Java 流处理之收集器详解
目录
- 收集所有记录的 列1 值,以列表形式存储结果
- 收集所有记录的 列1 值,且去重,以集合形式存储
- 收集记录的 列2 值和 列3 值的对应关系,以字典形式存储
- 收集所有记录中 列3 值最大的记录
- 收集所有记录中 列3 值的总和
- 创建一个中间结果容器
- 逐一遍历流中的每个元素,处理完成之后,添加到中间结果
- 中间结果转换成最终结果
- combiner()是做什么的?
- characteristics()是什么的?
- 完整代码
Java 流(Stream)处理操作完成之后,我们可以收集这个流中的元素,使之汇聚成一个最终结果。这个结果可以是一个对象,也可以是一个集合,甚至可以是一个基本类型数据。
以记录 Record 为例:
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Record {
private String col1;
private String col2;
private int col3;
}
记录 Record 包含三个属性:列1(col1)、列2(col2)和 列3(col3)。
创建四个记录实例:
Record r1 = new Record("a", "1", 1);
Record r2 = new Record("a", "2", 2);
Record r3 = new Record("b", "3", 3);
Record r4 = new Record("c", "4", 4);
添加到列表:
List<Record> records = new ArrayList<>(); records.add(r1); records.add(r2); records.add(r3); records.add(r4);
收集所有记录的 列1 值,以列表形式存储结果
List<String> col1List = records.stream()
.map(Record::getCol1)
.collect(Collectors.toList());
log.info("col1List: {}", Json.toJson(col1List));
输出结果:
col1List: ["a","a","b","c"]
收集所有记录的 列1 值,且去重,以集合形式存储
Set<String> col1Set = records.stream()
.map(Record::getCol1)
.collect(Collectors.toSet());
log.info("col1Set: {}", Json.toJson(col1Set));
输出结果:
col1Set: ["a","b","c"]
收集记录的 列2 值和 列3 值的对应关系,以字典形式存储
Map<String, Integer> col2Map = records.stream()
.collect(Collectors.toMap(Record::getCol2, Record::getCol3));
log.info("col2Map: {}", Json.toJson(col2Map));
输出结果:
col2Map: {"1":1,"2":2,"3":3,"4":4}
记录的 列2 不能有重复值,否则会抛出 Duplicate key 异常。
收集所有记录中 列3 值最大的记录
Record max = records.stream()
.collect(Collectors.maxBy(Comparator.comparing(Record::getCol3)))
.orElse(null);
log.info("max: {}", Json.toJson(max));
输出结果:
max: {"col1":"c","col2":"4","col3":4}
收集所有记录中 列3 值的总和
int sum = records.stream()
.collect(Collectors.summingInt(Record::getCol3));
log.info("sum: {}", sum);
输出结果:
sum: 10
流的收集需要通过 Stream.collect() 方法完成,方法的参数是一个 Collector(收集器) ;收集结果时,需要根据收集结果的目标类型,传递特定的收集器实例,如上:
- Collectors.toList()
- Collectors.toSet()
- Collectors.toMap()
- Collectors.maxBy()
- Collectors.summingInt()
