Python实现随机森林RF模型超参数的优化详解
目录
- 1 代码分段讲解
- 1.1 数据与模型准备
- 1.2 超参数范围给定
- 1.3 超参数随机匹配择优
- 1.4 超参数遍历匹配择优
- 1.5 模型运行与精度评定
- 2 完整代码
本文介绍基于Python的随机森林(Random Forest,RF)回归代码,以及模型超参数(包括决策树个数与最大深度、最小分离样本数、最小叶子节点样本数、最大分离特征数等)自动优化的代码。
本文是在上一篇文章Python实现随机森林RF并对比自变量的重要性的基础上完成的,因此本次仅对随机森林模型超参数自动择优部分的代码加以详细解释;而数据准备、模型建立、精度评定等其他部分的代码详细解释,大家直接点击上述文章Python实现随机森林RF并对比自变量的重要性查看即可。
其中,关于基于MATLAB实现同样过程的代码与实战,大家可以点击查看文章MATLAB实现随机森林(RF)回归与自变量影响程度分析。
本文分为两部分,第一部分为代码的分段讲解,第二部分为完整代码。
1 代码分段讲解
1.1 数据与模型准备
本部分是对随机森林算法的数据与模型准备,由于在之前的博客中已经详细介绍过了,本文就不再赘述~大家直接查看文章Python实现随机森林RF并对比自变量的重要性即可。
import pydot import numpy as np import pandas as pd import scipy.stats as stats import matplotlib.pyplot as plt from pprint import pprint from sklearn import metrics from openpyxl import load_workbook from sklearn.tree import export_graphviz from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import GridSearchCV from sklearn.model_selection import RandomizedSearchCV # Attention! Data Partition # Attention! One-Hot Encoding train_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Train.csv' test_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Test.csv' write_excel_path='G:/CropYield/03_DL/05_NewML/ParameterResult_ML.xlsx' tree_graph_dot_path='G:/CropYield/03_DL/05_NewML/tree.dot' tree_graph_png_path='G:/CropYield/03_DL/05_NewML/tree.png' random_seed=44 random_forest_seed=np.random.randint(low=1,high=230) # Data import train_data=pd.read_csv(train_data_path,header=0) test_data=pd.read_csv(test_data_path,header=0) # Separate independent and dependent variables train_Y=np.array(train_data['Yield']) train_X=train_data.drop(['ID','Yield'],axis=1) train_X_column_name=list(train_X.columns) train_X=np.array(train_X) test_Y=np.array(test_data['Yield']) test_X=test_data.drop(['ID','Yield'],axis=1) test_X=np.array(test_X)
1.2 超参数范围给定
首先,我们需要对随机森林模型超参数各自的范围加以确定,之后我们将在这些范围内确定各个超参数的最终最优取值。换句话说,我们现在先给每一个需要择优的超参数划定一个很大很大的范围(例如对于“决策树个数”这个超参数,我们可以将其范围划定在10到5000这样一个很大的范围),然后后期将用择优算法在每一个超参数的这个范围内进行搜索。
在此,我们先要确定对哪些超参数进行择优。本文选择在随机森林算法中比较重要的几个超参数进行调优,分别是:决策树个数n_estimators,决策树最大深度max_depth,最小分离样本数(即拆分决策树节点所需的最小样本数)min_samples_split,最小叶子节点样本数(即一个叶节点所需包含的最小样本数)min_samples_leaf,最大分离特征数(即寻找最佳节点分割时要考虑的特征变量数量)max_features,以及是否进行随机抽样bootstrap等六种。关于上述超参数如果大家不是太了解具体的含义,可以查看文章Python实现随机森林RF并对比自变量的重要性的1.5部分,可能就会比较好理解了(不过其实不理解也不影响接下来的操作)。
这里提一句,其实随机森林的超参数并不止上述这些,我这里也是结合数据情况与最终的精度需求,选择了相对比较常用的几个超参数;大家依据各自实际需要,选择需要调整的超参数,并用同样的代码思路执行即可。
# Search optimal hyperparameter
n_estimators_range=[int(x) for x in np.linspace(start=50,stop=3000,num=60)]
max_features_range=['auto','sqrt']
max_depth_range=[int(x) for x in np.linspace(10,500,num=50)]
max_depth_range.append(None)
