Java中BM(Boyer-Moore)算法的图解与实现
目录
- 简介
- 基本概念
- 坏字符
- 好后缀
- 工作过程
- 坏字符
- 好后缀
- BM算法
- 代码实现
- 最后
简介
本篇文章主要分为两个大的部分,第一部分通过图解的方式讲解BM算法,第二部分则代码实现一个简易的BM算法。
基本概念
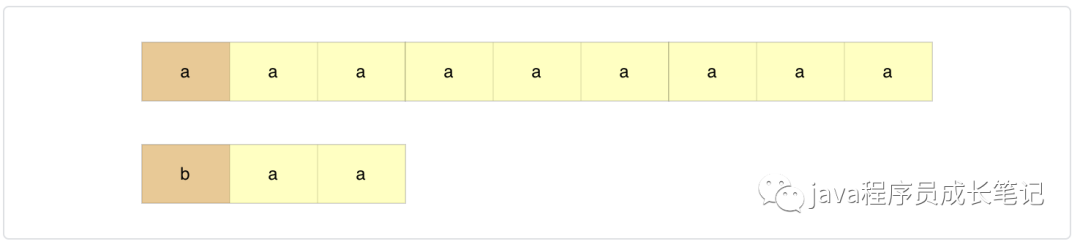
bm是一个字符串匹配算法,有实验统计,该算法是著名kmp算法性能的3~4倍,其中有两个关键概念,坏字符和好后缀。
首先举一个例子
需要进行匹配的主串:a b c a g f a c j k a c k e a c
匹配的模式串:a c k e a c
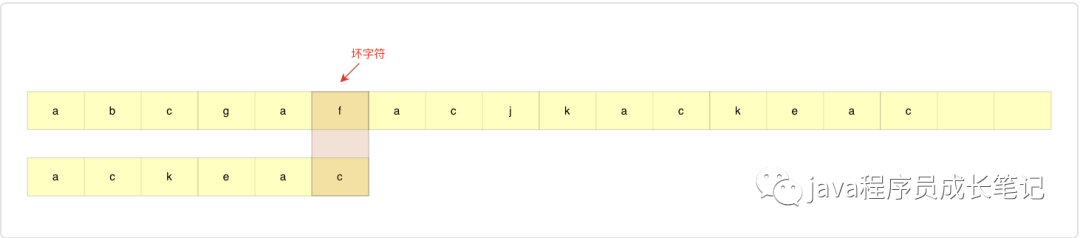
坏字符
如下图所示,从模式串最后一个字符开始匹配,主串中第一个出现的不匹配的字符叫做坏字符。
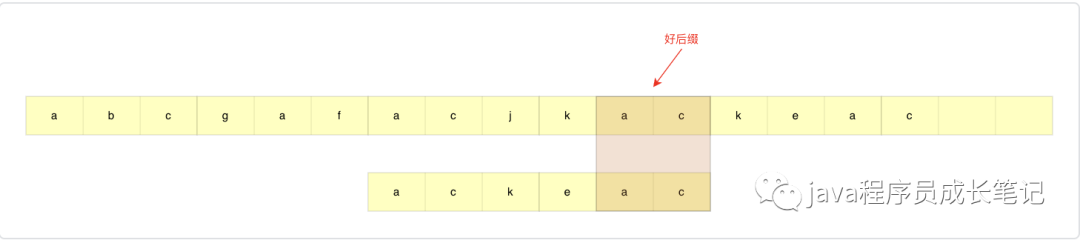
好后缀
如下图所示,从模式串最后一个字符开始匹配,匹配到的主串中的字符为好后缀。
工作过程
坏字符
依旧是这张图,接下来我们按从简单情况到复杂情况进行分析。