Collectors(java.util.stream.Collectors) 是一个工具类,内置若干收集器,我们可以通过调用不同的方法快速获取相应的收集器实例。
收集器(java.util.stream.Collector)本质是一个 接口 ,包含以下五个方法:
- Supplier supplier()
- BiConsumer<A, T> accumulator()
- BinaryOperator combiner()
- Function<A, R> finisher()
- Set characteristics()
以 Collectors.toList() 为例演示收集器的工作过程。
创建一个中间结果容器
supplier() 方法会返回一个 Supplier 实例,调用该实例的 get() 方法,会创建一个中间结果容器。

@Override
public Supplier<List<String>> supplier() {
return new Supplier<List<String>>() {
@Override
public List<String> get() {
List<String> container = new ArrayList<>();
return container;
}
};
}
考虑到收集的元素类型 String,这里的中间结果容器类型为 ArrayList 。
根据收集过程的需要,中间结果容器可以是任意的数据结构。
逐一遍历流中的每个元素,处理完成之后,添加到中间结果
accumulator() 方法会返回一个 BiConsumer 实例,它有一个 accept() 方法,
参数1:中间结果 参数2:流中遍历到的某个元素
遍历过程是 Java 自动完成的,每遍历一个元素,会自动调用 BiConsumer.accept 方法。我们只需要在方法中实现元素的处理过程,然后把元素的处理结果添加到中间结果中就可以了。

@Override
public BiConsumer<List<String>, String> accumulator() {
return new BiConsumer<List<String>, String>() {
@Override
public void accept(List<String> container, String col) {
container.add(col);
}
};
}
这个示例中,流中的元素不需要任何处理,直接添加至中间结果即可。
中间结果转换成最终结果
finisher() 方法会返回一个 Fuction 实例,它有一个 apply() 方法,
参数:中间结果 返回:最终结果
遍历过程结束之后,Java 会自动调用 Function.apply() 方法,将中间结果转换成最终结果。

@Override
public Function<List<String>, List<String>> finisher() {
return new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> container) {
return container;
}
};
}
这个示例中,中间结果就是最终结果,不需要任何处理,直接返回中间结果即可。
combiner()是做什么的?
流中的元素可以被并行处理,这样的流称为并行流。并行流相当于把一个大流切分成多个小流,内部使用多线程,并行处理这些小流。每一个小流遍历完成之后,都会产生一个小的中间结果,需要将这些小的中间结果合并成一个大的中间结果。
假设有两个小流,收集开始时,会创建两个中间结果:
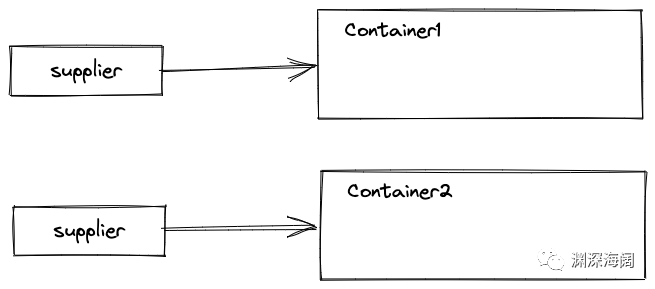
中间结果也是通过 Supplier.get() 方法创建的。
并行遍历两个小流,将各自流的处理结果添加到各自的中间结果中:
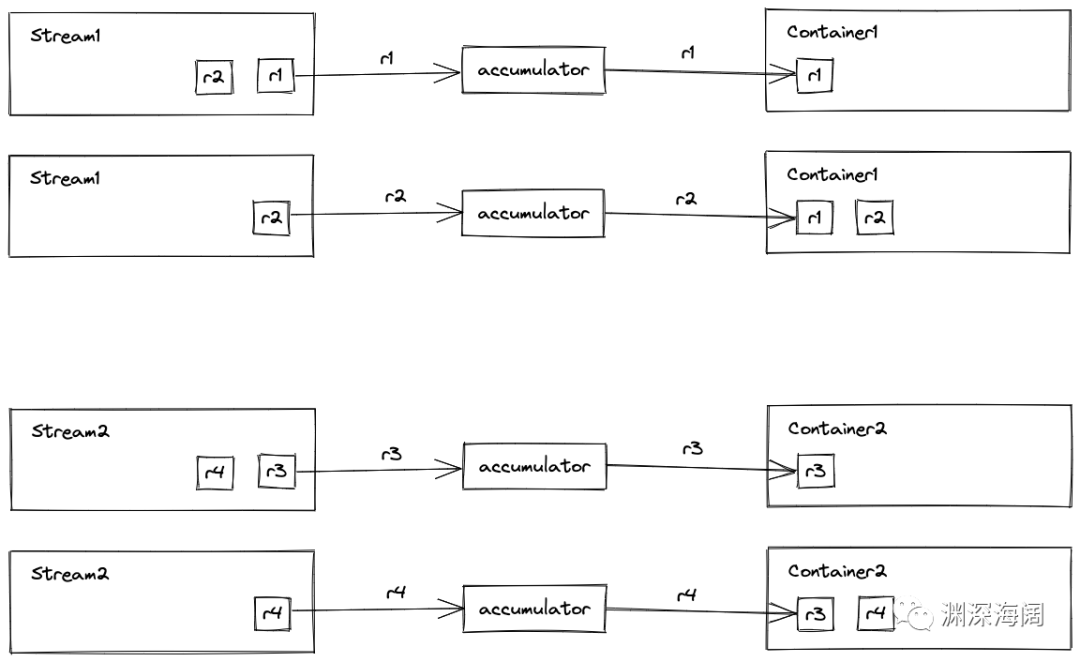
combiner() 方法会返回一个 BinaryOperator 实例,它有一个 apply() 方法:
参数1:中间结果1 参数2:中间结果2 返回:中间结果
Java 会在合适的时机自动调用 BinaryOperator.apply() 方法,将小的中间结果合并成大的中间结果。

@Override
public BinaryOperator<List<String>> combiner() {
return new BinaryOperator<List<String>>() {
@Override
