MYSQL开发性能研究之批量插入数据的优化方法
一、我们遇到了什么问题
在标准SQL里面,我们通常会写下如下的SQL insert语句。
INSERT INTO TBL_TEST (id) VALUES(1);
很显然,在MYSQL中,这样的方式也是可行的。但是当我们需要批量插入数据的时候,这样的语句却会出现性能问题。例如说,如果有需要插入100000条数据,那么就需要有100000条insert语句,每一句都需要提交到关系引擎那里去解析,优化,然后才能够到达存储引擎做真的插入工作。
正是由于性能的瓶颈问题,MYSQL官方文档也就提到了使用批量化插入的方式,也就是在一句INSERT语句里面插入多个值。即,
INSERT INTO TBL_TEST (id) VALUES (1), (2), (3)
这样的做法确实也可以起到加速批量插入的功效,原因也不难理解,由于提交到服务器的INSERT语句少了,网络负载少了,最主要的是解析和优化的时间看似增多,但是实际上作用的数据行却实打实地多了。所以整体性能得以提高。根据网上的一些说法,这种方法可以提高几十倍。
然而,我在网上也看到过另外的几种方法,比如说预处理SQL,比如说批量提交。那么这些方法的性能到底如何?本文就会对这些方法做一个比较。
二、比较环境和方法
我的环境比较苦逼,基本上就是一个落后的虚拟机。只有2核,内存为6G。操作系统是SUSI Linux,MYSQL版本是5.6.15。
可以想见,这个机子的性能导致了我的TPS一定非常低,所以下面的所有数据都是没有意义的,但是趋势却不同,它可以看出整个插入的性能走向。
由于业务特点,我们所使用的表非常大,共有195个字段,且写满(每个字段全部填满,包括varchar)大致会有略小于4KB的大小,而通常来说,一条记录的大小也有3KB。
由于根据我们的实际经验,我们很肯定的是,通过在一个事务中提交大量INSERT语句可以大幅度提高性能。所以下面的所有测试都是建立在每插入5000条记录提交一次的做法之上。
最后需要说明的是,下面所有的测试都是通过使用MYSQL C API进行的,并且使用的是INNODB存储引擎。
三、比较方法
理想型测试(一)——方法比较
目的:找出理想情况下最合适的插入机制
关键方法:
1. 每个进/线程按主键顺序插入
2. 比较不同的插入方法
3. 比较不同进/线程数量对插入的影响
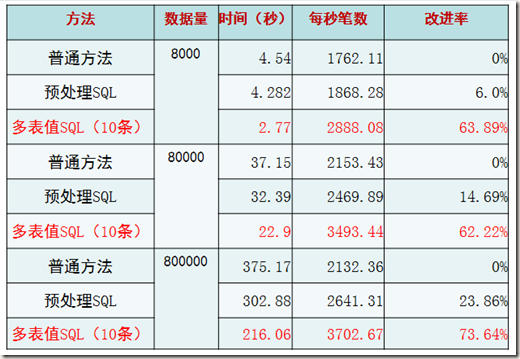
*“普通方法”指的是一句INSERT只插入一个VALUE的情况。
*“预处理SQL”指的是使用预处理MYSQL C API的情况。
* “多表值SQL(10条)”是使用一句INSERT语句插入10条记录的情况。为什么是10条?后面的验证告诉了我们这样做性能最高。
结论,很显然,从三种方法的趋势上来看,多表值SQL(10条)的方式最为高效。
理想型测试(二)——多表值SQL条数比较
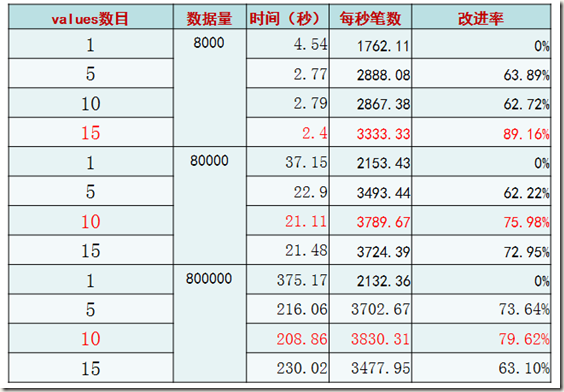
很显然,在数据量提高的情况下,每条INSERT语句插入10条记录的做法最为高效。
理想型测试(三)——连接数比较


结论:在2倍与CPU核数的连接和操作的时候,性能最高
一般性测试—— 根据我们的业务量进行测试
目的:最佳插入机制适合普通交易情况?