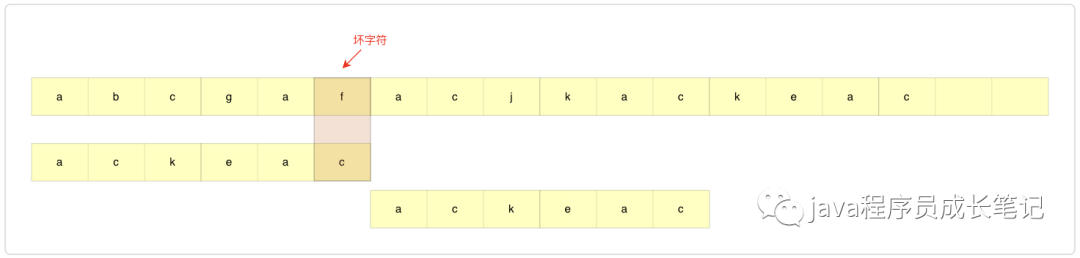
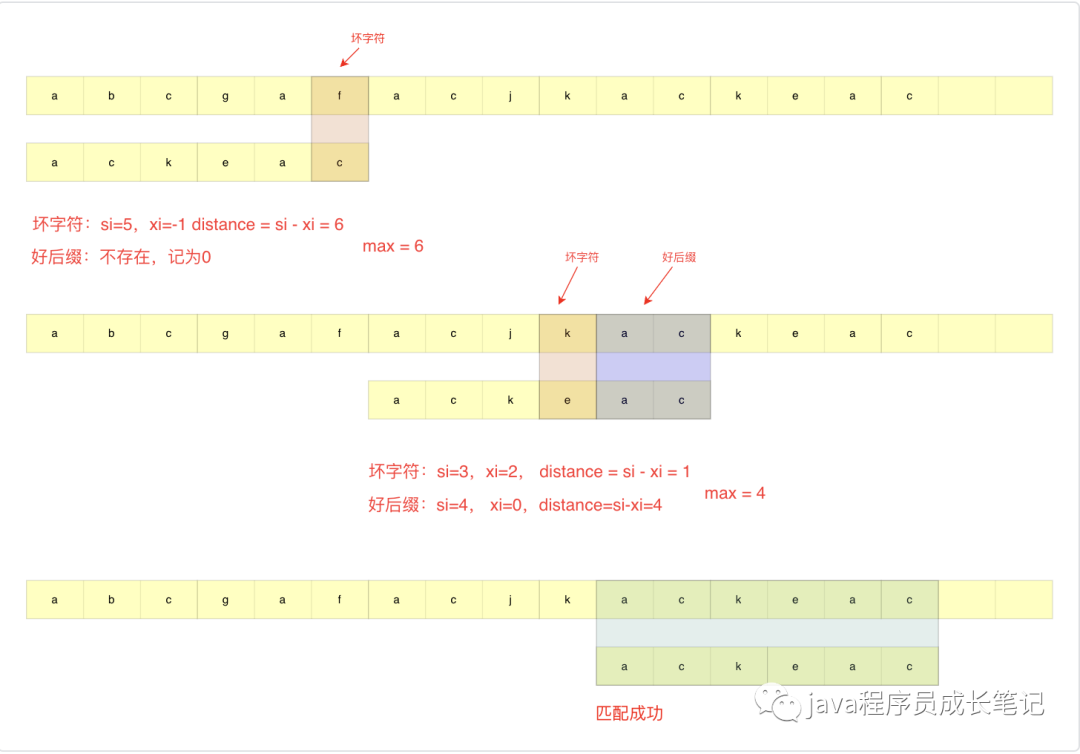
step1: 找到坏字符f,该字符对应模式串中位置si=5,如果当前没有找到坏字符,即完全匹配,直接返回。
step2: 查找字符f在模式串中出现位置,在当前模式串中,f没有出现,证明之前没有情况可以匹配,模式串直接滑到f后面位置。此次结束,否则step3。
step3: 举个例子吧,如果主串和模式串如下,f为坏字符,模式串中存在f,记位置xi=3,这时候不能直接滑到f的后面,这时候应该将模式串中的f和主串中的f对齐,如果是下面这个例子,此时直接匹配成功。如果模式串中不止存在一个f我们如何选择呢?用哪个f与模式串f对齐?答案是模式串中靠后的,如果使用靠前的,可能会多滑。
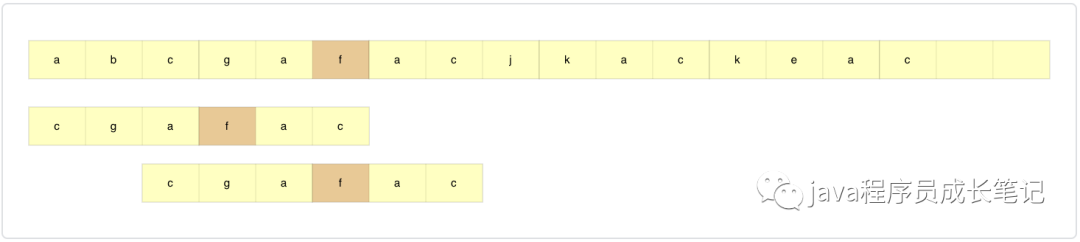
在坏字符匹配方法中,模式串往后滑动的距离应该是si-xi(如果坏字符在模式串中不存在,xi=-1)。
但是坏字符方法可能存在一个问题,看下面这个例子,坏字符a,对应匹配串中位置si=0,但是在匹配串中靠后出现位置xi=2,si-xi=-2,匹配串还往前移动,这样就会出现问题,但是当我们把下面的好后缀讲了之后,这个问题就迎刃而解了。
