Go语言kube-scheduler深度剖析开发之scheduler初始化
目录
- 引言
- Scheduler之Profiles
- Scheduler 之 SchedulingQueue
- Scheduler 之 cache
- Scheduler 之 NextPod 和 SchedulePod
引言
为了深入学习 kube-scheduler,本系从源码和实战角度深度学 习kube-scheduler,该系列一共分6篇文章,如下:
- kube-scheduler 整体架构
- 本文 :初始化一个 scheduler
- 一个 Pod 是如何调度的
- 如何开发一个属于自己的scheduler插件
- 开发一个 prefilter 扩展点的插件
- 开发一个 socre 扩展点的插件
上一篇,我们说了 kube-scheduler 的整体架构,是从整体的架构方面来考虑的,本文我们说说 kube-scheduler 是如何初始化出来的,kube-scheduler 里面都有些什么东西。
因为 kube-scheduler 源码内容比较多,对于那些不是关键的东西,就忽略不做讨论。
Scheduler之Profiles
下面我们先看下 Scheduler 的结构
type Scheduler struct {
Cache internalcache.Cache
Extenders []framework.Extender
NextPod func() *framework.QueuedPodInfo
FailureHandler FailureHandlerFn
SchedulePod func(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (ScheduleResult, error)
StopEverything <-chan struct{}
SchedulingQueue internalqueue.SchedulingQueue
Profiles profile.Map
client clientset.Interface
nodeInfoSnapshot *internalcache.Snapshot
percentageOfNodesToScore int32
nextStartNodeIndex int
}
上一篇我们说过,为一个 Pod 选择一个 Node 是按照固定顺序运行扩展点的;在扩展点内,是按照插件注册的顺序运行插件,如下图

上面的这些扩展点在 kube-scheduler 中是固定的,而且也不支持增加扩展点(实际上有这些扩展点已经足够了),而且扩展点顺序也是固定执行的。
下图是插件(以preFilter为例)运行的顺序,扩展点内的插件,你既可以调整插件的执行顺序(实际很少会修改默认的插件执行顺序),可以关闭某个内置插件,还可以增加自己开发的插件。

那么这些插件是怎么注册的,注册在哪里呢,自己开发的插件又是怎么加进去的呢?
我们来看下 Scheduler 里面最重要的一个成员:Profiles profile.Map
// 路径:pkg/scheduler/profile/profile.go // Map holds frameworks indexed by scheduler name. type Map map[string]framework.Framework
Profiles 是一个 key 为 scheduler name,value 是 framework.Framework 的map,表示根据 scheduler name 来获取 framework.Framework 类型的值,所以可以有多个scheduler。或许你在使用 k8s 的时候没有关注过 pod 或 deploment 里面的 scheduler,因为你没有指定的话,k8s 就会自动设置为默认的调度器,下图是 deployment 中未指定 schedulerName 被设置了默认调度器的一个deployment
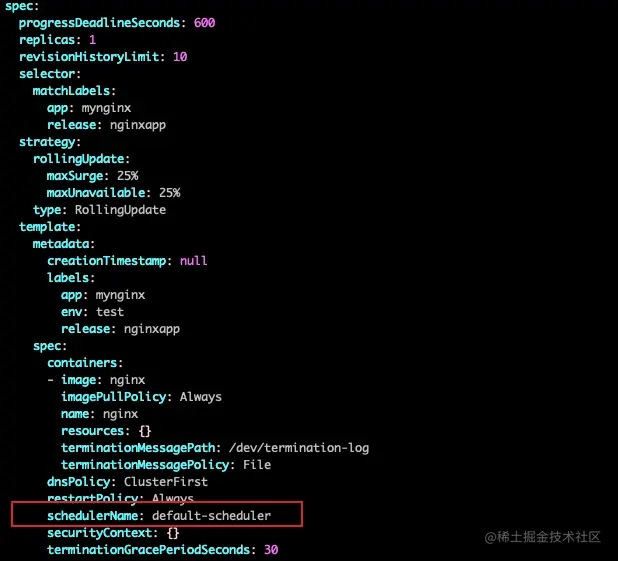
假设现在我想要使用自己开发的一个名叫 my-scheduler-1 的调度器,这个调度器在 preFilter 扩展点中增加了 zoneLabel 插件,怎么做?