public List<String> apply(List<String> container1, List<String> container2) {
container1.addAll(container2);
return container1;
}
};
}
characteristics()是什么的?
characteristics() 会返回一个 Characteristics(枚举)集合实例,用于设定收集器的特性,支持以下三个值:
- CONCURRENT
收集器支持并发使用
- UNORDERED
收集器不保证元素顺序
- IDENTITY_FINISH
收集器中间结果可直接转换成最终结果
Java 可以根据这些特性值,保证收集器正确地、有效率地执行。
完整代码
Collector<String, List<String>, List<String>> collector = new Collector<String, List<String>, List<String>>() {
@Override
public Supplier<List<String>> supplier() {
return new Supplier<List<String>>() {
@Override
public List<String> get() {
List<String> container = new ArrayList<>();
return container;
}
};
}
@Override
public BiConsumer<List<String>, String> accumulator() {
return new BiConsumer<List<String>, String>() {
@Override
public void accept(List<String> container, String col) {
container.add(col);
}
};
}
@Override
public BinaryOperator<List<String>> combiner() {
return new BinaryOperator<List<String>>() {
@Override
public List<String> apply(List<String> container1, List<String> container2) {
container1.addAll(container2);
return container1;
}
};
}
@Override
public Function<List<String>, List<String>> finisher() {
return new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> container) {
return container;
}
};
}
@Override
public Set<Characteristics> characteristics() {
return new HashSet<>();
}
};
col1List = records.stream()
.map(Record::getCol1)
.collect(collector);
log.info("col1List: {}", Json.toJson(col1List));
到此这篇关于Java 流处理之收集器的文章就介绍到这了,更多相关Java 收集器内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
解决java文件流处理异常 mark/reset not supported问题
原因: 给定的流不支持mark和reset就会报这个错误. 获取到一个网络流,这个网络流不允许读写头来回移动,也就不允许mark/reset机制. 解决办法: 用BufferedInputStream把原来的流包一层. BufferedInputStream buffInputStream = new BufferedInputStream(fileInputStream); 补充知识:Java BufferedReader之mark和reset方法实践 在读取文本的操作中,常常会在读取到文件末
-

java中的GC收集器详情
