redis三种高可用方式部署的实现
前言
一、主从复制
概念
和mysql的主从复制一样 都是将服务器的数据复制到另一个数据库中 发送的称为master 接受的叫slave 数据为单向传输 只可以主到从
每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
作用
数据冗余 实现了数据的热备份,是持久化之外的一种数据冗余方式
故障切换 当主节点宕机或者出现错误时 由从服务器来提供服务 实现故障切换
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
基础 给集群和哨兵提供环境
主从复制过程
1 若启动一个Slave机器进程,则它会向Master机器发送一个“sync command”命令,请求同步连接。
2 无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照保存到数据文件中(执行rdb操作),同时Master还会记录修改数据的所有命令并缓存在数据文件中。
3 后台进程完成缓存操作之后,Maste机器就会向Slave机器发送数据文件,Slave端机器将数据文件保存到硬盘上,然后将其加载到内存中,接着Master机器就会将修改数据的所有操作一并发送给Slave端机器。若Slave出现故障导致宕机,则恢复正常后会自动重新连接。
4 Master机器收到Slave端机器的连接后,将其完整的数据文件发送给Slave端机器,如果Mater同时收到多个Slave发来的同步请求,则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的Slave端机器,确保所有的Slave端机器都正常。
部署
三台服务器 一主俩从

先部署redis 每台配置一致
systemctl stop firewalld setenforce 0 yum install -y gcc gcc-c++ make tar zxvf redis-5.0.7.tar.gz -C /opt/ cd /opt/redis-5.0.7/ make make PREFIX=/usr/local/redis install cd /opt/redis-5.0.7/utils ./install_server.sh 回车四次,之后输入可执行文件路径 Please select the redis executable path [] /usr/local/redis/bin/redis-server ln -s /usr/local/redis/bin/* /usr/local/bin/




主节点配置
vim /etc/redis/6379.conf bind 0.0.0.0 70行,修改bind 项,0.0.0.0监听所有网段 daemonize yes 137行,开启守护进程 logfile /var/log/redis_6379.log 172行,指定日志文件目录 dir /var/lib/redis/6379 264行,指定工作目录 appendonly yes 700行,开启AOF持久化功能 /etc/init.d/redis_6379 restart netstat -natp | grep 6379 检查端口是否开启





从节点配置
vim /etc/redis/6379.conf bind 0.0.0.0 70行,修改bind 项,0.0.0.0监听所有网卡 daemonize yes 137行,开启守护进程 logfile /var/log/redis_6379.log 172行,指定日志文件目录 dir /var/lib/redis/6379 264行,指定工作目录 replicaof 192.168.25.4 6379 288行,指定要同步的Master节点IP和端口 appendonly yes 700行,开启AOF持久化功能 /etc/init.d/redis_6379 restart







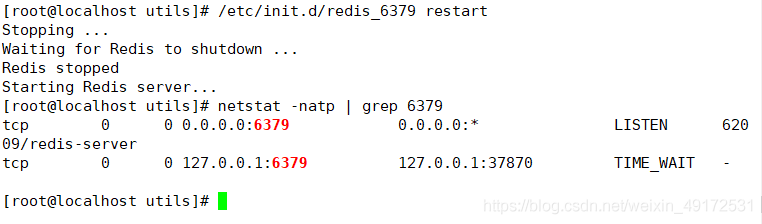
查看结果
在主节点查看日志
tail -f /var/log/redis_6379.log
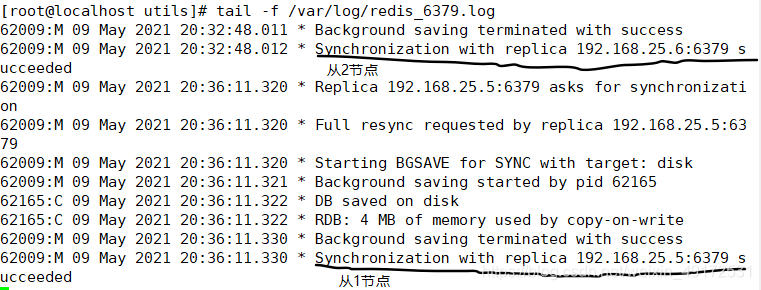
验证
# Replication role:master connected_slaves:2 slave0:ip=192.168.25.6,port=6379,state=online,offset=504,lag=1 slave1:ip=192.168.25.5,port=6379,state=online,offset=504,lag=0

