python 中文乱码问题深入分析
在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下:
1. UNICODE (UTF8-16),C854;
2. UTF-8,E59388;
3. GBK,B9FE。
一、python中的str和unicode
一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为
u'\u54c8\u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果你想使这个字节流显示的内容有意义,就必须用正确的编码格式,解码显示。
例如: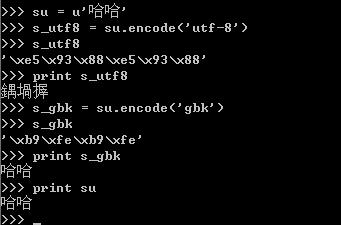
对于unicode对象哈哈进行编码,编码成一个utf-8编码的str-s_utf8,s_utf8就是是一个字节数组,存放的就是'\xe5\x93\x88\xe5\x93\x88',但是这仅仅是一个字节数组,如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?
因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据系统的编码对输入的字节流进行编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 '\xe5\x93\x88\xe5\x93\x88'用GB2312去解释,其显示的出来就是“鍝堝搱”。这里再强调一下,str记录的是字节数组,只是某种编码的存储格式,至于输出到文件或是打印出来是什么格式,完全取决于其解码的编码将它解码成什么样子。
这里再对print进行一点补充说明:当将一个unicode对象传给print时,在内部会将该unicode对象进行一次转换,转换成本地的默认编码(这仅是个人猜测)
二、str和unicode对象的转换
str和unicode对象的转换,通过encode和decode实现,具体使用如下:
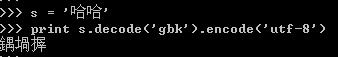
将GBK'哈哈'转换成unicode,然后再转换成UTF8
三、Setdefaultencoding
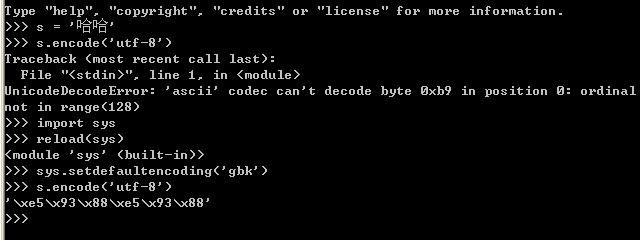
如上图的演示代码所示:
当把s(gbk字符串)直接编码成utf-8的时候,将抛出异常,但是通过调用如下代码:
import sys
reload(sys)
sys.setdefaultencoding('gbk')
后就可以转换成功,为什么呢?在python中str和unicode在编码和解码过程中,如果将一个str直接编码成另一种编码,会先把str解码成unicode,采用的编码为默认编码,一般默认编码是anscii,所以在上面示例代码中第一次转换的时候会出错,当设定当前默认编码为'gbk'后,就不会出错了。
至于reload(sys)是因为Python2.5 初始化后会删除 sys.setdefaultencoding 这个方法,我们需要重新载入。
四、操作不同文件的编码格式的文件
建立一个文件test.txt,文件格式用ANSI,内容为:
abc中文
用python来读取
# coding=gbk
print open("Test.txt").read()
结果:abc中文
把文件格式改成UTF-8:
结果:abc涓枃
显然,这里需要解码:
# coding=gbk
import codecs
print open("Test.txt").read().decode("utf-8")
结果:abc中文
上面的test.txt我是用Editplus来编辑的,但当我用Windows自带的记事本编辑并存成UTF-8格式时,
运行时报错:
Traceback (most recent call last):
File "ChineseTest.py", line 3, in
print open("Test.txt").read().decode("utf-8")
UnicodeEncodeError: 'gbk' codec can't encode character u'\ufeff' in position 0: illegal multibyte sequence
原来,某些软件,如notepad,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。
因此我们在读取时需要自己去掉这些字符,python中的codecs module定义了这个常量:
# coding=gbk
import codecs
data = open("Test.txt").read()
if data[:3] == codecs.BOM_UTF8:
data = data[3:]
print data.decode("utf-8")
结果:abc中文
五、文件的编码格式和编码声明的作用
源文件的编码格式对字符串的声明有什么作用呢?这个问题困扰一直困扰了我好久,现在终于有点眉目了,文件的编码格式决定了在该源文件中声明的字符串的编码格式,例如:
str = '哈哈'
print repr(str)
a.如果文件格式为utf-8,则str的值为:'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码)
