Rust语言中的String和HashMap使用示例详解
目录
- String
- 新建字符串
- 更新字符串
- 使用 + 运算符或 format! 宏拼接字符串
- 索引字符串
- 字符串 slice
- 遍历字符串
- HashMap
- 新建 HashMap
- HashMap 和 ownership
- 访问 HashMap 中的值
- 更新 HashMap
- 直接覆盖
- 新插入
- 更新旧值
- 总结
String
字符串是比很多开发者所理解的更为复杂的数据结构。加上 UTF-8 的不定长编码等原因,Rust 中的字符串并不如其它语言中那么好理解。
Rust 的核心语言中只有一种字符串类型:str。字符串 slice,它通常以被借用的形式出现:&str 是一些储存在别处的 UTF-8 编码字符串数据的引用。而 String 的类型是由标准库提供的,而没有写进核心语言部分,它是可增长的、可变的、有所有权的、UTF-8 编码的字符串类型。
Rust 标准库中还包含一系列其他字符串类型,比如 OsString、OsStr、CString 和 CStr。相关库 crate 还会提供更多储存字符串数据的数据类型。这些字符串类型能够以不同的编码,或者内存表现形式上以不同的形式,来存储文本内容。
新建字符串
- String::new()函数
- to_string()方法
let data = "initial contents"; let s = data.to_string(); // 或者 let s = String::from(data); // 该方法也可直接用于字符串字面量: let s = "initial contents".to_string();
更新字符串
String 的大小可以增加,其内容也可以改变。另外,还可以使用 + 运算符或 format! 宏来拼接 String 值。
- push_str()
- push()
let mut s = String::from("foo");
let t = String::from("bar");
s.push_str(&t);
// push 方法被定义为获取一个单独的字符作为参数,并附加到 String 中
let mut l = String::from("lo");
l.push('l');
pub fn push_str(&mut self, string: &str) 方法不会获得字符串的所有权。另外值得一提的是,t 是 &String 类型,而 push_str 方法需要的是 &str 类型的参数。为什么这段代码能够正常编译呢?这里就涉及到了 解引用强制转换(deref coercion),我们将在后面的文章中介绍它。
使用 + 运算符或 format! 宏拼接字符串
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2;
你可以把他理解成 C++ 的运算符重载。在 Rust 中, + 的实现可能是 fn add(self, s: &str) -> String 这样一个方法。
s1 的所有权将被移动到 add 调用中
如果想要级联多个字符串,使用 + 就变得麻烦了。这时候可以使用 format! 宏:
let s1 = String::from("hello");
let s2 = String::from("the");
let s3 = String::from("world");
let s = format!("{}-{}-{}", s1, s2, s3);
索引字符串
在其他语言中,通过索引来引用字符串中的某个单独字符是很常见的操作。但在 Rust 中,你可能会遇到问题:
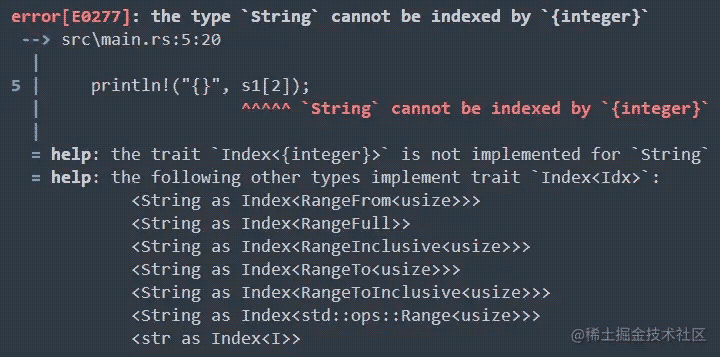
这主要是因为:
- UTF-8 是不定长编码,而 String 的实现是基于
Vec<u8>的封装:数组中每一个元素都是一个字节,但 UTF-8 中每一个汉字(或字符)都可能由一到四个字节组成 - 索引操作预期总是需要常数时间 (O(1))。但是对于
String不可能保证这样的性能,因为 Rust 必须从开头到索引位置遍历来确定有多少有效的字符。
字符串 slice
如果你真的希望使用索引创建字符串 slice 时,Rust 会要求你明确字符串范围。这时你需要一个字符串 slice,使用 [] 和一个 range 来创建含特定字节的字符串 slice:
fn main() {
let s1 = String::from("你好,");
println!("{}", &s1[0..3]); // 你
}
如果获取 &s1[0..1] ,Rust 在运行时会 panic。因此,你应该谨慎地使用这个操作,因为这么做可能会使你的程序崩溃。
遍历字符串
可以使用 chars() 方法获取该字符串的字母数组。
fn main() {
let s1 = String::from("你好,");
let s2 = String::from("世界!");
let s3 = s1 + &s2;
for char in s3.chars() {
println!("{}", char);
}
}
HashMap
另外一个常用集合类型是 哈希 map(hash map)。HashMap<K, V> 类型储存了一个键类型 K 对应一个值类型 V 的映射。它通过一个 哈希函数(hashing function)来实现映射,决定如何将键和值放入内存中。
哈希 map 适用于需要任何类型作为键来寻找数据的情况,而不是像 vector 那样通过索引。
新建 HashMap
使用new 创建一个空的 HashMap,并使用 insert 增加元素:
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
必须首先 use 标准库中集合部分的 HashMap。在这上面介绍的三个常用集合中,HashMap 是最不常用的,所以并没有被 prelude 自动引用。标准库中对 HashMap 的支持也相对较少,例如,并没有内建的构建宏。
像 vector 一样,哈希 map 将它们的数据储存在堆上;哈希 map 是同质的:所有的键必须是相同类型,值也必须都是相同类型。
另一个构建哈希 map 的方法是使用一个元组的 vector 的 collect 方法:
use std::collections::HashMap;
let teams = vec![String::from("Blue"), String::from("Yellow")];
let initial_scores = vec![10, 50];
let scores: HashMap<_, _> = teams.iter().zip(initial_scores.iter()).collect();
HashMap 和 ownership
- 对于像
i32这样的实现了Copytrait 的类型,其值可以拷贝进哈希 map。 - 对于像
String这样拥有所有权的值,其值将被移动而哈希 map 会成为这些值的所有者。
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// 此时 field_name 和 field_value 被移动到了 map 中
如果将值的引用插入哈希 map,这些值本身将不会被移动进哈希 map。但是这些引用指向的值必须至少在哈希 map 有效时也是有效的。此时就涉及到生命周期的内容。
访问 HashMap 中的值
可以通过 get 方法并提供对应的键来从哈希 map 中获取值:
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name);
get 返回 Option<V>,所以结果被装进 Some;如果某个键在哈希 map 中没有对应的值,get 会返回 None。当获取到结果后,就需要使用到 match 进行匹配。
更新 HashMap
在更新前,我们需要考虑以下几种情况:
- 已有
key-value,直接覆盖 - 只在没有
key-value时插入 - 利用已有
key-value来更新
直接覆盖
insert() 方法:
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
println!("{:?}", scores);
新插入
利用 entry() 函数返回的枚举值,调用 or_insert() 方法进行处理:
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{:?}", scores);
Entry 的 or_insert 方法在键对应的值存在时就返回这个值的可变引用,如果不存在则将参数作为新值插入并返回新值的可变引用。
更新旧值
or_insert 方法事实上会返回这个键的值的一个可变引用(&mut V):
// 统计字符串中某个单词的出现次数
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0); // 之前不存在对应关系就初始化并置计数器为0
*count += 1; // 每次计数器加一
}
println!("{:?}", map);
这里我们将这个可变引用储存在 count 变量中,所以为了赋值必须首先使用星号( * )解引用 count。这个可变引用在 for 循环的结尾离开作用域,这样所有这些改变都是安全的并符合借用规则。
总结
掌握了 Rust 中最常用的三种集合类型,现在你已经可以开始进行一些包含复杂逻辑的编程了!在此过程中你可能会遇到很多错误。因此接下来我将介绍错误处理与模式匹配,并开始介绍一些测试工具和自动化测试的内容,更多关于Rust String HashMap使用的资料请关注我们其它相关文章!