二、哨兵模式
1 概念
是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 Master 并将所有 Slave 连接到新的 Master。所以整个运行哨兵的集群的数量不得少于3个节点。
2.作用
- 监控:哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 通知(提醒):哨兵可以将故障转移的结果发送给客户端。
3 组成
- 哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
- 数据节点:主节点和从节点都是数据节点。
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式,所有节点上都需要部署哨兵模式,哨兵模式会监控所有的 Redis 工作节点是否正常,当 Master 出现问题的时候,因为其他节点与主节点失去联系,因此会投票,投票过半就认为这个 Master 的确出现问题,然后会通知哨兵间,然后从 Slaves 中选取一个作为新的 Master。
主观下线和客观下线
主观下线是指哨兵节点会每秒一次的频率向建立了命令节点的实例发送ping命令,如果在 down-after-milliseconds 毫秒内没有做出有效响应包括(pong/loading/masterdown)以外的响应,哨兵就会将该实例在本结构体中的状态标记为 sri_s_down 主观下线
客观下线是指当一个哨兵节点发现主节点处于主观下线状态时,就会向其他的哨兵节点发出询问,该节点是否已经主观下线。如果超过配置参数 quorum 个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为 sri_o_down 客观下线
部署
所有的节点都要部署哨兵
vim /opt/redis-5.0.7/sentinel.conf protected-mode no #17行,关闭保护模式 port 26379 #21行,Redis哨兵默认的监听端口 daemonize yes #26行,指定sentinel为后台启动 logfile "/var/log/sentinel.log" #36行,指定日志存放路径 dir "/var/lib/redis/6379" #65行,指定数据库存放路径 sentinel monitor mymaster 192.168.184.10 6379 2 #84行,修改 指定该哨兵节点监控192.168.184.10:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移 sentinel down-after-milliseconds mymaster 30000 #113行,判定服务器down掉的时间周期,默认30000毫秒(30秒) sentinel failover-timeout mymaster 180000 #146行,故障节点的最大超时时间为180000(180秒)





开启哨兵
先开master 后开slave



模拟故障
查询主节点redis服务节点号
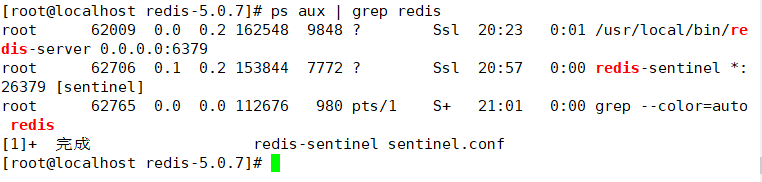
杀掉主节点进程 并查看日志
kill -9 62009 tail -f /var/log/sentinel.log

查看现在的主节点 现在主节点切换到slave1

三 集群
1 概念
集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。
集群由多个节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
2 作用
1 数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
2 高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
3、Redis集群的数据分片
Redis集群引入了哈希槽的概念
Redis集群有16384个哈希槽(编号0-16383)
集群的每个节点负责一部分哈希槽
每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
#以3个节点组成的集群为例:
节点A包含0到5460号哈希槽
节点B包含5461到10922号哈希槽
节点C包含10923到16383号哈希槽
Redis集群的主从复制模型
集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。
为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为的主节点继续服务。当B和B1都失败后,集群将不可用
部署
注意6个端口和IP都要不一样。 vim /etc/redis/6379.conf bind 192.168.25.4 70行,修改bind项,监听自己的IP protected-mode no 89行,修改,关闭保护模式 port 7001 93行,修改,redis监听端口, daemonize yes 137行,以独立进程启动 cluster-enabled yes 833行,取消注释,开启群集功能 cluster-config-file nodes-6379.conf 841行,取消注释,群集名称文件设置,无需修改 cluster-node-timeout 15000 847行,取消注释群集超时时间设置 appendonly yes 700行,修改,开启AOF持久化 #重启服务 /etc/init.d/redis_6379 restart #加入集群 redis-cli --cluster create 192.168.25.4:7001 192.168.25.5:7003 192.168.25.6:7005 192.168.25.7:7006 192.168.25.8:7007 192.168.25.9:7008 --cluster-replicas 1 redis-cli -h 192.168.25.4 -p 7001 -c #加-c参数,节点之间就可以互相跳转 cluster slots #查看节点的哈希槽编号范围 set sky x1 cluster keyslot x1 #查看name键的槽编号