b.如果文件格式为gbk,则str的值为:'\xb9\xfe\xb9\xfe'(哈哈的gbk编码)
在第一节已经说过,python中的字符串,只是一个字节数组,所以当把a情况的str输出到gbk编码的控制台时,就将显示为乱码:鍝堝搱;而当把b情况下的str输出utf-8编码的控制台时,也将显示乱码的问题,是什么也没有,也许'\xb9\xfe\xb9\xfe'用utf-8解码显示,就是空白吧。>_<
说完文件格式,现在来谈谈编码声明的作用吧,每个文件在最上面的地方,都会用# coding=gbk 类似的语句声明一下编码,但是这个声明到底有什么用呢?到止前为止,我觉得它的作用也就是三个:
- 声明源文件中将出现非ascii编码,通常也就是中文;
- 在高级的IDE中,IDE会将你的文件格式保存成你指定编码格式。
- 决定源码中类似于u'哈'这类声明的将‘哈'解码成unicode所用的编码格式,也是一个比较容易让人迷惑的地方,看示例:
#coding:gbk
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个些代码保存成一个utf-8文本,运行,你认为会输出什么呢?大家第一感觉肯定输出的肯定是:
u'\u54c8\u54c8'
ss:哈哈
但是实际上输出是:
u'\u935d\u581d\u6431'
ss:鍝堝搱
为什么会这样,这时候,就是编码声明在作怪了,在运行ss = u'哈哈'的时候,整个过程可以分为以下几步:
1) 获取'哈哈'的编码:由文件编码格式确定,为'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码形式)
2) 转成 unicode编码的时候,在这个转换的过程中,对于'\xe5\x93\x88\xe5\x93\x88'的解码,不是用utf-8解码,而是用声明编码处指定的编码GBK,将'\xe5\x93\x88\xe5\x93\x88'按GBK解码,得到就是''鍝堝搱'',这三个字的unicode编码就是u'\u935d\u581d\u6431',至止可以解释为什么print repr(ss)输出的是u'\u935d\u581d\u6431' 了。
好了,这里有点绕,我们来分析下一个示例:
#-*- coding:utf-8 -*-
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个示例这次保存成GBK编码形式,运行结果,竟然是:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xb9 in position 0: unexpected code byte
这里为什么会有utf8解码错误呢?想想上个示例也明白了,转换第一步,因为文件编码是GBK,得到的是'哈哈'编码是GBK的编码'\xb9\xfe\xb9\xfe',当进行第二步,转换成 unicode的时候,会用UTF8对'\xb9\xfe\xb9\xfe'进行解码,而大家查utf-8的编码表会发现,utf8编码表(关于UTF- 8解释可参见字符编码笔记:ASCII、UTF-8、UNICODE)中根本不存在,所以会报上述错误。
相关推荐
-
python操作mysql中文显示乱码的解决方法
本文实例展示了一个脚本python用来转化表配置数据xml并生成相应的解析代码. 但是在中文编码上出现了乱码,现将解决方法分享出来供大家参考. 具体方法如下: 1. Python文件设置编码 utf-8 (文件前面加上 #encoding=utf-8) 2. MySQL数据库charset=utf-8 3. Python连接MySQL是加上参数 charset=utf8 4. 设置Python的默认编码为 utf-8 (sys.setdefaultencoding(utf-8) 示例代码如下:
-
Python字符串的encode与decode研究心得乱码问题解决方法
为什么会报错"UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)"?本文就来研究一下这个问题. 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码. decode的作用
-
python中urllib.unquote乱码的原因与解决方法
发现问题 Python中的urllib模块用来处理url相关的操作,unquote方法对应javascript中的urldecode方法,它对url进行解码,把类似"%xx"的字符替换成单个字符,例如:"%E6%B3%95%E5%9B%BD%E7%BA%A2%E9%85%92"解码后会转换成"法国红酒",但是使用过程中,如果姿势不对,最终转换出来的字符会是乱码"法国红é-". 笔者在一个真实的Tornado应用中就
-
python中文乱码的解决方法
乱码原因:源码文件的编码格式为utf-8,但是window的本地默认编码是gbk,所以在控制台直接打印utf-8的字符串当然是乱码了! 解决方法:1.print mystr.decode('utf-8').encode('gbk')2.比较通用的方法: 复制代码 代码如下: import systype = sys.getfilesystemencoding()print mystr.decode('utf-8').encode(type)
-
彻底搞懂 python 中文乱码问题(深入分析)