关键方法:
1. 模拟生产数据(每条记录约3KB)
2. 每个线程主键乱序插入

很显然,如果是根据主键乱序插入的话,性能会有直线下降的情况。这一点其实和INNODB的内部实现原理所展现出来的现象一致。但是仍然可以肯定的是,多表值SQL(10条)的情况是最佳的。
压力测试
目的:最佳插入机制适合极端交易情况?
关键方法:
1. 将数据行的每一个字段填满(每条记录约为4KB)
2. 每个线程主键乱序插入
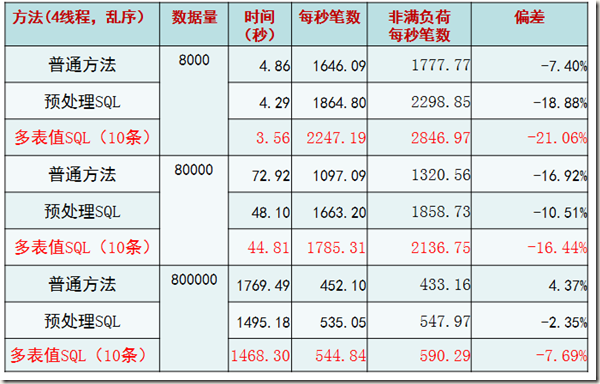
结果和我们之前的规律类似,性能出现了极端下降。并且这里验证了随着记录的增大(可能已经超过了一个page的大小,毕竟还有slot和page head信息占据空间),会有page split等现象,性能会下降。
四、结论
根据上面的测试,以及我们对INNODB的了解,我们可以得到如下的结论。
•采用顺序主键策略(例如自增主键,或者修改业务逻辑,让插入的记录尽可能顺序主键)
•采用多值表(10条)插入方式最为合适
•将进程/线程数控制在2倍CPU数目相对合适
五、附录
我发现网上很少有完整的针对MYSQL 预处理SQL语句的例子。这里给出一个简单的例子。
--建表语句 CREATE TABLE tbl_test ( pri_key varchar(30), nor_char char(30), max_num DECIMAL(8,0), long_num DECIMAL(12, 0), rec_upd_ts TIMESTAMP );
c代码
#include <string.h>
#include <iostream>
#include <mysql.h>
#include <sys/time.h>
#include <sstream>
#include <vector>
using namespace std;
#define STRING_LEN 30
char pri_key [STRING_LEN]= "123456";
char nor_char [STRING_LEN]= "abcabc";
char rec_upd_ts [STRING_LEN]= "NOW()";
bool SubTimeval(timeval &result, timeval &begin, timeval &end)
{
if ( begin.tv_sec>end.tv_sec ) return false;
if ( (begin.tv_sec == end.tv_sec) && (begin.tv_usec > end.tv_usec) )
return false;
result.tv_sec = ( end.tv_sec - begin.tv_sec );
result.tv_usec = ( end.tv_usec - begin.tv_usec );
if (result.tv_usec<0) {
result.tv_sec--;
result.tv_usec+=1000000;}
return true;
}
int main(int argc, char ** argv)
{
INT32 ret = 0;
char errmsg[200] = {0};
int sqlCode = 0;
timeval tBegin, tEnd, tDiff;
const char* precompile_statment2 = "INSERT INTO `tbl_test`( pri_key, nor_char, max_num, long_num, rec_upd_ts) VALUES(?, ?, ?, ?, ?)";
MYSQL conn;
mysql_init(&conn);
if (mysql_real_connect(&conn, "127.0.0.1", "dba", "abcdefg", "TESTDB", 3306, NULL, 0) == NULL)
{
fprintf(stderr, " mysql_real_connect, 2 failed\n");
exit(0);
}
MYSQL_STMT *stmt = mysql_stmt_init(&conn);
if (!stmt)
{
fprintf(stderr, " mysql_stmt_init, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
if (mysql_stmt_prepare(stmt, precompile_statment2, strlen(precompile_statment2)))
{
fprintf(stderr, " mysql_stmt_prepare, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
int i = 0;