min_samples_split_range=[2,5,10]
min_samples_leaf_range=[1,2,4,8]
bootstrap_range=[True,False]
random_forest_hp_range={'n_estimators':n_estimators_range,
'max_features':max_features_range,
'max_depth':max_depth_range,
'min_samples_split':min_samples_split_range,
'min_samples_leaf':min_samples_leaf_range
# 'bootstrap':bootstrap_range
}
pprint(random_forest_hp_range)
可以看到,上述代码首先是对六种超参数划定了一个范围,然后将其分别存入了一个超参数范围字典random_forest_hp_range。在这里大家可以看到,我在存入字典时,将bootstrap的范围这一句注释掉了,这是由于当时运行后我发现bootstrap还是处于True这个状态比较好(也就是得到的结果精度比较高),因此就取消了这一超参数的择优;大家依据个人数据与模型的实际情况来即可~
我们可以看一下random_forest_hp_range变量的取值情况:
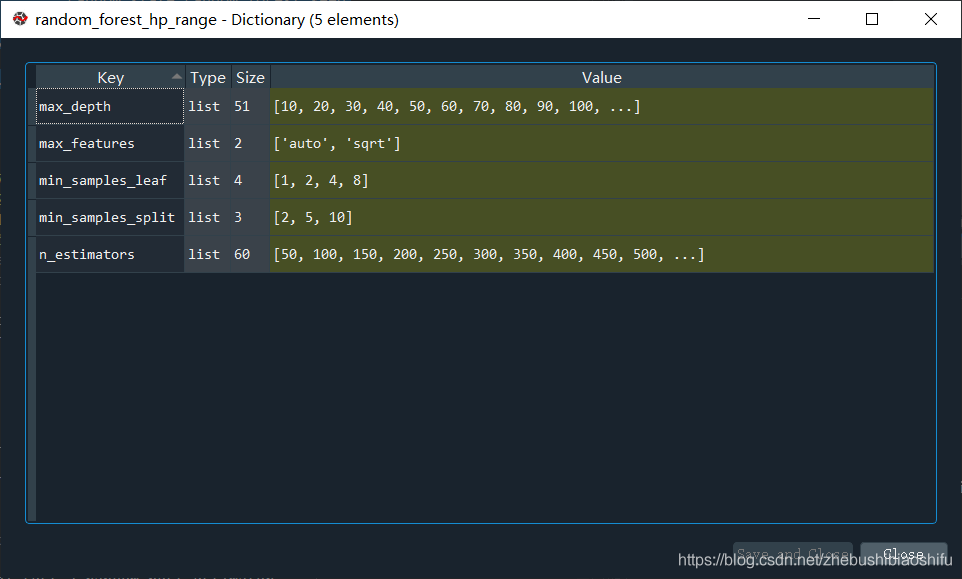
没错,它是一个字典,键就是超参数的名称,值就是超参数的范围。因为我将bootstrap注释掉了,因此这个字典里就没有bootstrap这一项了~
1.3 超参数随机匹配择优
上面我们确定了每一种超参数各自的范围,那么接下来我们就将他们分别组合,对比每一个超参数取值组合所得到的模型结果,从而确定最优超参数组合。
其实大家会发现,我们上面划定六种超参数(除去我后来删除的bootstrap的话是五种),如果按照排列组合来计算的话,会有很多很多种组合方式,如果要一一尝试未免也太麻烦了。因此,我们用到RandomizedSearchCV这一功能——其将随机匹配每一种超参数组合,并输出最优的组合。换句话说,我们用RandomizedSearchCV来进行随机的排列,而不是对所有的超参数排列组合方法进行遍历。这样子确实可以节省很多时间。
random_forest_model_test_base=RandomForestRegressor()
random_forest_model_test_random=RandomizedSearchCV(estimator=random_forest_model_test_base,
param_distributions=random_forest_hp_range,
n_iter=200,
n_jobs=-1,
cv=3,
verbose=1,
random_state=random_forest_seed
)
random_forest_model_test_random.fit(train_X,train_Y)
best_hp_now=random_forest_model_test_random.best_params_
pprint(best_hp_now)
由代码可以看到,我们首先建立一个随机森林模型random_forest_model_test_base,并将其带入到RandomizedSearchCV中;其中,RandomizedSearchCV的参数组合就是刚刚我们看的random_forest_hp_range,n_iter就是具体随机搭配超参数组合的次数(这个次数因此肯定是越大涵盖的组合数越多,效果越好,但是也越费时间),cv是交叉验证的折数(RandomizedSearchCV衡量每一种组合方式的效果就是用交叉验证来进行的),n_jobs与verbose是关于模型线程、日志相关的信息,大家不用太在意,random_state是随机森林中随机抽样的随机数种子。
之后,我们对random_forest_model_test_random加以训练,并获取其所得到的最优超参数匹配组合best_hp_now。在这里,模型的训练次数就是n_iter与cv的乘积(因为交叉验证有几折,那么就需要运行几次;而一共有n_iter个参数匹配组合,因此总次数就是二者相乘)。例如,用上述代码那么一共就需要运行600次。运行过程在程序中将自动显示,如下图。

可以看到,一共有600次fit,我这里共花了11.7min完成。具体速度和电脑配置、自变量与因变量数据量大小,以及电脑此时内存等等都有关。
运行完毕,我们来看看找到的最有超参数组合best_hp_now。

可以看到,经过200种组合匹配方式的计算,目前五种超参数最优的组合搭配方式已经得到了。其实每一次得到的超参数最优组合结果差距也是蛮大的——例如同一批数据,有的时候我得到的n_estimators最优值是如图所示的100,有的时候也会是2350;所以大家依据实际情况来判断即可~
那么接下来,我们就继续对这一best_hp_now所示的结果进行更进一步的择优。
1.4 超参数遍历匹配择优
刚刚我们基于RandomizedSearchCV,实现了200次的超参数随机匹配与择优;但是此时的结果是一个随机不完全遍历后所得的结果,因此其最优组合可能并不是全局最优的,而只是一个大概的最优范围。因此接下来,我们需要依据上述所得到的随机最优匹配结果,进行遍历全部组合的匹配择优。
遍历匹配即在随机匹配最优结果的基础上,在其临近范围内选取几个数值,并通过GridSearchCV对每一种匹配都遍历,从而选出比较好的超参数最终取值结果。
# Grid Search
random_forest_hp_range_2={'n_estimators':[60,100,200],
'max_features':[12,13],
'max_depth':[350,400,450],
'min_samples_split':[2,3] # Greater than 1
# 'min_samples_leaf':[1,2]
# 'bootstrap':bootstrap_range
}