使用 kubeadm 部署的 k8s 集群,会在 /etc/kubernetes/manifests 目录下创建 kube-scheduler.yaml 文件,kubelet 会根据这个文件自动拉起来一个静态 Pod,一个 kube-scheduler pod就被创建了,而且这个 kube-scheduler 运行的参数是直接在命令行上指定的。
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address=0.0.0.0
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: k8s.gcr.io/kube-scheduler:v1.16.8
....
其实 kube-scheduler 运行的时候可以指定配置文件,而不直接把参数写在启动命令上,如下形式。
./kube-scheduler --config /etc/kube-scheduler.conf
于是乎,我们就可以在配置文件中配置我们调度器的插件了
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: my-scheduler
plugins:
preFilter:
enabled:
- name: zoneLabel
disabled:
- name: NodePorts
我们可以使用 enabled,disabled 开关来关闭或打开某个插件。 通过配置文件,还可以控制扩展点的调用顺序,规则如下:
- 如果某个扩展点没有配置对应的扩展,调度框架将使用默认插件中的扩展
- 如果为某个扩展点配置且激活了扩展,则调度框架将先调用默认插件的扩展,再调用配置中的扩展
- 默认插件的扩展始终被最先调用,然后按照 KubeSchedulerConfiguration 中扩展的激活 enabled 顺序逐个调用扩展点的扩展
- 可以先禁用默认插件的扩展,然后在 enabled 列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
还可以添加多个调度器,在 deployment 等控制器中指定自己想要使用的调度器即可:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: my-scheduler-1
plugins:
preFilter:
enabled:
- name: zoneLabel
- schedulerName: my-scheduler-2
plugins:
queueSort:
enabled:
- name: mySort
当然了,现在我们在配置文件中定义的 mySort,zoneLabel 这样的插件还不能使用,我们需要开发具体的插件注册进去,才能正常运行,后面的文章会详细讲。
好了,现在 Profiles 成员(一个map)已经包含了两个元素,{"my-scheduler-1": framework.Framework ,"my-scheduler-2": framework.Framework}。当一个 Pod 需要被调度的时候,kube-scheduler 会先取出 Pod 的 schedulerName 字段的值,然后通过 Profiles[schedulerName],拿到 framework.Framework 对象,进而使用这个对象开始调度,我们可以用下面这种张图总结下上面描述的各个对象的关系。

那么重点就来到了 framework.Framework ,下面是 framework.Framework 的定义:
// pkg/scheduler/framework/interface.go
type Framework interface {
Handle
QueueSortFunc() LessFunc
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) (*PreFilterResult, *Status)
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
HasFilterPlugins() bool
HasPostFilterPlugins() bool
HasScorePlugins() bool
ListPlugins() *config.Plugins
ProfileName() string
}
Framework 是一个接口,需要实现的方法大部分形式为:Run***Plugins,也就是运行某个扩展点的插件,那么只要实现这个 Framework 接口就可以对 Pod 进行调度了。那么需要用户自己实现么?答案是不用,kube-scheduler 已经有一个该接口的实现:frameworkImpl
// pkg/scheduler/framework/runtime/framework.go
type frameworkImpl struct {
registry Registry
snapshotSharedLister framework.SharedLister
waitingPods *waitingPodsMap
scorePluginWeight map[string]int
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
clientSet clientset.Interface
kubeConfig *restclient.Config
eventRecorder events.EventRecorder
informerFactory informers.SharedInformerFactory
metricsRecorder *metricsRecorder
profileName string
extenders []framework.Extender
framework.PodNominator
parallelizer parallelize.Parallelizer
}
frameworkImpl 这个结构体里面包含了每个扩展点插件数组,所以某个扩展点要被执行的时候,只要遍历这个数组里面的所有插件,然后执行这些插件就可以了。我们看看 framework.FilterPlugin 是怎么定义的(其他的也类似):
type Plugin interface {
Name() string
}
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
插件数组的类型是一个接口,那么某个插件只要实现了这个接口就可以被运行。实际上,我们前面说的那些默认插件,都实现了这个接口,在目录 pkg/scheduler/framework/plugins 目录下面包含了所有内置插件的实现,主要就是对上面说的这个插件接口的实现。我们可以简单用图描述下 Pod被调度的时候执行插件的流程

那么这些默认插件是怎么加到framework里面的,自定义插件又是怎么加进来的呢?