好后缀
首先看这张图,这时候我们暂时不管坏字符方法(坏字符为k),由简单情况到复杂情况进行分析。
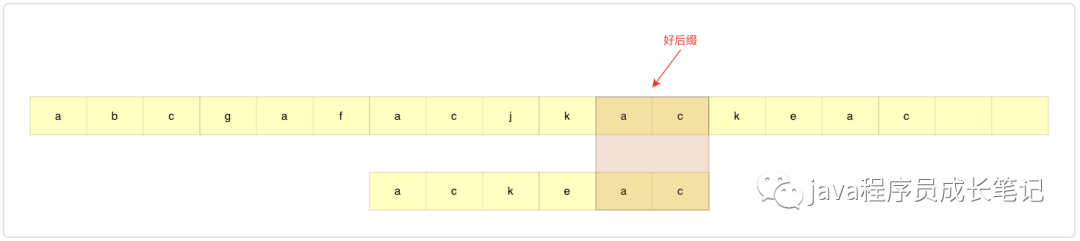
step1:找到好后缀ac,起始位置si=4
step2:在模式串中查找其他位置是否存在好后缀ac(如果存在多个,为了不过度滑动,仍然选择靠后的一个),找到开头的ac,起始位置xi=0,滑动模式串使得找到的开头ac与好后缀ac匹配,滑动距离si-xi=4。此次结束,否则step3。
step3:还是先举个例子,假设模式串如下图所示,此时好后缀为ac,但是在整个模式串其他地方不存在ac,此时如果我们直接将模式串滑到ac之后,则会出现问题,实际上我们只需要滑到c的位置即可。一般化的场景我们需要怎么操作呢?对于好后缀,如果匹配串的前缀能够和好后缀的后缀匹配上,则我们直接滑到匹配位置。计算方式:好后缀后缀起始位置-0。
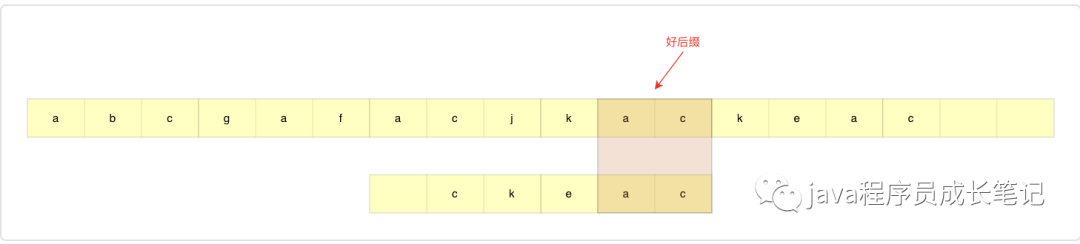
思考一下:如果匹配串中间出现与好后缀后缀匹配的情况,是否需要考虑?答案是否定的,当中间出现的时候,滑动过去肯定匹配不上。
BM算法
说完了BM算法中的两个重要概念之后,BM算法具体怎样实现的呢?
