MySQL Buffer Pool如何提高页的访问速度
目录
- 如何提高SQL执行速度?
- Buffer Pool的数据结构是怎样的?
- 改进后的链表是如何工作的?
- Buffer Pool的相关参数
- 参考博客
如何提高SQL执行速度?
当我们想更新某条数据的时候,难道是从磁盘中加载出来这条数据,更新后再持久化到磁盘中吗?
如果这样搞的话,那一条sql的执行过程可太慢了,因为对一个大磁盘文件的读写操作是要耗费几百万毫秒的
真实的执行过程是,当我们想更新或者读取某条数据的时候,会把对应的页加载到Buffer Pool缓冲池中(Buffer Pool本质上就是一块连续的内存空间)
默认为128m,当然为了提高系统的并发度,你可以把这个值设大一点
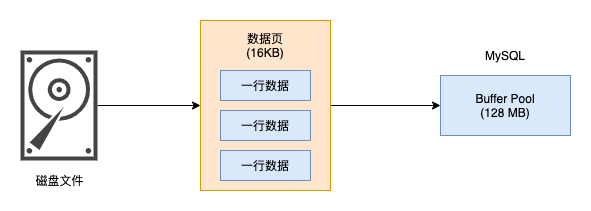
之所以加载页到Buffer Pool中,是考虑到当你使用这个页的数据时,这个页的其他数据使用到的概率页很大,随机IO的耗时很长,所以多加载一点数据到Buffer Pool
Buffer Pool的数据结构是怎样的?

Buffer Pool中主要分为2部分,缓存页和描述数据,MySQL从磁盘加载的数据页会放入缓存页中
对于每个缓存页都有对应的描述信息,比如数据页所属于表空间,数据页的编号等
Buffer Pool中的描述数据大概相当于缓存页大小的5%左右,这部分内存是不包含在Buffer Pool中的
当更新数据的时候,如果对应的页在Buffer Pool中,则直接更新Buffer Pool中的页即可,对应的页不在Buffer Pool中时,才会从磁盘加载对应的页到Buffer Pool,然后再更新,此时Buffer Pool中的页和磁盘中的页数据是不一致的,被称为脏页。这些脏页是要被刷回到磁盘中的
这些脏页是多会刷回到磁盘中的? 有如下几个时机
Buffer Pool不够用了,要给新加载的页腾位置了,所以会利用改进的后的LRU算法,将一些脏页刷回磁盘后台线程会在MySQL不繁忙的时候,将脏页刷到磁盘中redolog写满时(redolog的作用后面会提到)数据库关闭时会将所有脏页刷回到磁盘
这样搞,效率是不是高很多了?
当需要更新的数据所在的页已经在Buffer Pool中时,只需要操作内存即可,效率不是一般的高
我们怎么知道哪些缓存页是空闲的?
MySQL为Buffer Pool设计了一个free链表,它是一个双向链表,每个节点就是一个空闲缓存页的描述数据

我们如何知道缓存页是否被加载到内存了?
很简单啊,建立一个哈希表不就行了,key为表空间号+页号,value为对应的缓存页
当把数据页读取到缓存页的时候,对应的描述数据会从free链表放到flush链表

当不停的把磁盘上的数据页加载到缓存页,free链表不停的移除空闲缓存页,当free链表上没有空闲缓存页,当你还要加载数据页到缓存页时,该怎么办呢?
如果要淘汰一些数据,该淘汰谁呢?
引入LRU链表来判断哪些缓存页是不常用的?
缓存淘汰策略在很多中间件中会被用到,其中用的最多的就是LRU算法,当每访问一个缓存页的时候就把缓存页移到链表的头部

我们只需要把链表尾部的缓存页刷到内存中,然后加载新的数据页即可。
这样的方式看似很完美,但是在实际运行过程中会存在巨大的隐患
首先就是mysql的预读,
哪些情况会触发MySQL的预读
当发生全表扫描的时候(比如 select * from users),会导致表里的数据页都加载到 Buffer Pool 中去。这样有可能导致LRU链表前面一大串数据页都是全表扫描加载进来的数据页,但是如果这次全表扫描过后后续几乎没用到这个表里面的数据呢?
这样就会导致经常被扫描的缓存页被淘汰了,留下的都是全表扫描加载进来的缓存页
为了解决这个问题,LRU链表改进了一下,采用了冷热分离的思想。
即LRU链表会被拆分为2部分,一部分是冷数据,一部分是热数据