分三步:
- 根据配置文件(--config指定的)、系统默认的插件,按照扩展点生成需要被加载的插件数组(包括插件名字,权重信息),也就是初始化 KubeSchedulerConfiguration 中的 Profiles 成员。
type KubeSchedulerConfiguration struct {
metav1.TypeMeta
Parallelism int32
LeaderElection componentbaseconfig.LeaderElectionConfiguration
ClientConnection componentbaseconfig.ClientConnectionConfiguration
HealthzBindAddress string
MetricsBindAddress string
componentbaseconfig.DebuggingConfiguration
PercentageOfNodesToScore int32
PodInitialBackoffSeconds int64
PodMaxBackoffSeconds int64
Profiles []KubeSchedulerProfile
Extenders []Extender
}
- 创建 registry 集合,这个集合内是每个插件实例化函数,也就是 插件名字->插件实例化函数的映射,通俗一点说就是告诉系统:1.我叫王二; 2. 你应该怎么把我创建出来。那么张三、李四、王五分别告诉系统怎么创建自己,就组成了这个集合。
type PluginFactory = func(configuration runtime.Object, f framework.Handle) (framework.Plugin, error) type Registry map[string]PluginFactory
这个集合是内置(叫inTree)默认的插件映射和用户自定义(outOfTree)的插件映射的并集,内置的映射通过下面函数创建:
// pkg/scheduler/framework/plugins/registry.go
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
}
return runtime.Registry{
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
}
}
那么用户自定义的插件怎么来的呢?这里咱们先不展开,在后面插件开发的时候再详细讲,不影响我们理解。我们假设用户自定义的也已经生成了 registry,下面的代码就是把他们合并在一起
// pkg/scheduler/scheduler.go
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
现在内置插件和系统默认插件的实例化函数映射已经创建好了
- 将(1)中每个扩展点的每个插件(就是插件名字)拿出来,去(2)的映射(map)中获取实例化函数,然后运行这个实例化函数,最后把这个实例化出来的插件(可以被运行的)追加到上面提到过的 frameworkImpl 中对应扩展点数组中,这样后面要运行某个扩展点插件的时候就可以遍历运行就可以了。我们可以把上述过程用下图表示

Scheduler 之 SchedulingQueue
上面我们介绍了 Scheduler 第一个关键成员 Profiles 的初始化和作用,下面我们来谈谈第二个关键成员:SchedulingQueue。
// pkg/scheduler/scheduler.go podQueue := internalqueue.NewSchedulingQueue( profiles[options.profiles[0].SchedulerName].QueueSortFunc(), informerFactory, // 1s internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second), // 10s internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second), internalqueue.WithPodNominator(nominator), internalqueue.WithClusterEventMap(clusterEventMap), // 5min internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration), )
func NewSchedulingQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option) SchedulingQueue {
return NewPriorityQueue(lessFn, informerFactory, opts...)
