT BY 1 NO MINVALUE NO MAXVALUE CACHE 1; 设置表某个字段自增 alter table表名 alter column id set default nextval('表名_id_seq'); 从当前最大id依次递增 select setval('表名_id_seq',(select max(id) from 同一个表名)); 大写字符的表需要加双引号.例
-
pgsql 实现用户自定义表结构信息获取
1. 获取表中普通信息:如字段名,字段类型等 SELECT column_name, data_type, ordinal_position, is_nullable FROM information_schema."columns" WHERE "table_name"='TABLE-NAME' -- 将 'TABLE-NAME' 换成自己的表 2.获取所有的表和视图 SELECT table_name, table_type FROM INFORMATION_S
-
pgsql的UUID生成函数实例
– pgsql – 安装函数 – UUID生成函数: pgsql默认安装是没有该类函数的,若脚本执行到此处出错,需打开下面注释,安装UUID生成函数 create extension "uuid-ossp" ; – 使用函数 select uuid_generate_v4(); select replace(cast(uuid_generate_v4() as VARCHAR), '-', ''); select translate(cast(uuid_generate_v4() as
-
pgsql 如何手动触发归档
方法: pg10.0之前: select pg_switch_xlog(); pg10.0之后: select pg_switch_wal(); 备注:执行 pg_switch_xlog() 后,WAL 会切换到新的日志,这时会将老的 WAL日志归档. 除了手动触发归档,还有什么情况下,pg会进行归档? 两种情况: ①WAL 日志写满后触发归档. wal日志被写满后会触发归档,wal日志默认是16MB,这个值可以在编译PostgreSQL时通过参数"--with-wal-segsize"
-
PGSQL实现判断一个空值字段,并将NULL值修改为其它值
在使用pgsql时,想要取到某些字段不为空或者为空的数据,可以用以下方法: 1.不为空 Select * From table Where id<>'' Select * From table Where id!='' 2.为空 Select * From table Where id='' Select * From table Where ISNULL(id) 如果字段是类型是字符串,用 id=''可以;如果是int型则用 ISNULL 如果需要将空值设置为其它值: select COAL
-
pgsql之pg_stat_replication的使用详解
pg_stat_replication是一个视图,主要用于监控一个基于流的设置,建议您 注意系统上称作pg_stat_replication的视图.(注:当前版本为pg 10.0,10.0以下版本,字段名会有差异)此视图包含以下信息: \d pg_stat_replication 每个字段代码的含义: • pid 这代表负责流连接的wal_sender进程的进程ID.如果您在您的操作系统上检查您进程表,您应该会找到一个带有那个号码的PostgreSQL进程. • usesysid 每个内部用户都
-
PostgreSQL使用MySQL外表的步骤详解(mysql_fdw)
浅谈 postgres不知不觉已经升到了版本13,记得两年前还是版本10,当然这中间一直期望着哪天能在项目中使用postgresql,现在已实现哈-: 顺带说一下:使用postgresql的原因是它的生态完整,还有一个很重要的点儿是速度快这个在第10版的时 这么说也许还为时过早, 但是在13这一版本下一点儿也不为过,真的太快了,我简单的用500w的数据做聚合,在不建立索引(主键除外)的情况下 执行一个聚合操作,postgres 的速度是mysql的8倍,真的太快了-:好了,这一章节我就聊一聊我实
-
开源数据库postgreSQL13在麒麟v10sp1源码安装过程详解
一.中标麒麟v10sp1在飞腾2000+系统安装略 二.系统依赖包安装 [root@ft2000db opt]# yum install bzip* [root@ft2000db opt]# nkvers ############## Kylin Linux Version ################# Release: Kylin Linux Advanced Server release V10 (Tercel) Kernel: 4.19.90-17.ky10.aarch64 Buil
-
Go逃逸分析示例详解
目录 引言大纲 逃逸分析 内存管理 栈 堆 堆和栈的对比 加锁 性能 缓存策略 逃逸分析优势 逃逸分析原则 逃逸分析举例 1.参数是interface类型 2. 变量在函数外部有引用 3. 变量内存占用较大 4. 变量大小不确定时 思考题 总结 引言大纲 这个月我会整理分享一系列后端工程师求职面试相关的文章,知识脉络图如下: JAVA/GO/PHP 面试常问的知识点 DB:MySql PgSql Cache: Redis MemCache MongoDB 数据结构 算法 微服务&高并发 流媒体
-
PostgreSQL 数组类型操作使用及特点详解
目录 PostgreSQL 数组类型使用详解 下面列出一些PostgreSQL的特点 数组类型的基本操作 1 查询 2 插入数据 3 条件查询 4 更新 4.1 更新标签的名称 4.2 添加一个标签 5 删除 总结 PostgreSQL 数组类型使用详解 可能大家对 PostgreSQL这个关系型数据库不太熟悉,因为大部分人最熟悉的,公司用的最多的是 MySQL 我们先对PostgreSQL数据库 (下面简称 PG)简单的介绍一下,以后有机会,再单独写一篇专门介绍pgSql的文章 The Wor
-
Cython处理C字符串的示例详解
目录 楔子 创建 C 字符串 引用计数陷阱 strlen strcpy strcat strcmp sprintf 动态申请字符串内存 memset memcpy memmove memcmp 小结 楔子 在介绍数据类型的时候我们说过,Python 的数据类型相比 C 来说要更加的通用,但速度却远不及 C.如果你在使用 Cython 加速 Python 时遇到了瓶颈,但还希望更进一步,那么可以考虑将数据的类型替换成 C 的类型,特别是那些频繁出现的数据,比如整数.浮点数.字符串. 由于整数和浮点
-
AngularJS 日期格式化详解
AngularJS是为了克服HTML在构建应用上的不足而设计的.HTML是一门很好的为静态文本展示设计的声明式语言,但要构建WEB应用的话它就显得乏力了.所以我做了一些工作(你也可以觉得是小花招)来让浏览器做我想要的事. AngularJS的日期格式化有两种形式,一种是在HTML页面,一种是在JS代码里,都是用到AngularJS的过滤器$filter. HTML: date_expression 即 你在$scope中设的date类型变量(注意,一定是date object才正确), 也是要显
-
spring boot的maven配置依赖详解
本文介绍了spring boot的maven配置依赖详解,分享给大家,具体如下: 我们通过引用spring-boot-starter-parent,添加spring-boot-starter-web 可以实现web项目的功能,当然不使用spring-boot-start-web,通过自己添加的依赖包也可以实现,但是需要一个个添加,费时费力,而且可能产生版本依赖冲突.我们来看下springboot的依赖配置: 利用pom的继承,一处声明,处处使用.在最顶级的spring-boot-dependen
-
基于ES6作用域和解构赋值详解
ES6 强制开启严格模式 作用域 •var 声明局部变量,for/if花括号中定义的变量在花括号外也可访问 •let 声明的变量为块作用域,变量不可重复定义 •const 声明常量,块作用域,声明时必须赋值,不可修改 // const声明的k指向一个对象,k本身不可变,但对象可变 function test() { const k={ a:1 } k.b=3; console.log(k); } test()解构赋值 { let a, b, 3, rest; [a, b, c=3]=[1, 2]
-
[译]ASP.NET Core 2.0 路由引擎详解
本文介绍了ASP.NET Core 2.0 路由引擎详解,分享给大家,具体如下: 问题 ASP.NET Core 2.0的路由引擎是如何工作的? 答案 创建一个空项目,为Startup类添加MVC服务和请求中间件: public void ConfigureServices(IServiceCollection services) { services.AddMvc(); } public void Configure(IApplicationBuilder app, IHostingEnvir