改进后的链表是如何工作的?
当数据页第一次被加载到缓存的时候,缓存页会被放到冷数据区域的链表头部。
那么冷数据区的缓存页多会放到热数据区呢?
你可能会想,当冷数据区的缓存页再次被访问时,就放到热数据区可以不?
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.02 sec)
当多线程访问Buffer Pool中的各种链表时,需要加锁保证线程安全,影响请求的处理速度,此时我们就可以将Buffer Pool分为多个,多线程访问事不会互相影响,提高了请求的处理速度
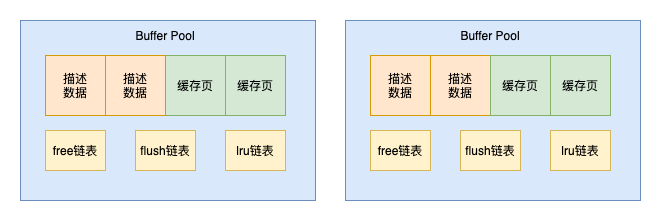
在MySQL 5.7.5之前,Buffer Pool不能动态扩展,动态扩展。为了增加动态扩展就增加了chunk机制,有兴趣的小伙伴可以看看其他资料,就不多做分析了

Buffer Pool的相关参数
学习了这么多理论知识,那么Buffer Pool应该调多大呢?
执行如下命令可以得到Buffer Pool的大小,名字,以及chunk的大小
SHOW VARIABLES LIKE '%innodb_buffer%'

innodb_buffer_pool_size的单位是字节,我们转成MB来看一下,默认是128M
-- 128m SELECT @@innodb_buffer_pool_size / 1024 / 1024
执行如下命令可以得到buffer_pool的当前使用状态
SHOW STATUS LIKE '%buffer_pool%';
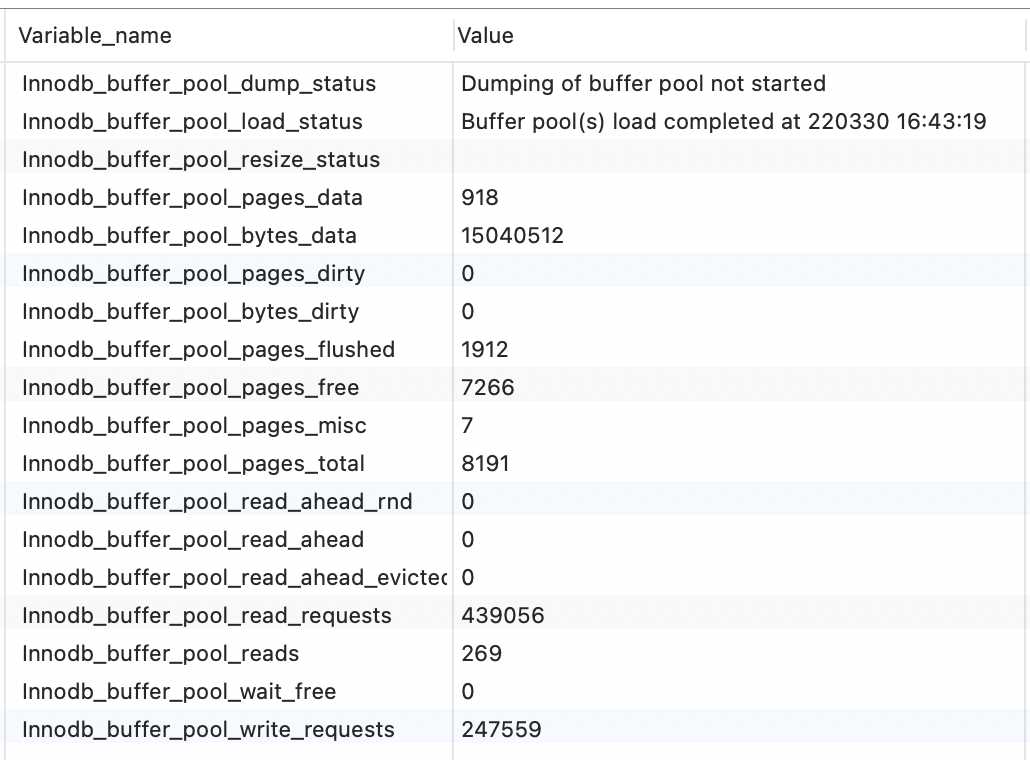
我们挑一些重要的参数来分析一下
- Innodb_buffer_pool_read_requests:读的请求次数
- Innodb_buffer_pool_reads:从物理磁盘中读取数据的次数
- Innodb_buffer_pool_pages_data:有数据的缓存页
- Innodb_buffer_pool_pages_free:空闲缓存页
- Innodb_buffer_pool_pages_total:总共的缓存页
Buffer Pool 读缓存命中率:
(Innodb_buffer_pool_read_requests - Innodb_buffer_pool_reads) / (Innodb_buffer_pool_read_requests) *100%
Buffer Pool 脏页比率:
Innodb_buffer_pool_pages_dirty / (Innodb_buffer_pool_pages_data)*100%
Buffer Pool 使用率:
innodb_buffer_pool_pages_data / ( innodb_buffer_pool_pages_data + innodb_buffer_pool_pages_free ) * 100%
缓存命中率比较低可以增大Buffer Pool的大小
使用率比较高时可以增大Buffer Pool的大小
你也可以执行如下命令获取一些关于Buffer Pool的其他参数,本篇文章就不多做介绍了
show engine innodb status;
参考博客
[1]https://www.cnblogs.com/FengGeBlog/p/10283095.html
[2]https://m.starcto.com/mysql/128.html
到此这篇关于MySQL Buffer Pool如何提高页的访问速度的文章就介绍到这了,更多相关MySQL Buffer Pool访问速度内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL的查询缓存和Buffer Pool
一.Caches - 查询缓存 下图是MySQL官网给出的:MySQL架构体系图. 人们常说的查询缓存就是下图中的Cache部分. 如果将MySQL分成 Server层和存储引擎层两大部分,那么Caches位于Server层. 另外你还得知道: 当一个SQL打向MySQL Server之后,MySQL Server首选会从查询缓存中查看是否曾经执行过这个SQL,如果曾经执行过的话,之前执行的查询结果会以Key-Value的形式保存在查询缓存中.key是SQL语句,value是查询结果.我们将这个
-

