详解高性能缓存Caffeine原理及实战
目录
- 一、简介
- 二、Caffeine 原理
- 2.1、淘汰算法
- 2.1.1、常见算法
- 2.1.2、W-TinyLFU 算法
- 2.2、高性能读写
- 2.2.1、读缓冲
- 2.2.2、写缓冲
- 三、Caffeine 实战
- 3.1、配置参数
- 3.2、项目实战
- 四、总结
一、简介
下面是Caffeine 官方测试报告。
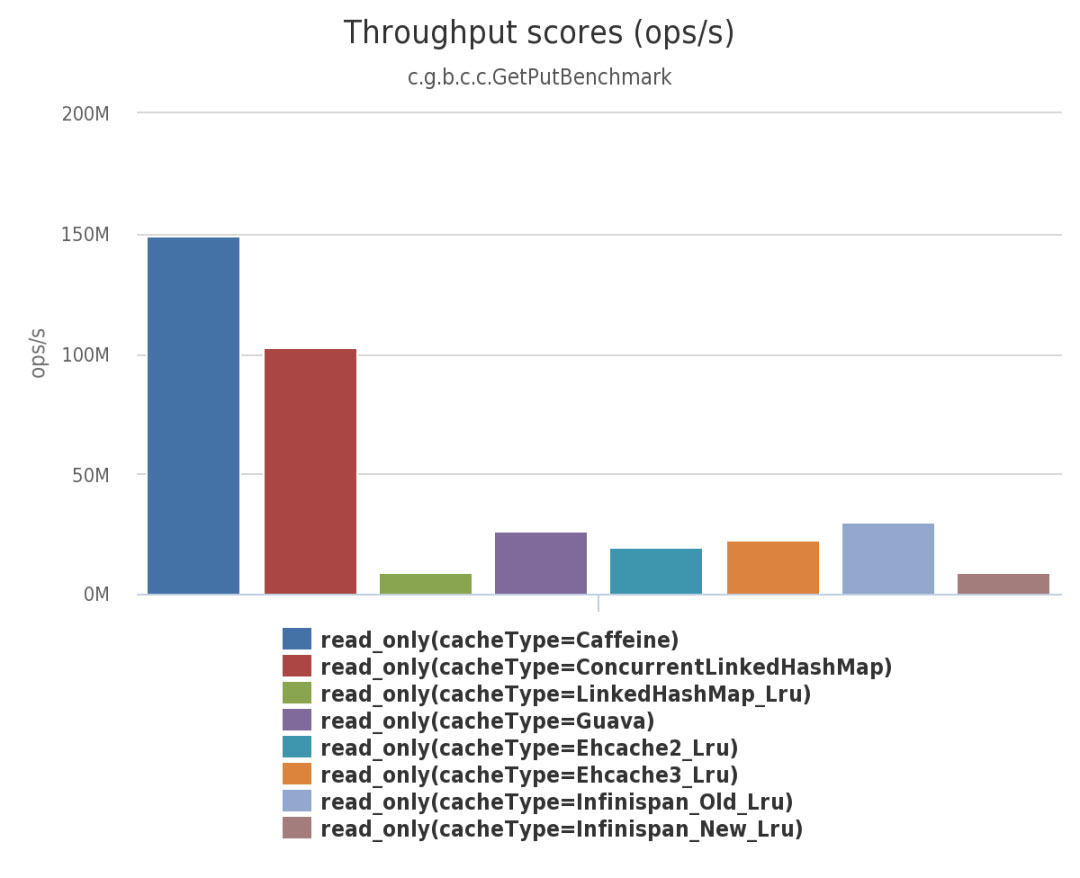
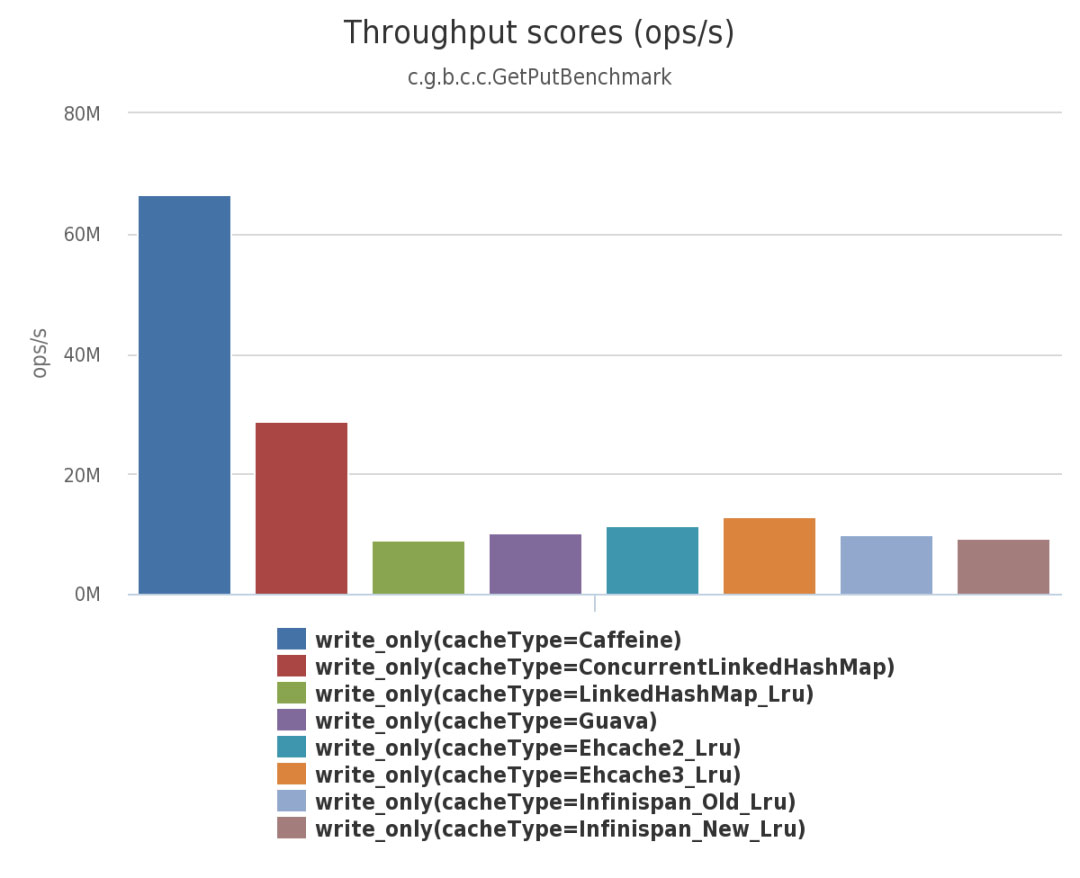
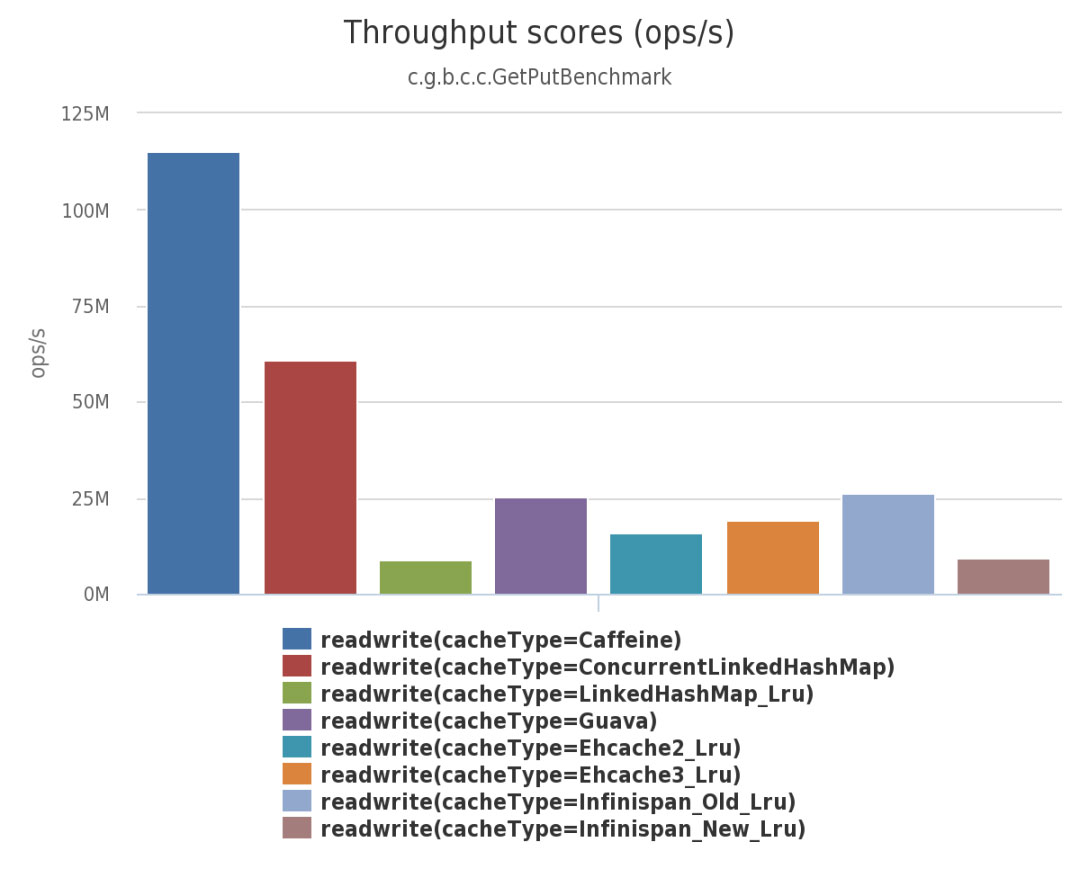
由上面三幅图可见:不管在并发读、并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件。
本文先介绍 Caffeine 实现原理,再讲解如何在项目中使用 Caffeine 。
二、Caffeine 原理
2.1、淘汰算法
2.1.1、常见算法
对于 Java 进程内缓存我们可以通过 HashMap 来实现。不过,Java 进程内存是有限的,不可能无限地往里面放缓存对象。这就需要有合适的算法辅助我们淘汰掉使用价值相对不高的对象,为新进的对象留有空间。常见的缓存淘汰算法有 FIFO、LRU、LFU。
FIFO(First In First Out):先进先出。
它是优先淘汰掉最先缓存的数据、是最简单的淘汰算法。缺点是如果先缓存的数据使用频率比较高的话,那么该数据就不停地进进出出,因此它的缓存命中率比较低。
LRU(Least Recently Used):最近最久未使用。
它是优先淘汰掉最久未访问到的数据。缺点是不能很好地应对偶然的突发流量。比如一个数据在一分钟内的前59秒访问很多次,而在最后1秒没有访问,但是有一批冷门数据在最后一秒进入缓存,那么热点数据就会被冲刷掉。
LFU(Least Frequently Used):
最近最少频率使用。它是优先淘汰掉最不经常使用的数据,需要维护一个表示使用频率的字段。
主要有两个缺点:
一、如果访问频率比较高的话,频率字段会占据一定的空间;
二、无法合理更新新上的热点数据,比如某个歌手的老歌播放历史较多,新出的歌如果和老歌一起排序的话,就永无出头之日。
2.1.2、W-TinyLFU 算法
Caffeine 使用了 W-TinyLFU 算法,解决了 LRU 和LFU上述的缺点。W-TinyLFU 算法由论文《TinyLFU: A Highly Efficient Cache Admission Policy》提出。
它主要干了两件事:
一、采用 Count–Min Sketch 算法降低频率信息带来的内存消耗;
二、维护一个PK机制保障新上的热点数据能够缓存。
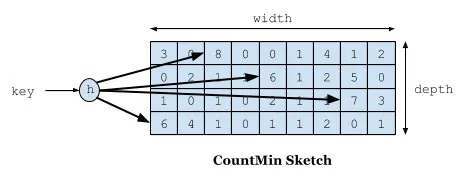