random_forest_model_test_2_base=RandomForestRegressor()
random_forest_model_test_2_random=GridSearchCV(estimator=random_forest_model_test_2_base,
param_grid=random_forest_hp_range_2,
cv=3,
verbose=1,
n_jobs=-1)
random_forest_model_test_2_random.fit(train_X,train_Y)
best_hp_now_2=random_forest_model_test_2_random.best_params_
pprint(best_hp_now_2)
大家可以看到,本部分代码其实和1.3部分比较类似。我们着重讲解random_forest_hp_range_2。其中,n_estimators设定为了[60,100,200],这是由于我们刚刚得到的best_hp_now中n_estimators为100,那么我们就在100附近选取几个值,作为新的n_estimators范围;max_features也是一样的,因为best_hp_now中max_features为'sqrt',也就是输入数据特征(自变量)的个数的平方根,而我这里自变量个数大概是150多个,因此其开平方之后就是12.24左右,那么就选择其附近的两个数(需要为整数),因此就选择了[12,13]。其他的超参数取值也是类似的。这里我将'min_samples_leaf'也给注释掉了是因为我跑了很多次发现,'min_samples_leaf'还是取1最好,那么就直接选择为默认1('min_samples_leaf'在不指定的情况下默认为1)即可,因为超参数范围越小,程序跑的就越快。
这里程序运行的次数就是每一种超参数取值个数的排列组合次数乘以交叉验证的折数,也就是(2*3*2*3)*3=108次,我们来看看是不是108次:

很明显,没有问题,就是108个fit。和前面的600次fit比起来,这样就快很多了(这也是为什么我直接将'min_samples_leaf'与'bootstrap'注释掉的原因;要是这两个超参数也参与的话,那么假设他们两个各有2个取值的话,总时间至少就要翻2*2=4倍)。
再来看看经过遍历择优后的最优超参数匹配取值best_hp_now_2。

以上就是我们经过一次随机择优、一次遍历择优之后的超参数结果(不要忘记了'min_samples_leaf'与'bootstrap'还要分别取1和True,也就是默认值)。如果大家感觉这个组合搭配还不是很好,那么可以继续执行本文“1.4 超参数遍历匹配择优”部分1到2次,精度可能会有更进一步的提升。
1.5 模型运行与精度评定
结束了上述超参数择优过程,我们就可以进行模型运行、精度评定与结果输出等操作。本部分内容除了第一句代码(将最优超参数组合分配给模型)之外,其余部分由于在之前的博客中已经详细介绍过了,本文就不再赘述~大家直接查看文章Python实现随机森林RF并对比自变量的重要性即可。
# Build RF regression model with optimal hyperparameters
random_forest_model_final=random_forest_model_test_2_random.best_estimator_
# Predict test set data
random_forest_predict=random_forest_model_test_2_random.predict(test_X)
random_forest_error=random_forest_predict-test_Y
# Draw test plot
plt.figure(1)
plt.clf()
ax=plt.axes(aspect='equal')
plt.scatter(test_Y,random_forest_predict)
plt.xlabel('True Values')
plt.ylabel('Predictions')
Lims=[0,10000]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims,Lims)
plt.grid(False)
plt.figure(2)
plt.clf()
plt.hist(random_forest_error,bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
# Verify the accuracy
random_forest_pearson_r=stats.pearsonr(test_Y,random_forest_predict)
random_forest_R2=metrics.r2_score(test_Y,random_forest_predict)
random_forest_RMSE=metrics.mean_squared_error(test_Y,random_forest_predict)**0.5
print('Pearson correlation coefficient is {0}, and RMSE is {1}.'.format(random_forest_pearson_r[0],
random_forest_RMSE))
# Save key parameters
excel_file=load_workbook(write_excel_path)
excel_all_sheet=excel_file.sheetnames
excel_write_sheet=excel_file[excel_all_sheet[0]]
excel_write_sheet=excel_file.active
max_row=excel_write_sheet.max_row
excel_write_content=[random_forest_pearson_r[0],random_forest_R2,random_forest_RMSE,