前言 曾几何时 Python 中文乱码的问题困扰了我很多很多年,每次出现中文乱码都要去网上搜索答案,虽然解决了当时遇到的问题但下次出现乱码的时候又会懵逼,究其原因还是知其然不知其所以然.现在有的小伙伴为了躲避中文乱码的问题甚至代码中不使用中文,注释和提示都用英文,我曾经也这样干过,但这并不是解决问题,而是逃避问题,今天我们一起彻底解决 Python 中文乱码的问题. 基础知识ASCII 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关
-

python 中文乱码问题深入分析
在本文中,以'哈'来解释作示例解释所有的问题,"哈"的各种编码如下: 1. UNICODE (UTF8-16),C854: 2. UTF-8,E59388: 3. GBK,B9FE. 一.python中的str和unicode 一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢? 在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为 u'\u54c8
-
python中文乱码不着急,先看懂字节和字符
Python2.x使用过程中,中文乱码解决最耳熟能详的方法就是在代码前加上#-*- coding:utf-8 –*- 那么为什么需要这么做呢?什么又是字节和字符?下面我们了解下. 我来讲一下字符问题我的理解吧,虽然我对Python的编码处理的具体细节还不太清楚,不过临时稍微看了一下,和Perl的原理也差不多 最重要的是必须区分"字符"和"字节"的不同,"字符"是抽象的,而"字节"是具体的 比如一个"中"字,
-
解决c++调用python中文乱码问题
windows中文操作系统下,vs的c++项目默认编码是GB2312 python默认是utf-8编码 最好在c++程序顶上加: #pragma execution_character_set("GB2312") c++中的字符串一定就是gbk编码 传入python前要做编码转换 准备一个gbk转utf8的函数,如下(网上的): string GbkToUtf8(const char* src_str) { int len = MultiByteToWideChar(CP_ACP, 0
-
解决python中文乱码问题方法总结
在运行这样类似的代码: #!/usr/bin/env pythons="中文"print s 最近经常遇到这样的问题: 问题一: SyntaxError: Non-ASCII character '\xe4' in file E:\coding\python\Untitled 6.py on line 3, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details 问题二: Un
-
linux下python中文乱码解决方案详解
1. 场景描述 linux服务器下安装了Anaconda3,执行Pyhton的K-means算法,结果出现如下图的中文字符乱码.上次已经解决了,忘记记录解决流程了,这次配置了一台新的服务器,又出现,默认不配置的话matplotlib画图就会乱码,这次把解决过程记录下,希望能帮助自己和有需要的朋友. 2. 解决方案 网上有好几个解决方案,只介绍自己实战可行的. 1. 查看matplotlib字体位置 python import matplotlib print(matplotlib.matplot
-
布同 Python中文问题解决方法(总结了多位前人经验,初学者必看)
因为Python是自带文档,可以通过help函数来查询每一个系统函数的用法解释说明.一般来说,关键的使用方法和注意点在这个系统的文档中都说的很清楚.我试图在网上找过系统文档的中文版的函数功能解释,但是都没有找到,所以我决定将就使用英文版的系统自带的函数解释来学习. 如果你想进行Tkinter和wxPython编程,想要知道一般的widget的使用方法和属性介绍,英文又不是太好的话,我推荐你,你可以去看看<Python与Tkinter编程>这本书,里面392页到538页的附录B和附录C选择了常用
-
解决Python2.7读写文件中的中文乱码问题
Python2.7对于中文编码的问题处理的并不好,这几天在爬数据的时候经常会遇到中文的编码问题.但是本人对编码原理不了解,也没时间深究其中的原理.在此仅从应用的角度做一下总结, 1.设置默认编码 在Python代码中的任何地方出现中文,编译时都会报错,这时可以在代码的首行添加相应说明,明确utf-8编码格式,可以解决一般情况下的中文报错.当然,编程中遇到具体问题还需具体分析啦. #encoding:utf-8 或者 # -*- coding: utf-8 -*- import sys reloa
-
解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点.最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码.看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病.这不,刚刚一解决就将这个方法公布与众,大家一同分享. 首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicod