Python查找算法之折半查找算法的实现
一、折半查找算法
折半查找算法又称为二分查找算法,折半查找算法是将数据分割成两等份,首先用键值(要查找的数据)与中间值进行比较。如果键值小于中间值,可确定要查找的键值在前半段;如果键值大于中间值,可确定要查找的键值在后半段。然后对前半段(后半段)进行分割,将其分成两等份,再对比键值。如此循环比较、分割,直到找到数据或者确定数据不存在为止。折半查找的缺点是只适用于已经初步排序好的数列;优点是查找速度快。
生活中也有类似于折半查找的例子,例如,猜数字游戏。在游戏开始之前,首先会给出一定的数字范围(例如0~100),并在这个范围内选择一个数字作为需要被猜的数字。然后让用户去猜,并根据用户猜的数字给出提示(如猜大了或猜小了)。用户通常的做法就是先在大范围内随意说一个数字,然后提示猜大了/猜小了,这样就缩小了猜数字的范围,慢慢地就猜到了正确的数字,如下图所示。这种做法与折半查找法类似,都是通过不断缩小数字范围来确定数字,如果每次猜的范围值都是区间的中间值,就是折半查找算法了。
例如,已经有 排序好 的数列:12、45、56、66、77、80、97、101、120,要查找的数据是 101,用折半查找步骤如下:
步骤1:将数据列出来并找到中间值 77,将 101 与 77 进行比较,如下图所示。
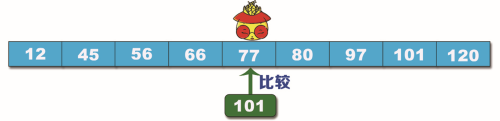
步骤2:将 101 与 77 进行比较,结果是 101 大于 77,说明要查找的数据在数列的右半段。此时不考虑左半段的数据,对在右半段的数据再进行分割,找中间值。这次中间值的位置在 97 和 101 之间,取 97,将 101 与 97 进行比较,如下图所示。

步骤3:将 101 与 97 进行比较,结果是 101 大于 97,说明要查找的数据在右半段数列中,此时不考虑左半段的数据,再对剩下的数列分割,找中间值,这次中间值位置是 101,将 101 与 101 进行比较,如下图所示。

步骤4:将 101 与 101 进行比较,所得结果相等,查找完成。说明:如果多次分割之后没有找到相等的值,表示这个键值没有在这个数列中。
从折半法查找的步骤来看,明显比顺序查找法的次数少,这就是折半查找法的优点:查找速度快。
二、实例:线路故障
有一条的150米线路,在这条线路上存在故障。第一天维修工已经大致锁定了几个疑似故障点,疑似故障点分别在线路的12、45、56、66、77、80、97、101、120米处。第二天维修工要在这9个疑似故障点中确定一个真正的故障点(假设真正的故障点是101米处)。维修工为了快速查找此故障点,就在每段数据的中间位置开始排查。
例如,第一次选择在77米处的疑似故障点接通电路,发现接通,他判断此故障在77米之后的位置;第二次取97米处的疑似故障点,发现也接通了,说明在97米之后的位置;第三次取101米处的位置,再次接通线路,发现未接通,说明此处是真正的故障点。此次查找经历了3次,将真正故障点找到。具体代码如下:
def search(data, num):
"""
定义查找函数:该函数使用的是折半查找算法
:param data: 原数列data
:param num: 键值num
:return:
"""
low = 0 # 定义变量用来表示低位
high = len(data) - 1 # 定义变量用来表示高位
print("正在查找.......") # 提示
while low <= high and num != -1:
mid = int((low + high) / 2) # 取中间位置
if num < data[mid]: # 判断数据是否小于中间值
# 输出位置在数列中的左半边
print(f"{num} 介于中间故障点 {low + 1}[{data[low]}] 和故障点位置 {mid + 1}[{data[mid]}] 之间,找左半边......")