random_seed,random_forest_seed]
for i in range(len(excel_write_content)):
exec("excel_write_sheet.cell(max_row+1,i+1).value=excel_write_content[i]")
excel_file.save(write_excel_path)
# Draw decision tree visualizing plot
random_forest_tree=random_forest_model_final.estimators_[5]
export_graphviz(random_forest_tree,out_file=tree_graph_dot_path,
feature_names=train_X_column_name,rounded=True,precision=1)
(random_forest_graph,)=pydot.graph_from_dot_file(tree_graph_dot_path)
random_forest_graph.write_png(tree_graph_png_path)
# Calculate the importance of variables
random_forest_importance=list(random_forest_model_final.feature_importances_)
random_forest_feature_importance=[(feature,round(importance,8))
for feature, importance in zip(train_X_column_name,
random_forest_importance)]
random_forest_feature_importance=sorted(random_forest_feature_importance,key=lambda x:x[1],reverse=True)
plt.figure(3)
plt.clf()
importance_plot_x_values=list(range(len(random_forest_importance)))
plt.bar(importance_plot_x_values,random_forest_importance,orientation='vertical')
plt.xticks(importance_plot_x_values,train_X_column_name,rotation='vertical')
plt.xlabel('Variable')
plt.ylabel('Importance')
plt.title('Variable Importances')
2 完整代码
本文所用完整代码如下。
# -*- coding: utf-8 -*-
"""
Created on Sun Mar 21 22:05:37 2021
@author: fkxxgis
"""
import pydot
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
from pprint import pprint
from sklearn import metrics
from openpyxl import load_workbook
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
# Attention! Data Partition
# Attention! One-Hot Encoding
train_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Train.csv'
test_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Test.csv'
write_excel_path='G:/CropYield/03_DL/05_NewML/ParameterResult_ML.xlsx'
tree_graph_dot_path='G:/CropYield/03_DL/05_NewML/tree.dot'
tree_graph_png_path='G:/CropYield/03_DL/05_NewML/tree.png'
random_seed=44
random_forest_seed=np.random.randint(low=1,high=230)
# Data import
train_data=pd.read_csv(train_data_path,header=0)
test_data=pd.read_csv(test_data_path,header=0)
# Separate independent and dependent variables
train_Y=np.array(train_data['Yield'])
train_X=train_data.drop(['ID','Yield'],axis=1)
train_X_column_name=list(train_X.columns)
train_X=np.array(train_X)
test_Y=np.array(test_data['Yield'])
test_X=test_data.drop(['ID','Yield'],axis=1)
test_X=np.array(test_X)
# Search optimal hyperparameter
n_estimators_range=[int(x) for x in np.linspace(start=50,stop=3000,num=60)]
max_features_range=['auto','sqrt']
max_depth_range=[int(x) for x in np.linspace(10,500,num=50)]