目录 1.GC(Garbage collection ) 2.GC算法 2.1标记活动对象 2.2 删除空闲对象 2.3 标记清除(Mark-Sweep) 2.4 清除压缩(Mark-Sweep-Compact) 2.5 标记和复制 3.JVM GC 3.1 JVM GC事件 3.2 Serial GC 3.3 Parallel GC 3.4 Concurrent Mark and Sweep 3.5 G1 –垃圾优先 4.总结 1.GC(Garbage collection ) 程序内存管理分
-
Javaweb应用使用限流处理大量的并发请求详解
在web应用中,同一时间有大量的客户端请求同时发送到服务器,例如抢购.秒杀等.这个时候如何避免将大量的请求同时发送到业务系统. 第一种方法:在容器中配置最大请求数,如果大于改请求数,则客户端阻塞.该方法有效的阻止了大量的请求同时访问业务系统,但对用户不友好. 第二种方法:使用过滤器,保证一定数量的请求能够正常访问系统,多余的请求先跳转到排队页面,由排队页面定时发起请求.过滤器实现如下: public class ServiceFilter implements Filter { private
-
Java8 Stream Collectors收集器使用方法解析
Collectors.toMap: Student studentA = new Student("20190001","小明"); Student studentB = new Student("20190002","小红"); Student studentC = new Student("20190003","小丁"); //Function.identity() 获取这个对象本身
-
java单机接口限流处理方案详解
对单机服务做接口限流的处理方案 简单说就是设定某个接口一定时间只接受固定次数的请求,比如/add接口1秒最多接收100次请求,多的直接拒绝,这个问题很常见,场景也好理解,直接上代码: /** * 单机限流 */ @Slf4j public class FlowLimit { //接口限流上限值和限流时间缓存 private static Cache<String, AtomicLong> localCache = CacheBuilder.newBuilder().maximumSize(10
-
JAVA垃圾收集器与内存分配策略详解
引言 垃圾收集技术并不是Java语言首创的,1960年诞生于MIT的Lisp是第一门真正使用内存动态分配和垃圾收集技术的语言.垃圾收集技术需要考虑的三个问题是: 1.哪些内存需要回收 2.什么时候回收 3.如何回收 java内存运行时区域的分布,其中程序计数器,虚拟机栈,本地方法区都是随着线程而生,随线程而灭,所以这几个区域就不需要过多考虑回收问题.但是堆和方法区就不一样了,只有在程序运行期间我们才知道会创建哪些对象,这部分内存的分配和回收都是动态的.垃圾收集器所关注的就是这部分内存. 一 对象
-
Java 流处理之收集器详解
目录 收集所有记录的 列1 值,以列表形式存储结果 收集所有记录的 列1 值,且去重,以集合形式存储 收集记录的 列2 值和 列3 值的对应关系,以字典形式存储 收集所有记录中 列3 值最大的记录 收集所有记录中 列3 值的总和 创建一个中间结果容器 逐一遍历流中的每个元素,处理完成之后,添加到中间结果 中间结果转换成最终结果 combiner()是做什么的? characteristics()是什么的? 完整代码 Java 流(Stream)处理操作完成之后,我们可以收集这个流中的元素,使之汇
-
java 类加载与自定义类加载器详解
类加载 所有类加载器,都是ClassLoader的子类. 类加载器永远以.class运行的目录为准. 读取classpath根目录下的文件有以下几种方式: 1 在Java项目中可以通过以下方式获取classspath下的文件: public void abc(){ //每一种读取方法,使用某个类获取Appclassloader ClassLoader cl = ReadFile.class.getClassLoader(); URL url = cl.getResource("a.txt&quo
-
java中的Struts2拦截器详解
最近在学习struts的拦截器,现在来总结一下. 1.拦截器是什么? 拦截器相当于过滤器:就是将不想要的去掉,想要的留下.拦截器抽象出一部分代码可以用来完善原来的action.同时可以减轻代码冗余,提高重用率.通俗地讲就是一张网,过滤掉不需要的沙子,留下水. 2.拦截器的作用: 拦截器可以构成特定的功能.比如权限认证.日志记录和登陆判断. 3.拦截器的原理: 其每一个Action请求都在拦截器中,每一个action可以将操作转交给下面的拦截器,也可以直接退出到界面上. 4.定义拦截器: (1)自