其实BM算法就是坏字符和好后缀的结合,具体就是匹配串向前滑动距离取两者计算出来的较大值。
具体步骤我们用图来演示一遍

代码实现
在上面,我们说到了,在BM算法中有两个关键概念--坏字符和好后缀,所以我们的代码实现将分为三个步骤。
- 利用坏字符算法,计算匹配串可以滑动的距离
- 利用好后缀算法,计算匹配串可以滑动的距离
- 结合坏字符算法和好后缀算法,实现BM算法,查看匹配串在主串中存在的位置
step1: 坏字符算法,经过之前的分析,我们找到坏字符之后,需要查找匹配串中是否出现过坏字符,如果出现多个,我们滑动匹配串,将靠后的坏字符与主串坏字符对齐。如果不存在,则完全匹配。如果我们每次找到坏字符都去查找一次匹配串中是否出现过,效率不高,所以我们可以用一个hash表保存匹配串中出现的字符以及最后出现的位置,提高查找效率。

我们设定的只有小写字母,可以直接利用一个26大小的数组存储,数组下标存储出现的字符(字符-‘a’),数组值存储出现的位置。
int[] modelStrIndex;
private void badCharInit(char[] modelStr) {
modelStrIndex = new int[26];
//-1表示该字符在匹配串中没有出现过
for (int i = 0 ; i < 26 ; i ++) {
modelStrIndex[i] = -1;
}
for (int i = 0 ; i < modelStr.length ; i++) {
//直接依次存入,出现相同的直接覆盖,
//保证保存的时候靠后出现的位置
modelStrIndex[modelStr[i] - 'a'] = i;
}
}
查找坏字符出现位置badCharIndex,未出现,匹配成功,直接返回0。
查找匹配串中出现的坏字符位置modelStrIndex,未出现,滑动到坏字符位置之后,直接返回匹配串的长度。
返回badCharIndex - modelStrIndex。
注:坏字符是指与匹配串字符不匹配的主串字符,是看的主串,但是我们计算的位置,是匹配串中的位置。
/**
* @param mainStr 主串
* @param modelStr 模式串
* @param start 模式串在主串中的起始位置
* @return 模式串可滑动距离,如果为0则匹配上
*/
private int badChar(char[] mainStr, char[] modelStr, int start) {
//坏字符位置
int badCharIndex = -1;
char badChar = '\0';
//开始从匹配串后往前进行匹配
for (int i = modelStr.length - 1 ; i >= 0 ; i --) {
int mainStrIndex = start + i;
//第一个出现不匹配的即为坏字符
if (mainStr[mainStrIndex] != modelStr[i]) {
badCharIndex = i;
badChar = mainStr[mainStrIndex];
break;
}
}
if (-1 == badCharIndex) {
//不存在坏字符,需匹配成功,要移动距离为0
return 0;
}
//查看坏字符在匹配串中出现的位置
if (modelStrIndex[badChar - 'a'] > -1) {
//出现过
return badCharIndex - modelStrIndex[badChar - 'a'];
}
return modelStr.length;
}
step2:好后缀算法,经过之前的分析,我们在实现好后缀算法的时候,有一个后缀前缀匹配的过程,这里我们仍然可以事先进行处理。将匹配串一分为二,分别匹配前缀和后缀字串。ps:开始我的处理是两个数组,将前缀后缀存下来,需要的时候进行匹配,但是在写文章的时候,我突然回过神来,我已经处理了一遍了,为什么不直接标记是否匹配呢?