相关推荐
-

Rust 入门之函数和注释实例详解
目录 写在前面 函数 参数 语句和表达式 返回值 注释 写在前面 今天我们来学习 Rust 中的函数,最后会捎带介绍一下如何在 Rust 中写注释.也是比较轻量级的一节,大家快速过一下即可. 函数 函数本身是各个语言都支持的类型,我们此前已经多次使用 fn main() 这个函数来承载业务逻辑,fn 可以用来声明一个函数,而 main 函数跟其他语言一样,可以理解为程序启动的[起点],一切逻辑从这里开始. Rust 本身的命名规范是[snake case],即下划线 + 小写,这个其实各个语言都
-
Rust use关键字妙用及模块内容拆分方法
目录 前言 1.rust 中的use关键字 1.1.将模块标识符引入当前作用域 1.2.use特点与习惯用法 1.3.使用pub use 重新导出名称 1.4.使用外部包(package)以及标准库 1.5.使用嵌套路径清理大量 use 语句 1.6.通配符 * 2.模块内容拆分 前言 书接上文,本篇补充rust 组织管理中模块的细节知识,比如模块拆分.此外介绍use关键字的习惯用法,快速引用自定义模块内容或标准库,以此优化代码书写. 1.rust 中的use关键字 如果我说use与C/C++中
-
详解Rust中三种循环(loop,while,for)的使用
目录 楔子 loop 循环 while 循环 for 循环 楔子 我们常常需要重复执行同一段代码,针对这种场景,Rust 提供了多种循环(loop)工具.一个循环会执行循环体中的代码直到结尾,并紧接着回到开头继续执行. 而 Rust 提供了 3 种循环:loop.while 和 for,下面逐一讲解. loop 循环 我们可以使用 loop 关键字来指示 Rust 反复执行某一段代码,直到我们显式地声明退出为止. fn main() { loop { println!("
-
Go调用Rust方法及外部函数接口前置
前言 近期 Rust 社区/团队有些变动,所以再一次将 Rust 拉到大多数人眼前. 我最近看到很多小伙伴说的话: Rust 还值得学吗?社区是不是不稳定呀 Rust 和 Go 哪个好? Rust 还值得学吗? 这些问题如果有人来问我,那我的回答是: 小孩子才做选择,我都要! 当然,关于 Rust 和 Go 的问题也不算新,比如之前的一条推文: 我在本篇中就来介绍下如何用 Go 调用 Rust. 当然,这篇中我基本上不会去比较 Go 和 Rust 的功能,或者这种方式的性能之类的,Just fo
-
Rust使用libloader调用动态链接库
目录 引言 main.rs 代码 引言 最近需要使用Rust动态调用动态链接库,本来打算是使用libloading的,但是libloading在调用dll中的函数的时,是必须要在编译时确定参数和return的类型的.但后来发现了libloader这个包包,libloader是基于libloading的,但是操作起来却比libloader方便. 我们先需要一个动态链接库,我们可以使用cargo create project-name --lib创建一个动态链接库的项目,然后修改lib.rs后使用c
-
Rust+React创建富文本编辑器
目录 简介 数据模型 核心逻辑 视图 手动差异化 杂项 总结 简介 在Fiberplane,我们最近遇到了一个有趣的挑战:我们正在使用的富文本编辑器库已经过时了.我们曾经使用Slate.js——一个很好的编辑器——但是当我们为协作编辑实现我们自己的富文本基元时,我们发现我们自己的基元和Slate的数据模型之间的脱节是一个阻碍因素.所以我们开始思考——如果我们建立自己的富文本编辑器(RTE, Rich Text Editor)会怎样? 从一个非常高层次的角度来看,一个富文本编辑器是由两个部分组成的
-
Rust语言中的String和HashMap使用示例详解
目录 String 新建字符串 更新字符串 使用 + 运算符或 format! 宏拼接字符串 索引字符串 字符串 slice 遍历字符串 HashMap 新建 HashMap HashMap 和 ownership 访问 HashMap 中的值 更新 HashMap 直接覆盖 新插入 更新旧值 总结 String 字符串是比很多开发者所理解的更为复杂的数据结构.加上 UTF-8 的不定长编码等原因,Rust 中的字符串并不如其它语言中那么好理解. Rust 的核心语言中只有一种字符串类型:str
-
Java语言中flush()函数作用及使用方法详解
最近在学习io流,发现每次都会出现flush()函数,查了一下其作用,起作用主要如下 //------–flush()的作用--------– 笼统且错误的回答: 缓冲区中的数据保存直到缓冲区满后才写出,也可以使用flush方法将缓冲区中的数据强制写出或使用close()方法关闭流,关闭流之前,缓冲输出流将缓冲区数据一次性写出.flash()和close()都使数据强制写出,所以两种结果是一样的,如果都不写的话,会发现不能成功写出 针对上述回答,给出了精准的回答 FileOutPutStream