如下图所示,Count–Min Sketch 算法类似布隆过滤器 (Bloom filter)思想,对于频率统计我们其实不需要一个精确值。存储数据时,对key进行多次 hash 函数运算后,二维数组不同位置存储频率(Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成16份,每份4bit,默认15次为最高访问频率,每个key实际 hash 了四次,落在不同 long 型数字的16份中某个位置)。读取某个key的访问次数时,会比较所有位置上的频率值,取最小值返回。对于所有key的访问频率之和有个最大值,当达到最大值时,会进行reset即对各个缓存key的频率除以2。
如下图缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者 频率大小,大胜小汰。
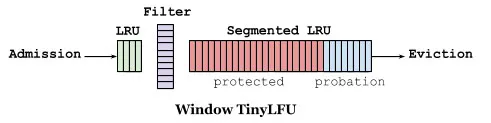
总的来说,通过 reset 衰减,避免历史热点数据由于频率值比较高一直淘汰不掉,并且通过对访问队列分成三段,这样避免了新加入的热点数据早早地被淘汰掉。
2.2、高性能读写
Caffeine 认为读操作是频繁的,写操作是偶尔的,读写都是异步线程更新频率信息。
2.2.1、读缓冲
传统的缓存实现将会为每个操作加锁,以便能够安全的对每个访问队列的元素进行排序。一种优化方案是将每个操作按序加入到缓冲区中进行批处理操作。读完把数据放到环形队列 RingBuffer 中,为了减少读并发,采用多个 RingBuffer,每个线程都有对应的 RingBuffer。环形队列是一个定长数组,提供高性能的能力并最大程度上减少了 GC所带来的性能开销。数据丢到队列之后就返回读取结果,类似于数据库的WAL机制,和ConcurrentHashMap 读取数据相比,仅仅多了把数据放到队列这一步。异步线程并发读取 RingBuffer 数组,更新访问信息,这边的线程池使用的是下文实战小节讲的 Caffeine 配置参数中的 executor。
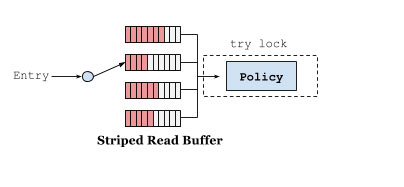
2.2.2、写缓冲
与读缓冲类似,写缓冲是为了储存写事件。读缓冲中的事件主要是为了优化驱逐策略的命中率,因此读缓冲中的事件完整程度允许一定程度的有损。但是写缓冲并不允许数据的丢失,因此其必须实现为一个安全的队列。Caffeine 写是把数据放入MpscGrowableArrayQueue 阻塞队列中,它参考了JCTools里的MpscGrowableArrayQueue ,是针对 MPSC- 多生产者单消费者(Multi-Producer & Single-Consumer)场景的高性能实现。多个生产者同时并发地写入队列是线程安全的,但是同一时刻只允许一个消费者消费队列。
三、Caffeine 实战
3.1、配置参数