初始化匹配串前缀后缀是否匹配数组,标志当前长度的前缀后缀是否匹配。
//对应位置的前缀后缀是否匹配
boolean[] isMatch;
public void goodSuffixInit(char[] modelStr) {
isMatch = new boolean[modelStr.length / 2];
StringBuilder prefixStr = new StringBuilder();
List<Character> suffixChar = new ArrayList<>(modelStr.length / 2);
for (int i = 0 ; i < modelStr.length / 2 ; i ++) {
prefixStr.append(modelStr[i]);
suffixChar.add(0, modelStr[modelStr.length - i - 1]);
isMatch[i] = this.madeSuffix(suffixChar).equals(prefixStr.toString());
}
}
/**
* 组装后缀数据
* @param characters
* @return
*/
private String madeSuffix(List<Character> characters) {
StringBuilder sb = new StringBuilder();
for (Character ch : characters) {
sb.append(ch);
}
return sb.toString();
}
step3: 结合坏字符和好后缀算法实现BM算法,起始就是每一次匹配,同时调用坏字符和好后缀算法,如果返回移动距离为0,表示已经匹配成功,直接返回当前匹配的起始距离。其余情况下,滑动坏字符和好后缀算法返回的较大值。如果主串匹配完还没有匹配成功,则返回-1。
注:加了一些日志打印匹配过程
public int bmStrMatch(char[] mainStr, char[] modelStr) {
//初始化坏字符和好后缀需要的数据
this.badCharInit(modelStr);
this.goodSuffixInit(modelStr);
int start = 0;
while (start + modelStr.length <= mainStr.length) {
//坏字符计算的需要滑动的距离
int badDistance = this.badChar(mainStr, modelStr, start);
//好后缀计算的需要滑动的距离
int goodSuffixDistance = this.goodSuffix(mainStr, modelStr, start);
System.out.println("badDistance = " +badDistance + ", goodSuffixDistance = " + goodSuffixDistance);
//任意一个匹配成功即成功(可以计算了坏字符和好后缀之后分别判断一下)
//减少一次操作
if (0 == badDistance || 0 == goodSuffixDistance) {
System.out.println("匹配到的位置 :" + start);
return start;
}
start += Math.max(badDistance, goodSuffixDistance);
System.out.println("滑动至:" + start);
}
return -1;
}
最后
使用前面使用的例子,我们来实际调用一下
public static void main(String[] args) {
BoyerMoore moore = new BoyerMoore();
char[] mainStr = new char[]{'a','b', 'c', 'a', 'g', 'f', 'a', 'c', 'j', 'k', 'a', 'c', 'k', 'e', 'a', 'c'};
char[] modelStr = new char[]{'a', 'c', 'k', 'e', 'a', 'c'};
System.out.println(moore.bmStrMatch(mainStr, modelStr));
}
调用结果

以上就是Java中BM(Boyer-Moore)算法的图解与实现的详细内容,更多关于Java BM算法的资料请关注我们其它相关文章!