int max_num = 3;
const int FIELD_NUM = 5;
while (i < max_num)
{
//MYSQL_BIND bind[196] = {0};
MYSQL_BIND bind[FIELD_NUM];
memset(bind, 0, FIELD_NUM * sizeof(MYSQL_BIND));
unsigned long str_length = strlen(pri_key);
bind[0].buffer_type = MYSQL_TYPE_STRING;
bind[0].buffer = (char *)pri_key;
bind[0].buffer_length = STRING_LEN;
bind[0].is_null = 0;
bind[0].length = &str_length;
unsigned long str_length_nor = strlen(nor_char);
bind[1].buffer_type = MYSQL_TYPE_STRING;
bind[1].buffer = (char *)nor_char;
bind[1].buffer_length = STRING_LEN;
bind[1].is_null = 0;
bind[1].length = &str_length_nor;
bind[2].buffer_type = MYSQL_TYPE_LONG;
bind[2].buffer = (char*)&max_num;
bind[2].is_null = 0;
bind[2].length = 0;
bind[3].buffer_type = MYSQL_TYPE_LONG;
bind[3].buffer = (char*)&max_num;
bind[3].is_null = 0;
bind[3].length = 0;
MYSQL_TIME ts;
ts.year= 2002;
ts.month= 02;
ts.day= 03;
ts.hour= 10;
ts.minute= 45;
ts.second= 20;
unsigned long str_length_time = strlen(rec_upd_ts);
bind[4].buffer_type = MYSQL_TYPE_TIMESTAMP;
bind[4].buffer = (char *)&ts;
bind[4].is_null = 0;
bind[4].length = 0;
if (mysql_stmt_bind_param(stmt, bind))
{
fprintf(stderr, " mysql_stmt_bind_param, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
cout << "before execute\n";
if (mysql_stmt_execute(stmt))
{
fprintf(stderr, " mysql_stmt_execute, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
cout << "after execute\n";
i++;
}
mysql_commit(&conn);
mysql_stmt_close(stmt);
return 0;
}
以上就是mysql批量插入数据的优化方法,建议大家也可以多看下我们以前的文章。
相关推荐
-

MySQL实现批量插入以优化性能的教程
对于一些数据量较大的系统,数据库面临的问题除了查询效率低下,还有就是数据入库时间长.特别像报表系统,每天花费在数据导入上的时间可能会长达几个小时或十几个小时之久.因此,优化数据库插入性能是很有意义的. 经过对MySQL innodb的一些性能测试,发现一些可以提高insert效率的方法,供大家参考参考. 1. 一条SQL语句插入多条数据. 常用的插入语句如: INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VAL
-
MySQL 大数据量快速插入方法和语句优化分享
锁定也将降低多连接测试的整体时间,尽管因为它们等候锁定最大等待时间将上升.例如: 复制代码 代码如下: Connection 1 does 1000 inserts Connections 2, 3, and 4 do 1 insert Connection 5 does 1000 inserts 如果不使用锁定,2.3和4将在1和5前完成.如果使用锁定,2.3和4将可能不在1或5前完成,但是整体时间应该快大约40%. INSERT.UPDATE和DELETE操作在MySQL中是很快的,通过为在
-
深入mysql并发插入优化详解