max_depth_range.append(None)
min_samples_split_range=[2,5,10]
min_samples_leaf_range=[1,2,4,8]
bootstrap_range=[True,False]
random_forest_hp_range={'n_estimators':n_estimators_range,
'max_features':max_features_range,
'max_depth':max_depth_range,
'min_samples_split':min_samples_split_range,
'min_samples_leaf':min_samples_leaf_range
# 'bootstrap':bootstrap_range
}
pprint(random_forest_hp_range)
random_forest_model_test_base=RandomForestRegressor()
random_forest_model_test_random=RandomizedSearchCV(estimator=random_forest_model_test_base,
param_distributions=random_forest_hp_range,
n_iter=200,
n_jobs=-1,
cv=3,
verbose=1,
random_state=random_forest_seed
)
random_forest_model_test_random.fit(train_X,train_Y)
best_hp_now=random_forest_model_test_random.best_params_
pprint(best_hp_now)
# Grid Search
random_forest_hp_range_2={'n_estimators':[60,100,200],
'max_features':[12,13],
'max_depth':[350,400,450],
'min_samples_split':[2,3] # Greater than 1
# 'min_samples_leaf':[1,2]
# 'bootstrap':bootstrap_range
}
random_forest_model_test_2_base=RandomForestRegressor()
random_forest_model_test_2_random=GridSearchCV(estimator=random_forest_model_test_2_base,
param_grid=random_forest_hp_range_2,
cv=3,
verbose=1,
n_jobs=-1)
random_forest_model_test_2_random.fit(train_X,train_Y)
best_hp_now_2=random_forest_model_test_2_random.best_params_
pprint(best_hp_now_2)
# Build RF regression model with optimal hyperparameters
random_forest_model_final=random_forest_model_test_2_random.best_estimator_
# Predict test set data
random_forest_predict=random_forest_model_test_2_random.predict(test_X)
random_forest_error=random_forest_predict-test_Y
# Draw test plot
plt.figure(1)
plt.clf()
ax=plt.axes(aspect='equal')
plt.scatter(test_Y,random_forest_predict)
plt.xlabel('True Values')
plt.ylabel('Predictions')
Lims=[0,10000]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims,Lims)
plt.grid(False)
plt.figure(2)
plt.clf()
plt.hist(random_forest_error,bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
# Verify the accuracy
random_forest_pearson_r=stats.pearsonr(test_Y,random_forest_predict)
random_forest_R2=metrics.r2_score(test_Y,random_forest_predict)
random_forest_RMSE=metrics.mean_squared_error(test_Y,random_forest_predict)**0.5
print('Pearson correlation coefficient is {0}, and RMSE is {1}.'.format(random_forest_pearson_r[0],
random_forest_RMSE))
# Save key parameters
excel_file=load_workbook(write_excel_path)
excel_all_sheet=excel_file.sheetnames
excel_write_sheet=excel_file[excel_all_sheet[0]]
excel_write_sheet=excel_file.active
max_row=excel_write_sheet.max_row
excel_write_content=[random_forest_pearson_r[0],random_forest_R2,random_forest_RMSE,