Caffeine 借鉴了Guava Cache 的设计思想,如果之前使用过 Guava Cache,那么Caffeine 很容易上手,只需要改变相应的类名就行。构造一个缓存 Cache 示例代码如下:
Cache cache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(6, TimeUnit.MINUTES).softValues().build();
Caffeine 类相当于建造者模式的 Builder 类,通过 Caffeine 类配置 Cache,配置一个Cache 有如下参数:
- expireAfterWrite:写入间隔多久淘汰;
- expireAfterAccess:最后访问后间隔多久淘汰;
- refreshAfterWrite:写入后间隔多久刷新,该刷新是基于访问被动触发的,支持异步刷新和同步刷新,如果和 expireAfterWrite 组合使用,能够保证即使该缓存访问不到、也能在固定时间间隔后被淘汰,否则如果单独使用容易造成OOM;
- expireAfter:自定义淘汰策略,该策略下 Caffeine 通过时间轮算法来实现不同key 的不同过期时间;
- maximumSize:缓存 key 的最大个数;weakKeys:key设置为弱引用,在 GC 时可以直接淘汰;
- weakValues:value设置为弱引用,在 GC 时可以直接淘汰;
- softValues:value设置为软引用,在内存溢出前可以直接淘汰;
- executor:选择自定义的线程池,默认的线程池实现是 ForkJoinPool.commonPool();
- maximumWeight:设置缓存最大权重;weigher:设置具体key权重;
- recordStats:缓存的统计数据,比如命中率等;
- removalListener:缓存淘汰监听器;writer:缓存写入、更新、淘汰的监听器。
3.2、项目实战
Caffeine 支持解析字符串参数,参照 Ehcache 的思想,可以把所有缓存项参数信息放入配置文件里面,比如有一个 caffeine.properties 配置文件,里面配置参数如下:
users=maximumSize=10000,expireAfterWrite=180s,softValues goods=maximumSize=10000,expireAfterWrite=180s,softValues
针对不同的缓存,解析配置文件,并加入 Cache 容器里面,代码如下:
@Component
@Slf4j
public class CaffeineManager {
private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap<>(16);
@PostConstruct
public void afterPropertiesSet() {