深入理解MySQL中MVCC与BufferPool缓存机制
目录 一.MVCC机制 undo日志版本链与read-view机制 版本链比对规则 二.BufferPool机制 三.总结 一.MVCC机制 MVCC(Multi Version Concurrency Control),MySQL(默认)RR隔离级别就是通过该机制来保证的,对一行数据的读与写两个操作默认是不会通过加锁互斥来保证隔离性的 串行化隔离级别是为了保证较高的隔离性,是通过将所有操作加锁互斥来实现的 MySQL在RC隔离级别和RR隔离级别下都实现了MVCC机制 RC每次查询都会创建一个r
-
详解MySQL中的缓冲池(buffer pool)
Mysql 中数据是要落盘的,这点大家都知道.读写磁盘速度是很慢的,尤其和内存比起来更是没的说.但是,我们平时在执行 SQL 时,无论写操作还是读操作都能很快得到结果,并没有预想中的那么慢. 可能你会说我有索引啊,有索引当然快了.但是铁子,索引文件也是存储在磁盘上的,查找过程会产生磁盘 I/O.如果同时对某行数据进行多次操作,那岂不是要重复产生很多次磁盘 IO 吗? 可能你想到了,那我把数据存在内存里不就可以了吗?内存速度比磁盘快,这准没毛病.没错,那该怎么存呢? 这就是我们今天所要讲的主题--
-
MySql InnoDB存储引擎之Buffer Pool运行原理讲解
目录 1. 前言 2. Buffer Pool 2.1 Buffer Pool结构 2.2 Free链表 2.3 缓冲页哈希表 2.4 Flush链表 2.5 LRU链表 2.6 多个实例 2.7 Buffer Pool状态信息 3. 总结 1. 前言 我们已经知道,对于InnoDB存储引擎而言,页是磁盘和内存交互的基本单位.哪怕你要读取一条记录,InnoDB也会将整个索引页加载到内存.哪怕你只改了1个字节的数据,该索引页就是脏页了,整个索引页都要刷新到磁盘.InnoDB是基于磁盘的存储引擎,如
-
MySQL中Buffer Pool内存结构详情
目录 1.回顾一下Buffer Pool是个什么东西? 1.1 增删改直接操作的是内存还是磁盘? 1.2 数据库崩溃了,内存中数据丢了怎么办? 1.3 Buffer Pool的一句话总结 2.Buffer Pool这个内存数据结构到底长个什么样子? 2.1 如何配置MySQL的Buffer Pool的大小? 2.2 数据页 2.3 磁盘上的数据页和Buffer Pool中的数据页是如何对应起来的? 2.4 缓存页描述信息 1.回顾一下Buffer Pool是个什么东西? 1.1 增删改直接操作的
-
mysql的Buffer Pool存储及原理
一.前言 1.buffer pool是什么 咱们在使用mysql的时候,比如很简单的select * from table;这条语句,具体查询数据其实是在存储引擎中实现的,数据库中的数据实际上最终都是要存放在磁盘文件上的,如果每次查询都直接从磁盘里面查询,这样势必会很影响性能,所以一定是先把数据从磁盘中取出,然后放在内存中,下次查询直接从内存中来取.但是一台机器中往往不是只有mysql一个进程在运行的,很多个进程都需要使用内存,所以mysql中会有一个专门的内存区域来处理这些数据,这个专门为my
-
MySQL之Innodb_buffer_pool_size设置方式