-
Java Spring中Quartz调度器详解及实例
一.Quartz的特点 * 按作业类的继承方式来分,主要有以下两种: 1.作业类继承org.springframework.scheduling.quartz.QuartzJobBean类的方式 2.作业类不继承org.springframework.scheduling.quartz.QuartzJobBean类的方式 注:个人比较推崇第二种,因为这种方式下的作业类仍然是POJO. * 按任务调度的触发时机来分,主要有以下两种: 1.每隔指定时间则触发一次,对应的调度器为org.springf
-
Java垃圾回收之分代收集算法详解
概述 这种算法,根据对象的存活周期的不同将内存划分成几块,新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法.可以用抓重点的思路来理解这个算法. 新生代对象朝生夕死,对象数量多,只要重点扫描这个区域,那么就可以大大提高垃圾收集的效率.另外老年代对象存储久,无需经常扫描老年代,避免扫描导致的开销. 新生代 在新生代,每次垃圾收集器都发现有大批对象死去,只有少量存活,采用复制算法,只需要付出少量存活对象的复制成本就可以完成收集:可以参看我之前写的Java垃圾回收之复制算法详解 老年代
-
classloader类加载器_基于java类的加载方式详解
基础概念 Classloader 类加载器,用来加载 Java 类到 Java 虚拟机中.与普通程序不同的是.Java程序(class文件)并不是本地的可执行程序.当运行Java程序时,首先运行JVM(Java虚拟机),然后再把Java class加载到JVM里头运行,负责加载Java class的这部分就叫做Class Loader. JVM本身包含了一个ClassLoader称为Bootstrap ClassLoader,和JVM一样,BootstrapClassLoader是用本地代码实现
-
Java文件操作之IO流 File类的使用详解
File类概述 File类能新建.删除.重命名文件和目录,但不能访问文件内容本身,如果需要访问文件内容本身,则需要使用后续的输入/输出流. 要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对象,但是Java程序中的一个File对象,可能没有一个真实存在的文件或目录. File对象可以作为参数传递给流的构造器. 常用构造器 ①public File(String pathname) 以pathname为路径创建File对象,可以是绝对路径或者相对路径,如果是相对路径,则默认相
-
Java Spring Boot消息服务万字详解分析
目录 消息服务概述 为什么要使用消息服务 异步处理 应用解耦 流量削峰 分布式事务管理 常用消息中间件介绍 ActiveMQ RabbitMQ RocketMQ RabbitMQ消息中间件 RabbitMQ简介 RabbitMQ工作模式介绍 Work queues(工作队列模式) Public/Subscribe(发布订阅模式) Routing(路由模式) Topics(通配符模式) RPC Headers RabbitMQ安装以及整合环境搭建 安装RabbitMQ 下载RabbitMQ 安装R
-
Java基础之垃圾回收机制详解
一.GC的作用 进行内存管理 C语言中的内存,申请内存之后需要手动释放:一旦忘记释放,就会发生内存泄漏! 而Java语言中,申请内存后会由GC来释放内存空间,无需手动释放 GC虽然代替了手动释放的操作,但是它也有局限性: 需要消耗更多的资源: 没有手动释放那么及时: STW(Stop The World)会影响程序的执行效率 二.GC主要回收哪些内存 (1)堆:主要回收堆中的内存 (2)方法区:需要回收 (3)栈(包括本地方法栈和JVM虚拟机栈):不需要回收,栈上的内存什么时候释放是明确的(线程
-
Java垃圾回收机制的示例详解
目录 一.概述 二.对象已死? 1.引用计数算法 2.可达性分析算法 3.四种引用 4.生存还是死亡? 5.回收方法区 三.垃圾收集算法 1.分代收集理论 2.名词解释 3.标记-清除算法 4.标记-复制算法 5.标记-整理算法 一.概述 说起垃圾收集(Garbage Collection,下文简称GC),有不少人把这项技术当作Java语言的伴生产 物.事实上,垃圾收集的历史远远比Java久远,在1960年诞生于麻省理工学院的Lisp是第一门开始使 用内存动态分配和垃圾收集技术的语言.当Lisp