-
C语言中access/_access函数的使用实例详解
在Linux下,access函数的声明在<unistd.h>文件中,声明如下: int access(const char *pathname, int mode); access函数用来判断指定的文件或目录是否存在(F_OK),已存在的文件或目录是否有可读(R_OK).可写(W_OK).可执行(X_OK)权限.F_OK.R_OK.W_OK.X_OK这四种方式通过access函数中的第二个参数mode指定.如果指定的方式有效,则此函数返回0,否则返回-1. 在Windows下没有access函
-
Go语言中io.Reader和io.Writer的详解与实现
一.前言 也许对这两个接口和相关的一些接口很熟悉了,但是你脑海里确很难形成一个对io接口的继承关系整天的概貌,原因在于godoc缺省并没有像javadoc一样显示官方库继承关系,这导致了我们对io接口的继承关系记忆不深,在使用的时候还经常需要翻文档加深记忆. 本文试图梳理清楚Go io接口的继承关系,提供一个io接口的全貌. 二.io接口回顾 首先我们回顾一下几个常用的io接口.标准库的实现是将功能细分,每个最小粒度的功能定义成一个接口,然后接口可以组成成更多功能的接口. 最小粒度的接口 typ
-
汇编语言中mov和lea指令的区别详解
指令(instruction)是一种语句,它在程序汇编编译时变得可执行.汇编器将指令翻译为机器语言字节,并且在运行时由 CPU 加载和执行. 一条指令有四个组成部分: 标号(可选) 指令助记符(必需) 操作数(通常是必需的) 注释(可选) 最近在学习汇编语言,过程中遇到很多问题,对此在以后的随笔会逐渐更新,这次谈谈mov,lea指令的区别 一,关于有没有加上[]的问题 1,对于mov指令来说: 有没有[]对于变量是无所谓的,其结果都是取值 如: num dw 2 mov bx,num mov
-
C语言中scanf与scanf_s函数的使用详解
目录 1.scanf_s(是vs提供的函数) 2.scanf(标准的库函数) 3.总结 1.scanf_s(是vs提供的函数) a.代码1 int main() { char a = 0; //scanf_s("%c", &a, 1); scanf_s("%c", &a, sizeof(a)); return 0; } scanf_s有三个参数,最后一个是变量a所占据空间的大小(单位为字节),这里可以写1,也可以写sizeof(a).如果a为整型的话
-
Go语言中Slice常见陷阱与避免方法详解
目录 前言 slice 作为函数 / 方法的参数进行传递的陷阱 slice 通过 make 函数初始化,后续操作不当所造成的陷阱 性能陷阱 内存泄露 扩容 前言 Go 语言提供了很多方便的数据类型,其中包括 slice.然而,由于 slice 的特殊性质,在使用过程中易犯一些错误,如果不注意,可能导致程序出现意外行为.本文将详细介绍 使用 slice 时易犯的一些错误,帮助读者更好的使用 Go 的 slice,避免犯错误. slice 作为函数 / 方法的参数进行传递的陷阱 slice 作为参数
-
R语言中的fivenum与quantile()函数算法详解
fivenum()函数: 返回五个数据:最小值.下四分位数数.中位数.上四分位数.最大值 对于奇数个数字=5,fivenum()先排序,依次返回最小值.下四分位数.中位数.上四分位数.最大值 > fivenum(c(1,12,40,23,13)) [1] 1 12 13 23 40 对于奇数个数字>5,fivenum()先排序,我们可以求取最小值,最大值,中位数.在排序中,最小值与中位数中间,若为奇数,取其中位数为下四分位数,若为偶数,取最中间两个数的平均值为下四分位数:在排序中,中位数与最大
-
C语言中0数组\柔性数组的使用详解
前言: 上次看到一篇面试分享,里面有个朋友说,面试官问了char[0] 相关问题,但是自己没有遇到过,就绕过了这个问题. 我自己在这篇文章下面做了一些回复. 现在我想结合我自己的理解,解释一下这个 char[0] C语言柔性数组的问题. 0数组和柔性数组的介绍 0数组顾名思义,就是数组长度定义为0,我们一般知道数组长度定义至少为1才会给它分配实际的空间,而定义了0的数组是没有任何空间,但是如果像上面的结构体一样在最后一个成员定义为零数组,虽然零数组没有分配的空间,但是它可以当作一个偏移量,因为数
-
C语言中typedef的用法以及#define区别详解
目录 1.简洁定义 2.为已有类型起别名 为字符数组起别名 为指针起别名 3.typedef 和 #define 的区别 总结 1.简洁定义 C语言允许为一个数据类型起一个新的别名,就像给人起"绰号"一样.而编程中起别名,是为了编程人员编程方便,例如: 定义如下结构体 struct stu { int ID; char name[20]; float score[3]; char *data; }; 要想定义一个结构体变量就得这样写: struct stu Marry://Marry是