到此这篇关于redis三种高可用方式部署的实现的文章就介绍到这了,更多相关redis 高可用方式部署内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Redis5之后版本的高可用集群搭建的实现
一.安装redis 1.安装gcc yum install gcc 2.下载redis-5.0.8.tar.gz 3.把下载好的redis-5.0.8.tar.gz放在/gyu/software文件夹下,并解压 > tar xzf redis-5.0.8.tar.gz > cd redis-5.0.8 4.进入到解压好的redis-5.0.8目录下,进行编译与安装 > make & make install 5.启动并指定配置文件 > src/redis-server re
-
详解三分钟快速搭建分布式高可用的Redis集群
这里的Redis集群指的是Redis Cluster,它是Redis在3.0版本正式推出的专用集群方案,有效地解决了Redis分布式方面的需求.当单机内存.并发.流量等遇到瓶颈的时候,可以采用这种Redis Cluster方案进行解决. 分区规则 Redis Cluster采用虚拟槽(slot)进行数据分区,即使用分散度良好的哈希函数把所有键映射到一个固定范围的整数集合里,这里的整数就是槽(slot).Redis Cluster槽的范围是0~16383,计算公式:slot=CRC16(key)
-
Redis服务之高可用组件sentinel详解
前文我们了解了redis的常用数据类型相关命令的使用和说明,回顾请参考https://www.jb51.net/article/120364.htm 今天我们来聊一下redis的高可用组件sentinel:首先来回顾下redis的主从同步,主从同步最主要的作用是让master的数据在其他服务器上实时存在副本,起到了备份的效果:对于redis的读写来说,主从架构能够让读的请求分散到多个从服务器上,从而降低了单台redis读请求的io压力,同时也提高了redis读请求的并发能力:通常为了数据的一致性
-
redis三种高可用方式部署的实现
前言 一.主从复制 概念 和mysql的主从复制一样 都是将服务器的数据复制到另一个数据库中 发送的称为master 接受的叫slave 数据为单向传输 只可以主到从 每台Redis服务器都是主节点:且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点. 作用 数据冗余 实现了数据的热备份,是持久化之外的一种数据冗余方式 故障切换 当主节点宕机或者出现错误时 由从服务器来提供服务 实现故障切换 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供
-
redis客户端实现高可用读写分离的方式详解
背景 (1) redis单机的读写性能轻松上大几万,不过线上环境不会只部署光秃秃的一个节点,还是会配合 sentinel 再部署一个 slave作为高可用节点的: 但是standby的slave节点是不对外提供服务端的,一定程度上造成了浪费资源 (2) 当业务不断发展,原来单节点缓存的数据(如,商品信息缓存.配置信息等)的查询qps不断升高(写qps增长不多),突破十几万.几十万的的时候,此时一个节点就扛不住了,我们就需要增加几个redis slaves节点来分担这些查询的压力 也就是读写分离
-
Redis三种集群模式详解
目录 三种集群模式 一.主从复制 1.reids主从模式 2.redis复制原理 3.redis主从复制原理 4.redis主从复制优缺点 二.Sentinel 哨兵模式 1.Sentinel系统 2.Sentinel故障转移 2.1.Sentinel 哨兵监控过程 2.2.Sentinel 哨兵故障转移 3.Sentinel 哨兵优缺点 三.cluster 模式 1.reids cluster 2.Redis Cluster 数据分片原理 3.Redis Cluster 复制原理 4.redi