}
type PriorityQueue struct {
framework.PodNominator
stop chan struct{}
clock clock.Clock
podInitialBackoffDuration time.Duration
podMaxBackoffDuration time.Duration
podMaxInUnschedulablePodsDuration time.Duration
lock sync.RWMutex
cond sync.Cond
activeQ *heap.Heap
podBackoffQ *heap.Heap
unschedulablePods *UnschedulablePods
schedulingCycle int64
moveRequestCycle int64
clusterEventMap map[framework.ClusterEvent]sets.String
closed bool
nsLister listersv1.NamespaceLister
}
SchedulingQueue 是一个 internalqueue.SchedulingQueue 的接口类型,PriorityQueue 对这个接口进行了实现,创建 Scheduler 的时候 SchedulingQueue 会被 PriorityQueue 类型对象赋值。
PriorityQueue 中有关键的3个成员:activeQ、podBackoffQ、unschedulablePods。
- activeQ 是一个优先队列,用来存放待调度的 Pod,Pod 按照优先级存放在队列中
- podBackoffQ 用来存放异常的 Pod, 该队列里面的 Pod 会等待一定时间后被移动到 activeQ 里面重新被调度
- unschedulablePods 中会存放调度失败的 Pod,它不是队列,而是使用 map 来存放的,这个 map 里面的 Pod 在一定条件下会被移动到 activeQ 或 podBackoffQ 中
PriorityQueue 还有两个方法:flushUnschedulablePodsLeftover 和 flushBackoffQCompleted
- flushUnschedulablePodsLeftover:调度失败的 Pod 如果满足一定条件,这个函数会将这种 Pod 移动到 activeQ 或 podBackoffQ
- flushBackoffQCompleted:运行异常的 Pod 等待时间完成后,flushBackoffQCompleted 将该 Pod 移动到 activeQ
Scheduler 在启动的时候,会创建2个协程来定期运行这两个函数
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}
上面是定期对 Pod 在这些队列之间的转换,那么除了定期刷新的方式,还有下面情况也会触发队列转换:
- 有新节点加入集群
- 节点配置或状态发生变化
- 已经存在的 Pod 发生变化
- 集群内有Pod被删除
至于他们之间是如何转换的,我们在下一篇文章里面详细介绍
Scheduler 之 cache
要说 cache 最大的作用就是提升 Scheduler 的效率,降低 kube-apiserver(本质是 etcd)的压力,在调用各个插件计算的时候所需要的 Node 信息和其他 Pod 信息都缓存在本地,在需要使用的时候直接从缓存获取即可,而不需要调用 api 从 kube-apiserver 获取。cache 类型是 internalcache.Cache 的接口,cacheImpl 实现了这个接口。
下面是 cacheImpl 的结构
type Cache interface NodeCount() int PodCount() (int, error) AssumePod(pod *v1.Pod) error FinishBinding(pod *v1.Pod) error ForgetPod(pod *v1.Pod) error AddPod(pod *v1.Pod) error UpdatePod(oldPod, newPod *v1.Pod) error RemovePod(pod *v1.Pod) error GetPod(pod *v1.Pod) (*v1.Pod, error) IsAssumedPod(pod *v1.Pod) (bool, error) AddNode(node *v1.Node) *framework.NodeInfo UpdateNode(oldNode, newNode *v1.Node) *framework.NodeInfo RemoveNode(node *v1.Node) error UpdateSnapshot(nodeSnapshot *Snapshot) error Dump() *Dump }
type cacheImpl struct {
stop <-chan struct{}
ttl time.Duration
period time.Duration
mu sync.RWMutex
assumedPods sets.String
podStates map[string]*podState
nodes map[string]*nodeInfoListItem
headNode *nodeInfoListItem
nodeTree *nodeTree