String filePath = CaffeineManager.class.getClassLoader().getResource("").getPath() + File.separator + "config"
+ File.separator + "caffeine.properties";
Resource resource = new FileSystemResource(filePath);
if (!resource.exists()) {
return;
}
Properties props = new Properties();
try (InputStream in = resource.getInputStream()) {
props.load(in);
Enumeration propNames = props.propertyNames();
while (propNames.hasMoreElements()) {
String caffeineKey = (String) propNames.nextElement();
String caffeineSpec = props.getProperty(caffeineKey);
CaffeineSpec spec = CaffeineSpec.parse(caffeineSpec);
Caffeine caffeine = Caffeine.from(spec);
Cache manualCache = caffeine.build();
cacheMap.put(caffeineKey, manualCache);
}
}
catch (IOException e) {
log.error("Initialize Caffeine failed.", e);
}
}
}
当然也可以把 caffeine.properties 里面的配置项放入配置中心,如果需要动态生效,可以通过如下方式:
至于是否利用 Spring 的 EL 表达式通过注解的方式使用,仁者见仁智者见智,笔者主要考虑几点:
一、EL 表达式上手需要学习成本;
二、引入注解需要注意动态代理失效场景;
获取缓存时通过如下方式:
caffeineManager.getCache(cacheName).get(redisKey, value -> getTFromRedis(redisKey, targetClass, supplier));
Caffeine 这种带有回源函数的 get 方法最终都是调用 ConcurrentHashMap 的 compute 方法,它能确保高并发场景下,如果对一个热点 key 进行回源时,单个进程内只有一个线程回源,其他都在阻塞。业务需要确保回源的方法耗时比较短,防止线程阻塞时间比较久,系统可用性下降。