相关推荐
-
Java实现字符串匹配的示例代码
目录 java实现字符串匹配 暴力匹配 KMP算法 java实现字符串匹配 暴力匹配 /** * 暴力匹配 * * @param str1 需要找的总字符串 * @param str2 需要找到的字符串 * @return 找到的字符串的下标 */ private static int violence(String str1, String str2) { char[] s1 = str1.toCharArray(); char[] s2 = str2.toCharArray(); int s
-

java暴力匹配及KMP算法解决字符串匹配问题示例详解
目录 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 二.KMP算法 算法介绍 一个图例介绍KMP算法 代码实现 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 String str1 = "BBC ABCDAB ABCDABCDABDE"; String str2 = "ABCDABD"; 1. S[0]为B,P[0]为A,不匹配,执行第②条指令:"如果失配(即S[i]! = P[j]),令i = i - (j - 1),
-
多模字符串匹配算法原理及Java实现代码
多模字符串匹配算法在这里指的是在一个字符串中寻找多个模式字符字串的问题.一般来说,给出一个长字符串和很多短模式字符串,如何最快最省的求出哪些模式字符串出现在长字符串中是我们所要思考的.该算法广泛应用于关键字过滤.入侵检测.病毒检测.分词等等问题中.多模问题一般有Trie树,AC算法,WM算法等等. 背景 在做实际工作中,最简单也最常用的一种自然语言处理方法就是关键词匹配,例如我们要对n条文本进行过滤,那本身是一个过滤词表的,通常进行过滤的代码如下 for (String document : d
-
Java 数据结构与算法系列精讲之字符串暴力匹配
概述 从今天开始, 小白我将带大家开启 Java 数据结构 & 算法的新篇章. 字符串匹配 字符串匹配 (String Matching) 指的是判断一个字符串是否包含另一个字符串. 举个例子: 字符串 "Hello World" 包含字符串 "Hello" 字符串 "Hello World" 不包含字符串 "LaLaLa" 暴力匹配 暴力匹配 (Brute-Force) 的思路: 如果charArray1[i] ==
-
Java正则多字符串匹配替换
Java中使用也比较简单:1. 编译正则表达式的字面值得到对应的模式Pattern对象: 2. 创建匹配给定输入与此模式的匹配器Matcher: 3. 通过匹配器对象执行操作,匹配器对象的方法很丰富,方法之间组合使用更加强大. 复制代码 代码如下: public static void main(String[] args) { //被替换关键字的的数据源 Map<String,String> tokens = new HashMap<String,String>(
-
Java中BM(Boyer-Moore)算法的图解与实现
目录 简介 基本概念 坏字符 好后缀 工作过程 坏字符 好后缀 BM算法 代码实现 最后 简介 本篇文章主要分为两个大的部分,第一部分通过图解的方式讲解BM算法,第二部分则代码实现一个简易的BM算法. 基本概念 bm是一个字符串匹配算法,有实验统计,该算法是著名kmp算法性能的3-4倍,其中有两个关键概念,坏字符和好后缀. 首先举一个例子 需要进行匹配的主串:a b c a g f a c j k a c k e a c 匹配的模式串:a c k e a c 坏字符 如下图所示,从模式串最后一个
-
java 中模式匹配算法-KMP算法实例详解
java 中模式匹配算法-KMP算法实例详解 朴素模式匹配算法的最大问题就是太低效了.于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写. 简单的说,KMP算法的对于主串的当前位置不回溯.也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为"abcababcabcabcabcabc",子串为"abcabx".第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的
-
Java中七种排序算法总结分析