imageStates map[string]*imageState
}
cacheImpl 中的 nodes 存放集群内所有 Node 信息;podStates 存放所有 Pod 信息;,assumedPods 存放已经调度成功但是还没调用 kube-apiserver 的进行绑定的(也就是还没有执行 bind 插件)的Pod,需要这个缓存的原因也是为了提升调度效率,将绑定和调度分开,因为绑定需要调用 kube-apiserver,这是一个重操作会消耗比较多的时间,所以 Scheduler 乐观的假设调度已经成功,然后返回去调度其他 Pod,而这个 Pod 就会放入 assumedPods 中,并且也会放入到 podStates 中,后续其他 Pod 在进行调度的时候,这个 Pod 也会在插件的计算范围内(如亲和性), 然后会新起协程进行最后的绑定,要是最后绑定失败了,那么这个 Pod 的信息会从 assumedPods 和 podStates 移除,并且把这个 Pod 重新放入 activeQ 中,重新被调度。
Scheduler 在启动时首先会 list 一份全量的 Pod 和 Node 数据到上述的缓存中,后续通过 watch 的方式发现变化的 Node 和 Pod,然后将变化的 Node 或 Pod 更新到上述缓存中。
Scheduler 之 NextPod 和 SchedulePod
到了这里,调度框架 framework 和调度队列 SchedulingQueue 都已经创建出来了,现在是时候开始调度Pod了。
Scheduler 中有个成员 NextPod 会从 activeQ 队列中尝试获取一个待调度的 Pod,该函数在 SchedulePod 中被调用,如下:
// 启动 Scheduler
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
// 尝试调度一个 Pod,所以 Pod 的调度入口
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 会一直阻塞,直到获取到一个Pod
......
podInfo := sched.NextPod()
......
}
NextPod 它被赋予如下函数:
// pkg/scheduler/internal/queue/scheduling_queue.go
func MakeNextPodFunc(queue SchedulingQueue) func() *framework.QueuedPodInfo {
return func() *framework.QueuedPodInfo {
podInfo, err := queue.Pop()
if err == nil {
klog.V(4).InfoS("About to try and schedule pod", "pod", klog.KObj(podInfo.Pod))
for plugin := range podInfo.UnschedulablePlugins {
metrics.UnschedulableReason(plugin, podInfo.Pod.Spec.SchedulerName).Dec()
}
return podInfo
}
klog.ErrorS(err, "Error while retrieving next pod from scheduling queue")
return nil
}
}
Pop 会一直阻塞,直到 activeQ 长度大于0,然后去取出一个 Pod 返回
// pkg/scheduler/internal/queue/scheduling_queue.go
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
for p.activeQ.Len() == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the p.closed is set and the condition is broadcast,
// which causes this loop to continue and return from the Pop().
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
p.cond.Wait()
}
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
pInfo := obj.(*framework.QueuedPodInfo)
pInfo.Attempts++
p.schedulingCycle++
return pInfo, nil
}
到了这里我们就介绍完了 Scheduler 中最重要的几个成员,简单总结下:
- Profiles: 存放插件对象,在运行时可以遍历扩展点内的所有插件运行
- SchedulerQueue:用来存放待调度 Pod,异常 Pod,调度失败 Pod,他们相互可以转换
- cache:存放 Pod 和 Node 的信息,提升调度效率
- NextPod 和 ScheduleOne:尝试从 activeQ 获取一个 Pod,开始调度。
本文就到这,下一篇,我们会讲一讲一个 Pod 提交后的调度流程。
以上就是Go语言kube-scheduler深度剖析开发之scheduler初始化的详细内容,更多关于go scheduler初始化的资料请关注我们其它相关文章!