目录 Innodb_buffer_pool_size设置方式 缓冲池相关参数说明 合理的设置缓存池相关参数 设置innodb_buffer_pool_size参数 Innodb_buffer_pool_size设置方式 缓冲池是用于存储InnoDB表,索引和其他辅助缓冲区的缓存数据的内存区域.缓冲池的大小对于系统性能很重要.更大的缓冲池可以减少磁盘I/O来多次访问同一表数据.在专用数据库服务器上,可以将缓冲池大小设置为计算机物理内存大小的80% 缓冲池相关参数说明 1)系统变量参数 Innodb
-
MySQL中读页缓冲区buffer pool详解
目录 Buffer pool buffer pool组成 free链表 缓存页的哈希处理 flush链表的管理 LRU链表 刷新脏页 多个buffer pool实例 动态调整buffer pool大小 查看buffer pool具体的信息 Buffer pool 我们都知道我们读取页面是需要将其从磁盘中读到内存中,然后等待CPU对数据进行处理.我们直到从磁盘中读取数据到内存的过程是十分慢的,所以我们读取的页面需要将其缓存起来,所以MySQL有这个buffer pool对页面进行缓存. 首先MyS
-
mysqldump造成Buffer Pool污染的研究
前言: 最近Oracle MySQL在其官方Blog上贴出了 5.6中一些变量默认值的修改.其中innodb_old_blocks_time 的默认值从0替换成了1000(即1s) 关于该参数的作用摘录如下: how long in milliseconds (ms) a block inserted into the old sublist must stay there after its first access before it can be moved to the new subl
-
MySQL Buffer Pool如何提高页的访问速度
目录 如何提高SQL执行速度? Buffer Pool的数据结构是怎样的? 改进后的链表是如何工作的? Buffer Pool的相关参数 参考博客 如何提高SQL执行速度? 当我们想更新某条数据的时候,难道是从磁盘中加载出来这条数据,更新后再持久化到磁盘中吗? 如果这样搞的话,那一条sql的执行过程可太慢了,因为对一个大磁盘文件的读写操作是要耗费几百万毫秒的 真实的执行过程是,当我们想更新或者读取某条数据的时候,会把对应的页加载到Buffer Pool缓冲池中(Buffer Pool本质上就是一
-
mysql的Buffer Pool存储及原理解析
目录 一.前言 1.buffer pool是什么 2.buffer pool的工作流程 3.buffer pool缓冲池和查询缓存(query cache) 二.buffer pool的内存数据结构 1.数据页概念 2.那么怎么识别数据在哪个缓存页中 3.buffer pool的初始化与配置 3.1.初始化 3.2.buffer pool的配置 3.3.Buffer Pool Size 设置和生效过程 3.4.Buffer Pool Instances 3.5.SHOW ENGINE INNOD
-
MySQL的Flush-List和脏页的落盘机制
一.回顾 MySQL启动后Buffer Pool会初始化.Buffer Pool也会初始化好N多个空白的缓存页,以及它们的描述数据会被组织成LRU链表以及FreeList 双向链表. 这时你从磁盘中读取一个数据页,会先从Free List中找出一个空闲缓存页的描述信息,然后将你读出的数据页中加载进缓存页中.同时将缓存页的描述信息从Free List中剔除,此外该描述信息块还会被维护进LRU链表中. 数据页被加载进Buffer Pool后你就可以对其进行变更操作了. 二.Flush List 为了