笔者实际开发中用了 Caffeine 和 Redis 两级缓存。Caffeine 的 cache 缓存 key 和 Redis 里面一致,都是命名为 redisKey。targetClass 是返回对象类型,从 Redis 中获取字符串反序列化成实际对象时使用。supplier 是函数式接口,是缓存回源到数据库的业务逻辑。
getTFromRedis 方法实现如下:
private <T> T getTFromRedis(String redisKey, Class targetClass, Supplier supplier) {
String data;
T value;
String redisValue = UUID.randomUUID().toString();
if (tryGetDistributedLockWithRetry(redisKey + RedisKey.DISTRIBUTED_SUFFIX, redisValue, 30)) {
try {
data = getFromRedis(redisKey);
if (StringUtils.isEmpty(data)) {
value = (T) supplier.get();
setToRedis(redisKey, JackSonParser.bean2Json(value));
}
else {
value = json2Bean(targetClass, data);
}
}
finally {
releaseDistributedLock(redisKey + RedisKey.DISTRIBUTED_SUFFIX, redisValue);
}
}
else {
value = json2Bean(targetClass, getFromRedis(redisKey));
}
return value;
}
由于回源都是从 MySQL 查询,虽然 Caffeine 本身解决了进程内同一个 key 只有一个线程回源,需要注意多个业务节点的分布式情况下,如果 Redis 没有缓存值,并发回源时会穿透到 MySQL ,所以回源时加了分布式锁,保证只有一个节点回源。
注意一点:从本地缓存获取对象时,如果业务要对缓存对象做更新,需要深拷贝一份对象,不然并发场景下多个线程取值会相互影响。
笔者项目之前都是使用 Ehcache 作为本地缓存,切换成 Caffeine 后,涉及本地缓存的接口,同样 TPS 值时,CPU 使用率能降低 10% 左右,接口性能都有一定程度提升,最多的提升了 25%。上线后观察调用链,平均响应时间降低24%左右。
四、总结
Caffeine 是目前比较优秀的本地缓存解决方案,通过使用 W-TinyLFU 算法,实现了缓存高命中率、内存低消耗。如果之前使用过 Guava Cache,看下接口名基本就能上手。如果之前使用的是 Ehcache,笔者分享的使用方式可以作为参考。
以上就是详解高性能缓存Caffeine原理及实战的详细内容,更多关于Caffeine 原理的资料请关注我们其它相关文章!