相关推荐
-
Go语言学习otns示例分析
目录 学习过程 proto文件 visualize/grpc/replay目录下的文件 cmd/otns-replay目录下的文件 grpc_Service(包含pb) otns_replay(包含pb) cmd/otns/otns.go文件 simulation目录下的文件 type.go simulationController.go simulation_config.go simulation.go cli目录 ast.go CmdRunner.go 总结 学习过程 由于在用虚拟机体验过
-
Go语言开发kube-scheduler整体架构深度剖析
目录 k8s 的调度器 kube-scheduler 官方描述scheduler 各个类型扩展点 kube-scheduler 代码的主要框架 k8s 的调度器 kube-scheduler kube-scheduler 作为 k8s 的调度器,就好比人的大脑,将行动指定传递到手脚等器官,进而执行对应的动作,对于 kube-scheduler 则是将 Pod 分配(调度)到集群内的各个节点,进而创建容器运行进程,对于k8s来说至关重要. 为了深入学习 kube-scheduler,本系从源码和实
-
GoJs连线绘图模板Link使用示例详解
目录 前言 go.link的简单使用 go.Link的属性配置 routing属性 curve属性 corner.toEndSegmentLength.fromEndSegmentLength.fromShortLength.toShortLength属性 selectable.fromSpot.toSpot属性 总结 前言 可视化图形中除了携带很多信息的节点(node)之外,还需要知道他们之间的关系,而链接他们之间的连线在gojs中是使用go.link进行绘制.在渲染的时候我们根据数据的fro
-
深入string理解Golang是怎样实现的
目录 引言 内容介绍 字符串数据结构 字符串会分配到内存中的哪块区域 编译期即可确定的字符串 如果我们创建两个hello world字符串, 他们会放到同一内存区域吗? 运行时通过+拼接的字符串会放到那块内存中 字面量是否会在编译器合并 当我们用+连接多个字符串时, 会发生什么 rawstring函数 go中字符串是不可变的吗, 我们如何得到一个可变的字符串 []byte和string的更高效转换 结尾 引言 本身打算先写完sync包的, 但前几天在复习以前笔记的时候突然发现与字符串相关的寥寥无
-
Go语言kube-scheduler深度剖析与开发之pod调度
目录 正文 感知 Pod 取出 Pod 调度 Pod 正文 为了深入学习 kube-scheduler,本系从源码和实战角度深度学 习kube-scheduler,该系列一共分6篇文章,如下: kube-scheduler 整体架构 初始化一个 scheduler 本文: 一个 Pod 是如何调度的 如何开发一个属于自己的scheduler插件 开发一个 prefilter 扩展点的插件 开发一个 socre 扩展点的插件 上一篇文章我们讲了一个 kube-scheduler 是怎么初始化出来的
-

R语言开发之CSV文件的读写操作实现
在R中,我们可以从存储在R环境外部的文件读取数据,还可以将数据写入由操作系统存储和访问的文件.这个csv文件应该存在于当前工作目录中,以方便R可以读取它, 当然,也可以设置自己的目录,并从那里读取文件. 我们可以使用getwd()函数来检查R工作区指向哪个目录,并且使用setwd()函数设置新的工作目录,如下: 输出结果如下: csv文件是一个文本文件,其中列中的值用逗号分隔,我们可以将以下数据保存入txt文件中,并且修改后缀名称为csv: id,name,salary,start_date,d
-
C语言可变参数列表的用法与深度剖析
目录 前言 一.可变参数列表是什么? 二.怎么用可变参数列表 三.对于宏的深度剖析 隐式类型转换 对两个函数的重新认知 总结 前言 可变参数列表,使用起来像是数组,学习过函数栈帧的话可以发现实际上他也就是在栈区定义的一块空间当中连续访问,不过他不支持直接在中间部分访问. 声明: 以下所有测试都是在x86,vs2013下完成的. 一.可变参数列表是什么? 在我们初始C语言的第一节课的时候我们就已经接触了可变参数列表,在printf的过程当中我们通常可以传递大量要打印的参数,但是我们却不知道他是如何