目录 前言:对文章出现的一些名词进行解释 一.插入排序 1.基本思想 2.直接插入排序 3.希尔排序(缩小增量排序) 二.选择排序 1.基本思想 2.直接选择排序 3.堆排序 三.交换排序 1.基本思想 2.冒泡排序 3.快速排序(递归与非递归) 1.Hoare版 2.挖坑法 3.前后标记法(难理解) 4.快速排序优化 5.快速排序非递归 6.相关特性总结 四.归并排序(递归与非递归) 前言:对文章出现的一些名词进行解释 排序: 使一串记录,按照其中的某个或某些关键字的大小,递增或者递减排列起来
-
详解Java中字典树(Trie树)的图解与实现
目录 简介 工作过程 数据结构 初始化 构建字典树 应用 匹配有效单词 关键词提示 总结 简介 Trie又称为前缀树或字典树,是一种有序树,它是一种专门用来处理串匹配的数据结构,用来解决一组字符中快速查找某个字符串的问题.Google搜索的关键字提示功能相信大家都不陌生,我们在输入框中进行搜索的时候,会下拉出一系列候选关键词. 上面这个关键词提示功能,底层最基本的原理就是我们今天说的数据结构:Trie树 我们先看看Tire树长什么样子,以单纯的单词匹配为例,首先它是一棵多叉树结构,根节点是一个空
-
详解5种Java中常见限流算法
目录 01固定窗口 02滑动窗口 03漏桶算法 04令牌桶 05滑动日志 06分布式限流 07总结 1.瞬时流量过高,服务被压垮? 2.恶意用户高频光顾,导致服务器宕机? 3.消息消费过快,导致数据库压力过大,性能下降甚至崩溃? ...... 在高并发系统中,出于系统保护角度考虑,通常会对流量进行限流:不但在工作中要频繁使用,而且也是面试中的高频考点. 今天我们将图文并茂地对常见的限流算法分别进行介绍,通过各个算法的特点,给出限流算法选型的一些建议,并给出Java语言实现的代码示例. 01固定窗
-
图文讲解Java中实现quickSort快速排序算法的方法
相对冒泡排序.选择排序等算法而言,快速排序的具体算法原理及实现有一定的难度.为了更好地理解快速排序,我们仍然以举例说明的形式来详细描述快速排序的算法原理.在前面的排序算法中,我们以5名运动员的身高排序问题为例进行讲解,为了更好地体现快速排序的特点,这里我们再额外添加3名运动员.实例中的8名运动员及其身高信息详细如下(F.G.H为新增的运动员): A(181).B(169).C(187).D(172).E(163).F(191).G(189).H(182) 在前面的排序算法中,这些排序都是由教练主
-
java中全排列的生成算法汇总
全排列的生成算法就是对于给定的字符集,用有效的方法将所有可能的全排列无重复无遗漏地枚举出来.任何n个字符集的排列都可以与1-n的n个数字的排列一一对应, 因此在此就以n个数字的排列为例说明排列的生成法. n个字符的全体排列之间存在一个确定的线性顺序关系.所有的排列中除最后一个排列外,都有一个后继:除第一个排列外,都有一个前驱.每个排列的后继都可以从它的前驱经过最少的变化而得到,全排列的生成算法就是从第一个排列开始逐个生成所有的排列的方法. 全排列的生成法通常有以下几种: 字典序法 递增进
-
详解Java中AC自动机的原理与实现
目录 简介 工作过程 数据结构 初始化 构建字典树 构建失败指针 匹配 执行结果 简介 AC自动机是一个多模式匹配算法,在模式匹配领域被广泛应用,举一个经典的例子,违禁词查找并替换为***.AC自动机其实是Trie树和KMP 算法的结合,首先将多模式串建立一个Tire树,然后结合KMP算法前缀与后缀匹配可以减少不必要比较的思想达到高效找到字符串中出现的匹配串. 如果不知道什么是Tire树,可以先查看:详解Java中字典树(Trie树)的图解与实现 如果不知道KMP算法,可以先查看:详解Java中
-
java中hashCode、equals的使用方法教程
前言 众所周知Java.lang.Object 有一个hashCode()和一个equals()方法,这两个方法在软件设计中扮演着举足轻重的角色.在一些类中重写这两个方法以完成某些重要功能. 1.为什么要用 hashCode()? 集合Set中的元素是无序且不可重复的,那判断两个元素是否重复的依据是什么呢? 有人说:比较对象是否相等当然用Object.equal()了.但是,Set中存在大量对象,后添加到集合Set中的对象元素比较次数会逐渐增多,大大降低了程序运行效率. Java中采用哈希算法(
-
详解Java中KMP算法的图解与实现
目录 图解 代码实现 图解 kmp算法跟之前讲的bm算法思想有一定的相似性.之前提到过,bm算法中有个好后缀的概念,而在kmp中有个好前缀的概念,什么是好前缀,我们先来看下面这个例子. 观察上面这个例子,已经匹配的abcde称为好前缀,a与之后的bcde都不匹配,所以没有必要再比一次,直接滑动到e之后即可. 那如果好前缀中有互相匹配的字符呢? 观察上面这个例子,这个时候如果我们直接滑到好前缀之后,则会过度滑动,错失匹配子串.那我们如何根据好前缀来进行合理滑动? 其实就是看当前的好前缀的前缀和后缀