-
浅谈Redis哨兵模式高可用解决方案
目录 一.序言 1.目标与收获 2.端口规划 二.单机模拟 (一)服务规划 1.Redis实例 2.哨兵服务 (二)服务配置 1.Redis实例 2.哨兵服务 (三)服务管理 1.Redis实例 2.哨兵服务 三.客户端整合 (一)基础整合 1.全局配置文件 2.集成配置 (二)读写分离 一.序言 Redis高可用有两种模式:哨兵模式和集群模式,本文基于哨兵模式搭建一主两从三哨兵Redis高可用服务. 1.目标与收获 一主两从三哨兵Redis服务,基本能够满足中小型项目的高可用要求,使用Supe
-
redis sentinel监控高可用集群实现的配置步骤
目录 一.端口转发. 如果在一个主机里面,安装了两个redis实例,可以在项目里面配置IP端口,用iptables转发. iptables -t nat -A PREROUTING -p tcp --dport 6379 -j REDIRECT --to-ports 7379 当发生切换的时候,触发了脚本,执行语句.端口可以马上转发带正确的redis上面.参数的含义: 脚本配置: 脚本实例: #!/bin/bash iptables -t nat -I PREROUTING -p tcp --d
-
redis sentinel监控高可用集群实现的配置步骤
目录 一.端口转发 二.修改HOST文件 三.用第三方代理haproxy 四.插曲 一.端口转发 如果在一个主机里面,安装了两个redis实例,可以在项目里面配置IP端口,用iptables转发. iptables -t nat -A PREROUTING -p tcp --dport 6379 -j REDIRECT --to-ports 7379 当发生切换的时候,触发了脚本,执行语句.端口可以马上转发带正确的redis上面.参数的含义: 脚本配置: 脚本实例: #!/bin/bash i
-
VMware的三种网络连接方式区别
关于VMware的三种网络连接方式,NAT,Bridged,Host-Only ,在刚接触的时候通常会遇到主机Ping不通虚拟机而虚拟机能Ping得通主机:主机与虚拟机互不相通等等网络问题.本文就这三种连接方式作一一说明,也方便以后翻阅当参考用. 首先,要注意安装完VMware后,控制面板\网络和 Internet\网络连接会多出两块虚拟网卡VMnet1.VMnet2,两个网卡各有用途. 基本拓扑 NAT(网络地址转换) 依靠物理主机的VMnet8网卡上网.虚拟机可以互Ping通,前提是物理主机
-
Redis三种特殊数据类型的具体使用
目录 一.HyperLogLog基数统计 1.1什么是基数? 1.2使用基数统计的好处 1.3应用场景 1.4注意事项 1.5基本命令 1.6使用 二.Geospatial地理位置 2.1介绍 2.2使用场景 2.3基本命令 2.4详细讲解 2.4.1GEOADD 2.4.2GEOPOS 2.4.3GEODIST 2.4.4GEORADIUS 2.4.5GEORADIUSBYMEMBER 2.4.6GEOHASH 2.4.7ZRANGE 2.4.8ZREM 三.BitMap 介绍 小结 一.Hy
-
强烈推荐MyBatis 三种批量插入方式的比较
目录 前言 代码 拼接SQL的xml Service类 测试类 测试结果 结论 前言 数据库使用的是SQLServer,JDK版本1.8,运行在SpringBoot环境下 对比3种可用的方式: 反复执行单条插入语句 xml拼接sql 批处理执行 先说结论:少量插入请使用反复插入单条数据,方便.数量较多请使用批处理方式.(可以考虑以有需求的插入数据量20条左右为界吧,在我的测试和数据库环境下耗时都是百毫秒级的,方便最重要) 无论何时都不用xml拼接sql的方式. 代码 拼接SQL的xml newI