-
你真的理解C语言qsort函数吗 带你深度剖析qsort函数
目录 一.前言 二.简单冒泡排序法 三.qsort函数的使用 1.qsort函数的介绍 2.qsort函数的运用 2.1.qsort函数排序整型数组 2.2.qsort函数排序结构体 四.利用冒泡排序模拟实现qsort函数 五.总结 一.前言 我们初识C语言时,会做过让一个整型数组按照从小到大来排序的问题,我们使用的是冒泡排序法,但是如果我们想要比较其他类型怎么办呢,显然我们当时的代码只适用于简单的整形排序,对于结构体等没办法排序,本篇将引入一个库函数来实现我们希望的顺序. 二.简单冒泡排序法
-
.NET微信开发之PC 端微信扫码注册和登录功能实现
一.前言 先声明一下,本文所注重点为实现思路,代码及数据库设计主要为了展现思路,如果对代码效率有着苛刻要求的项目切勿照搬. 相信做过微信开发的人授权这块都没少做过,但是一般来说我们更多的是为移动端的网站做授权,确切来说是在微信端下做的一个授权.今天遇到的一个问题是,项目支持微信端以及 PC 端,并且开放注册.要求做到无论在 PC 端注册或者是在微信端注册之后都可以在另外一个端进行登录.也就是说无论 PC 或是微信必须做到"你就是你"(通过某种方式关联). 二.寻找解决方案 按传统的方式
-
JavaScript模块化开发之SeaJS
前言 SeaJS是一个遵循CommonJS规范的JavaScript模块加载框架,可以实现JavaScript的模块化开发及加载机制.使用SeaJS可以提高JavaScript代码的可读性和清晰度,解决目前JavaScript编程中普遍存在的依赖关系混乱和代码纠缠等问题,方便代码的编写和维护. SeaJS本身遵循KISS(Keep it Simple,Stupid)理念进行开发,后续的几个版本更新也都是吵着这个方向迈进. 如何使用SeaJS 下载及安装在这里不赘述了,不了解的请查询官网. 基
-
IOS 开发之Object-C中的对象详解
IOS 开发之Object-C中的对象详解 前言 关于C语言的基础部分已经记录完毕,接下来就是学习Object-C了,编写oc程序需要使用Foundation框架.下面就是对oc中的对象介绍. 对象 对象和结构类似,一个对象可以保存多个相关的数据.在结构中,我们称这些数据为成员.而在对象中,称这些数据为实例变量.除了这些以外,对象和结构不用之处在于,对象还可以包含一组函数,并且这些函数可以使用对象所保存的数据,这类函数称为方法. 类 类(class)负责描述某个特点类型的对象,其中包括方法和实例
-
前端开发之CSS原理详解
前端开发之CSS原理详解 从事Web前端开发的人都与CSS打交道很多,有的人也许不知道CSS是怎么去工作的,写出来的CSS浏览器是怎么样去解析的呢?当这个成为我们提高CSS水平的一个瓶颈时,是否应该多了解一下呢? 一.浏览器的发展与CSS 网页浏览器主要通过 HTTP 协议连接网页服务器而取得网页, HTTP 容许网页浏览器送交资料到网页服务器并且获取网页.目前最常用的 HTTP 是 HTTP/1.1,这个协议在 RFC2616 中被完整定义.HTTP/1.1 有其一套 Internet Exp
-
详解 Corba开发之Java实现Service与Client
详解 Corba开发之Java实现Service与Client 1 概述 CORBA(Common Object Request Broker Architecture,公共对象请求代理体系结构)是由OMG组织制订的一种标准的面向对象应用程 序体系规范.或者说 CORBA体系结构是OMG为解决分布式处理环境(DCE)中,硬件和软件系统的互连而提出的一种解决方案. OMG:Object Management Group,对象管理组织.是一个国际化的.开放成员的.非盈利性的计算机行业标准协
-
Android开发之OpenGL绘制2D图形的方法分析
本文实例讲述了Android开发之OpenGL绘制2D图形的方法.分享给大家供大家参考,具体如下: Android为OpenGL ES支持提供了GLSurviceView组建,这个组建用于显示3D图形.GLSurviceView本身并不提供绘制3的图形的功能,而是由GLSurfaceView.Renderer来完成了SurviceView中3D图形的绘制. 归纳起来,在android中使用OpenGL ES需要3个步骤. 1. 创建GLSurviceView组件,使用Activity来显示GLS