random_seed,random_forest_seed]
for i in range(len(excel_write_content)):
exec("excel_write_sheet.cell(max_row+1,i+1).value=excel_write_content[i]")
excel_file.save(write_excel_path)
# Draw decision tree visualizing plot
random_forest_tree=random_forest_model_final.estimators_[5]
export_graphviz(random_forest_tree,out_file=tree_graph_dot_path,
feature_names=train_X_column_name,rounded=True,precision=1)
(random_forest_graph,)=pydot.graph_from_dot_file(tree_graph_dot_path)
random_forest_graph.write_png(tree_graph_png_path)
# Calculate the importance of variables
random_forest_importance=list(random_forest_model_final.feature_importances_)
random_forest_feature_importance=[(feature,round(importance,8))
for feature, importance in zip(train_X_column_name,
random_forest_importance)]
random_forest_feature_importance=sorted(random_forest_feature_importance,key=lambda x:x[1],reverse=True)
plt.figure(3)
plt.clf()
importance_plot_x_values=list(range(len(random_forest_importance)))
plt.bar(importance_plot_x_values,random_forest_importance,orientation='vertical')
plt.xticks(importance_plot_x_values,train_X_column_name,rotation='vertical')
plt.xlabel('Variable')
plt.ylabel('Importance')
plt.title('Variable Importances')
以上就是Python实现随机森林RF模型超参数的优化详解的详细内容,更多关于Python随机森林模型超参数优化的资料请关注我们其它相关文章!
相关推荐
-
python 随机森林算法及其优化详解
前言 优化随机森林算法,正确率提高1%~5%(已经有90%+的正确率,再调高会导致过拟合) 论文当然是参考的,毕竟出现早的算法都被人研究烂了,什么优化基本都做过.而人类最高明之处就是懂得利用前人总结的经验和制造的工具(说了这么多就是为偷懒找借口.hhhh) 优化思路 1. 计算传统模型准确率 2. 计算设定树木颗数时最佳树深度,以最佳深度重新生成随机森林 3. 计算新生成森林中每棵树的AUC,选取AUC靠前的一定百分比的树 4. 通过计算各个树的数据相似度,排除相似度超过设定值且AUC较小的树
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,
-
Python实现的随机森林算法与简单总结
本文实例讲述了Python实现的随机森林算法.分享给大家供大家参考,具体如下: 随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器.算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样: *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根.自然对数等: *每棵树完全生成,不进行剪枝: *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即各棵树的叶节点的平均) 著名的python机器学习包scikit learn的文档对此算法有
-
python实现H2O中的随机森林算法介绍及其项目实战
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator H2ORandomForestEstimator 的常用方法和参数介绍: (一)建模方法: model =H2ORandomForestEstimator(ntrees=n,max_depth =m) model.train(x=random_pv.names,y='Catrgory',train
-

Python机器学习利用随机森林对特征重要性计算评估
目录 1 前言 2 随机森林(RF)简介 3 特征重要性评估 4 举个例子 5 参考文献 1 前言 随机森林是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能,因此,随机森林也被誉为"代表集成学习技术水平的方法". 2 随机森林(RF)简介 只要了解决策树的算法,那么随机森林是相当容易理解的.随机森林的算法可以用如下几个步骤概括: 1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个
-
Python实现随机森林回归与各自变量重要性分析与排序