使用storm处理日志的时候,经常会遇到并发插入mysql的效率问题,到网上查了些资料,做一下笔记将表的引擎改为 myisam, 修改 my.cnf 的concurrent_insert=2,concurrent_insert 可以设的值有 0 1 2 ,2 是完全支持并发插入 1) concurrent _insert =0 ,无论MyISAM的表数据文件中间是否存在因为删除而留下俄空闲空间,都不允许concurrent insert. 2)concurrent_insert = 1,是当My
-
解析优化MySQL插入方法的五个妙招
工作中遇到大概20万的数据插入操作,程序编完后发现运行超时,修改PHP最大执行时间到600,还是超时,检查超时前插入的数据条数推算一下,大概要处理40~60分钟才能插入完成,看来程序写的效率太低,得优化了.测试电脑配置:CPU:AMD Sempron(tm) Processor内存:1.5G语句如下: 复制代码 代码如下: $sql = "insert into `test` (`test`) values ('$content')";for ($i=1;$i<1000;$i++
-
MySQL批量SQL插入性能优化详解
对于一些数据量较大的系统,数据库面临的问题除了查询效率低下,还有就是数据入库时间长.特别像报表系统,每天花费在数据导入上的时间可能会长达几个小时或十几个小时之久.因此,优化数据库插入性能是很有意义的. 经过对MySQL innodb的一些性能测试,发现一些可以提高insert效率的方法,供大家参考参考. 1. 一条SQL语句插入多条数据. 常用的插入语句如: INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VAL
-
mysql 数据插入优化方法
通常来说,在MyISAM里读写操作是串行的,但当对同一个表进行查询和插入操作时,为了降低锁竞争的频率,根据concurrent_insert的设置,MyISAM是可以并行处理查询和插入的: 当concurrent_insert=0时,不允许并发插入功能. 当concurrent_insert=1时,允许对没有洞洞的表使用并发插入,新数据位于数据文件结尾(缺省). 当concurrent_insert=2时,不管表有没有洞洞,都允许在数据文件结尾并发插入. 这样看来,把concurrent_ins
-
MySql批量插入优化Sql执行效率实例详解
MySql批量插入优化Sql执行效率实例详解 itemcontractprice数量1万左右,每条itemcontractprice 插入5条日志. updateInsertSql.AppendFormat("UPDATE itemcontractprice AS p INNER JOIN foreigncurrency AS f ON p.ForeignCurrencyId = f.ContractPriceId SET p.RemainPrice = f.RemainPrice * {0},
-
mysql中迅速插入百万条测试数据的方法
对比一下,首先是用 mysql 的存储过程弄的: 复制代码 代码如下: mysql>delimiter $ mysql>SET AUTOCOMMIT = 0$$ mysql> create procedure test() begin declare i decimal (10) default 0 ; dd:loop INSERT INTO `million` (`categ_id`, `categ_fid`, `SortPath`, `address`, `p_identifier`
-
MySql中把一个表的数据插入到另一个表中的实现代码
小编今天在写一个 将一个数据库的表数据 导入到 另一个数据库的表的时候 我是这么写的 复制代码 代码如下: <?php header("Content-type:text/html;charset=utf-8"); $conn = mysql_connect("localhost","root","");mysql_select_db('nnd',$conn);mysql_select_db('ahjk',$conn);
-
mysql如何优化插入记录速度
插入记录时,影响插入速度的主要是索引.唯一性校验.一次插入记录条数等.根据这些情况,可以分别进行优化,本节将介绍优化插入记录速度的几种方法. 一. 对于MyISAM引擎表常见的优化方法如下: 1. 禁用索引.对于非空表插入记录时,MySQL会根据表的索引对插入记录建立索引.如果插入大量数据,建立索引会降低插入记录的速度.为了解决这种情况可以在插入记录之前禁用索引,数据插入完毕后在开启索引.禁用索引的语句为: ALTER TABLE tb_name DISABLE KEYS; 重新开启索引的语句