相关推荐
-
SpringBoot集成Caffeine缓存的实现步骤
Maven依赖 要开始使用咖啡因Caffeine和Spring Boot,我们首先添加spring-boot-starter-cache和咖啡因Caffeine依赖项: <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </depend
-

Spring Boot 2.x 把 Guava 干掉了选择本地缓存之王 Caffeine(推荐)
环境配置: JDK 版本:1.8 Caffeine 版本:2.8.0 SpringBoot 版本:2.2.2.RELEASE 一.本地缓存介绍 缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力. 之前介绍过 Redis 这种 NoSql 作为缓存组件,它能够很好的作为分布式缓存组件提供多个服务间的缓存,但是 Redis 这种还是需要网络开销,增加时耗.本地缓存是直接从本地内存中读取,没有网络开销,例如秒杀系统或者数据量小
-
spring boot+spring cache实现两级缓存(redis+caffeine)
spring boot中集成了spring cache,并有多种缓存方式的实现,如:Redis.Caffeine.JCache.EhCache等等.但如果只用一种缓存,要么会有较大的网络消耗(如Redis),要么就是内存占用太大(如Caffeine这种应用内存缓存).在很多场景下,可以结合起来实现一.二级缓存的方式,能够很大程度提高应用的处理效率. 内容说明: 缓存.两级缓存 spring cache:主要包含spring cache定义的接口方法说明和注解中的属性说明 spring boot
-
Spring Boot缓存实战 Caffeine示例
Caffeine和Spring Boot集成 Caffeine是使用Java8对Guava缓存的重写版本,在Spring Boot 2.0中将取代Guava.如果出现Caffeine,CaffeineCacheManager将会自动配置.使用spring.cache.cache-names属性可以在启动时创建缓存,并可以通过以下配置进行自定义(按顺序): spring.cache.caffeine.spec: 定义的特殊缓存 com.github.benmanes.caffeine.cache.
-
Springboot Caffeine本地缓存使用示例
Caffeine是使用Java8对Guava缓存的重写版本性能有很大提升 一 依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency> <!-- caffeine --> <dependency> <groupId&
-
SpringBoot+SpringCache实现两级缓存(Redis+Caffeine)
1. 缓存.两级缓存 1.1 内容说明 Spring cache:主要包含spring cache定义的接口方法说明和注解中的属性说明 springboot+spring cache:rediscache实现中的缺陷 caffeine简介 spring boot+spring cache实现两级缓存 使用缓存时的流程图 1.2 Sping Cache spring cache是spring-context包中提供的基于注解方式使用的缓存组件,定义了一些标准接口,通过实现这些接口,就可以通过在方法
-
详细介绍高性能Java缓存库Caffeine
1.介绍 在本文中,我们来看看Caffeine- 一个高性能的 Java 缓存库. 缓存和 Map 之间的一个根本区别在于缓存可以回收存储的 item. 回收策略为在指定时间删除哪些对象.此策略直接影响缓存的命中率 - 缓存库的一个重要特征. Caffeine 因使用 Window TinyLfu 回收策略,提供了一个近乎最佳的命中率. 2.依赖 我们需要在 pom.xml 中添加 caffeine 依赖: <dependency> <groupId>com.github.ben-
-
详解高性能缓存Caffeine原理及实战
目录 一.简介 二.Caffeine 原理 2.1.淘汰算法 2.1.1.常见算法 2.1.2.W-TinyLFU 算法 2.2.高性能读写 2.2.1.读缓冲 2.2.2.写缓冲 三.Caffeine 实战 3.1.配置参数 3.2.项目实战 四.总结 一.简介 下面是Caffeine 官方测试报告. 由上面三幅图可见:不管在并发读.并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件. 本文先介绍 Caffeine 实现原理,再讲解如何在项目中使用 Caffe
-
详解 Java HashMap 实现原理