目录 1 代码分段讲解 1.1 模块与数据准备 1.2 特征与标签分离 1.3 RF模型构建.训练与预测 1.4 预测图像绘制.精度衡量指标计算与保存 1.5 决策树可视化 1.6 变量重要性分析 2 完整代码 本文介绍在Python环境中,实现随机森林(Random Forest,RF)回归与各自变量重要性分析与排序的过程. 其中,关于基于MATLAB实现同样过程的代码与实战,大家可以点击查看MATLAB实现随机森林(RF)回归与自变量影响程度分析这篇文章. 本文分为两部分,第一部分为代码的分
-
Python实现孤立随机森林算法的示例代码
目录 1 简介 2 孤立随机森林算法 2.1 算法概述 2.2 原理介绍 2.3 算法步骤 3 参数讲解 4 Python代码实现 5 结果 1 简介 孤立森林(isolation Forest)是一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或基尼指数来选择. 2 孤立随机森林算法 2.1 算法概述 Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好
-
Python实现随机森林RF模型超参数的优化详解
目录 1 代码分段讲解 1.1 数据与模型准备 1.2 超参数范围给定 1.3 超参数随机匹配择优 1.4 超参数遍历匹配择优 1.5 模型运行与精度评定 2 完整代码 本文介绍基于Python的随机森林(Random Forest,RF)回归代码,以及模型超参数(包括决策树个数与最大深度.最小分离样本数.最小叶子节点样本数.最大分离特征数等)自动优化的代码. 本文是在上一篇文章Python实现随机森林RF并对比自变量的重要性的基础上完成的,因此本次仅对随机森林模型超参数自动择优部分的代码加以详
-
python回归分析逻辑斯蒂模型之多分类任务详解
目录 逻辑斯蒂回归模型多分类任务 1.ovr策略 2.one vs one策略 3.softmax策略 逻辑斯蒂回归模型多分类案例实现 逻辑斯蒂回归模型多分类任务 上节中,我们使用逻辑斯蒂回归完成了二分类任务,针对多分类任务,我们可以采用以下措施,进行分类. 我们以三分类任务为例,类别分别为a,b,c. 1.ovr策略 我们可以训练a类别,非a类别的分类器,确认未来的样本是否为a类: 同理,可以训练b类别,非b类别的分类器,确认未来的样本是否为b类: 同理,可以训练c类别,非c类别的分类器,确认
-
基于Python中单例模式的几种实现方式及优化详解
单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. 比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息.如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪
-
MySQL 5.5.x my.cnf参数配置优化详解
一直有耳闻MySQL5.5的性能非常NB,所以近期打算测试一下,方便的时候就把bbs.kaoyan.com升级到这个版本的数据库.今天正好看到一篇有关my.cnf优化的总结,虽然还没经过我自己的实践检验,但从文章内容来说已经写的很详细了(当然,事实上下面这篇文章很多地方只是翻译了my.cnf原始配置文件的说明,呵呵),所以特地转载收藏一下,大家在对mysql服务器进行优化的时候可以作为参考,并根据实际情况对其中的一些参数进行调整.(特别备注:以下原文中有些参数事实上不适用于mysql5.5,不知
-
对python的unittest架构公共参数token提取方法详解
额...每个请求都有token值的传入,但是token非常易变,一旦变化,所有的接口用例都得改一遍token,工作量太大了... 那么有没有一种方法能把token提取出来,作为一个全局变量,作为一个参数,从而牵一发而动全身呢?? 经过探索,具体方案如下 先定义一个全局变量token类型为string 然后把请求链接定义一个变量类型为string 然后定义第三个变量=前两个变量相加 然后requests直接传第三个变量就行了 具体代码如下: class Test(unittest.TestCase
-
关于python中plt.hist参数的使用详解
如下所示: matplotlib.pyplot.hist( x, bins=10, range=None, normed=False, weights=None, cumulative=False, bottom=None, histtype=u'bar', align=u'mid', orientation=u'vertical', rwidth=None, log=False, color=None, label=None, stacked=False, hold=None, **kwarg
-
python 正则表达式参数替换实例详解
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. 本章节主要介绍python 正则表达式参数替
-
Python sep参数使用方法详解
这篇文章主要介绍了Python sep参数使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python中sep不是函数,它是print函数的一个参数,用来定义输出数据之间的间隔符号. 具体用法如下: 同时打印多个字符串的时候,每个字符串都会自动默认以空格作为每个字符串之间的间隔. print("abc", "uuu", "oop") # abc uuu oop 如果在多个字符串的最后
-
python命名关键字参数的作用详解
1.说明 *,nkw表示命名关键字参数,是用户想输入的关键字参数名称,定义方式是在nkw前追加*, 2.作用 限制调用者传达的参数名称. 3.实例 # 命名关键字参数 def print_info4(name, age=18, height=178, *, weight, **kwargs): ''' 打印信息函数4,加入命名关键字参数 :param name: :param age: :param height: :param weight: :param kwargs: :return: '