HashMap 是 Java 中最常见数据结构之一,它能够在 O(1) 时间复杂度存储键值对和根据键值读取值操作.本文将分析其内部实现原理(基于 jdk1.8.0_231). 数据结构 HashMap 是基于哈希值的一种映射,所谓映射,即可以根据 key 获取到相应的 value.例如:数组是一种的映射,根据下标能够取到值.不过相对于数组,HashMap 占用的存储空间更小,复杂度却同样为 O(1). HashMap 内部定义了一排"桶",用一个叫 table 的 Node 数组表示:
-
详解App保活实现原理
概述 早期的 Android 系统不完善,导致 App 侧有很多空子可以钻,因此它们有着有着各种各样的姿势进行保活.譬如说在 Android 5.0 以前,App 内部通过 native 方式 fork 出来的进程是不受系统管控的,系统在杀 App 进程的时候,只会去杀 App 启动的 Java 进程:因此诞生了一大批"毒瘤",他们通过 fork native 进程,在 App 的 Java 进程被杀死的时候通过am命令拉起自己从而实现永生.那时候的 Android 可谓是魑魅横行,群
-
详解Redis数据类型实现原理
目录 1. 对象的类型与编码 ① type属性 ② encoding 属性和 *prt 指针 2. 字符串对象 ① 编码 ② 编码的转换 3. 列表对象 ① 编码 ② 编码转换 4. 哈希对象 ① 编码 ② 编码转换 5. 集合对象 ① 编码 ② 编码转换 6. 有序集合对象 ① 编码 ② 编码转换 7. 五大数据类型的应用场景 1. 对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Re
-
图文详解梯度下降算法的原理及Python实现
目录 1.引例 2.数值解法 3.梯度下降算法 4.代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何通过计算机算法编程求f(x)min? 2.数值解法 传统方法是数值解法,如图所示 按照以下步骤迭代循环直至最优: ① 任意给定一个初值x0: ② 随机生成增量方向,结合步长生成Δx: ③ 计算比较f(x0)与f(x0+Δx)的大小,若f(x0+Δx)<f(x0)则更新位置,否则重新生成Δx: ④ 重复②③直至收敛到最优f(x)min. 数值解法最大的优点是编程简明,但缺陷也很
-
图文详解牛顿迭代算法原理及Python实现
目录 1.引例 2.牛顿迭代算法求根 3.牛顿迭代优化 4 代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何计算函数零点x0 在数学上我们如何处理这个问题? 最简单的办法是解方程f(x)=0,在代数学上还有著名的零点判定定理 如果函数y=f(x)在区间[a,b]上的图象是连续不断的一条曲线,并且有f(a)⋅f(b)<0,那么函数y=f(x)在区间(a,b)内有零点,即至少存在一个c∈(a,b),使得f(c)=0,这个c也就是方程f(x)=0的根. 然而,数学上的方法并不一定
-
详解jquery选择器的原理
详解jquery选择器的原理 html部分 <!doctype html> <html lang="en"> <head> <meta charset="UTF-8" /> <title>Document</title> <script src="js/minijquery.js"></script> </head> <body>
-
详解C#扩展方法原理及其使用
1.写在前面 今天群里一个小伙伴问了这样一个问题,扩展方法与实例方法的执行顺序是什么样子的,谁先谁后(这个问题会在文章结尾回答).所以写了这边文章,力图从原理角度解释扩展方法及其使用. 以下为主要内容: 什么是扩展方法 扩展方法原理及自定义扩展方法 扩展方法的使用及其注意事项 2.什么是扩展方法 一般而言,扩展方法为现有类型添加新的方法(从面向对象的角度来说,是为现有对象添加新的行为)而无需修改原有类型,这是一种无侵入而且非常安全的方式.扩展方法是静态的,它的使用和其他实例方法几乎没有什么区别.
-
详解tensorflow之过拟合问题实战
过拟合问题实战 1.构建数据集 我们使用的数据集样本特性向量长度为 2,标签为 0 或 1,分别代表了 2 种类别.借助于 scikit-learn 库中提供的 make_moons 工具我们可以生成任意多数据的训练集. import matplotlib.pyplot as plt # 导入数据集生成工具 import numpy as np import seaborn as sns from sklearn.datasets import make_moons from sklearn.m
-
详解redis缓存与数据库一致性问题解决
数据库与缓存读写模式策略 写完数据库后是否需要马上更新缓存还是直接删除缓存? (1).如果写数据库的值与更新到缓存值是一样的,不需要经过任何的计算,可以马上更新缓存,但是如果对于那种写数据频繁而读数据少的场景并不合适这种解决方案,因为也许还没有查询就被删除或修改了,这样会浪费时间和资源 (2).如果写数据库的值与更新缓存的值不一致,写入缓存中的数据需要经过几个表的关联计算后得到的结果插入缓存中,那就没有必要马上更新缓存,只有删除缓存即可,等到查询的时候在去把计算后得到的结果插入到缓存中即可. 所