high = mid - 1 # 最高位变成了中间位置减1
elif num > data[mid]: # 判断数据是否大于中间值
# 输出位置在数列中的右半边
print(f"{num} 介于中间故障点 {mid + 1}[{data[mid]}] 和故障点位置 {high + 1}[{data[high]}] 之间,找右半边......")
low = mid + 1 # 最低位变成了中间位置加1
else: # 判断数据是否等于中间值
return mid # 返回中间位置
return -1 # 自定义函数到此结束
inp_num = 0 # 定义变量,用来输入键值
num_list = [12, 45, 56, 66, 77, 80, 97, 101, 120] # 定义数列
print("疑似故障点如下:")
for index, ele in enumerate(num_list):
print(f" {index + 1}[{ele}]", end="") # 输出数列
print("")
flag = True # 开关,用来管控是否多次查找
while flag: # 循环查找
inp_num = int(input("请输入故障点:").strip()) # 输入查找键值
if inp_num == -1: # 判断键值是否是-1
break # 若为-1,跳出循环 即结束程序
result = search(num_list, inp_num) # 调用自定义的查找函数——search()函数
if result == -1: # 判断查找结果是否是-1
print(f"没有找到[{inp_num}]故障点") # 若为-1,提示没有找到值
else:
# 若不为-1,提示查找位置
print(f"在{result + 1}个位置找到[{num_list[result]}]故障点")
char = input("本次查找结束,是否继续查找,请输入 y(Y) 或 n(N):").strip()
if char.upper() == "N":
flag = False
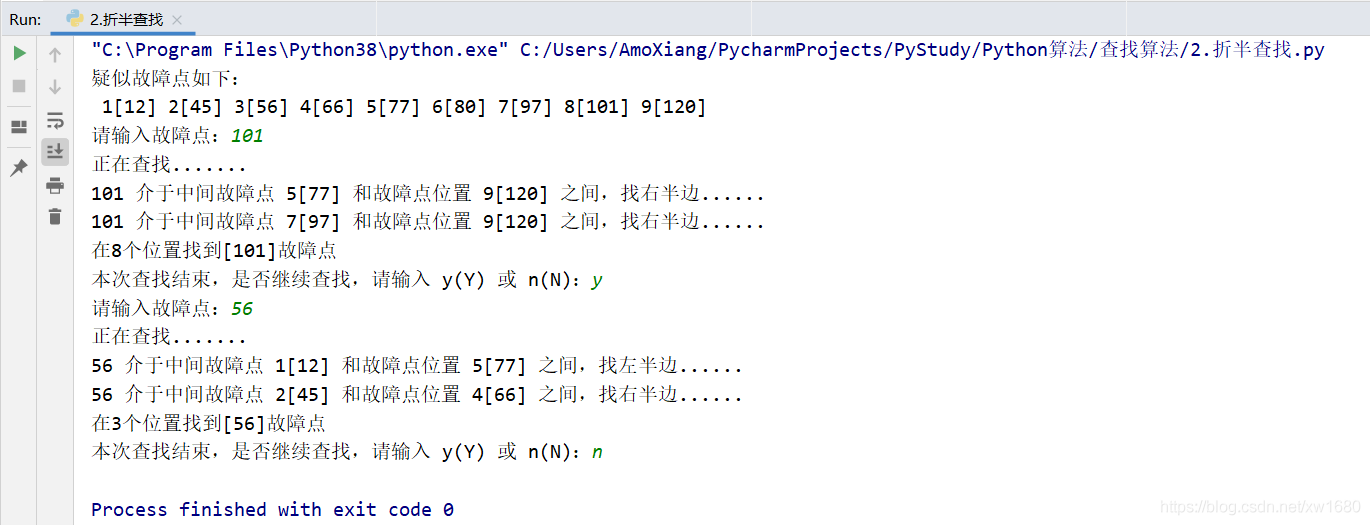
程序执行结果如下图所示:
到此这篇关于Python查找算法之折半查找算法的实现的文章就介绍到这了,更多相关Python 折半查找算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现随机爬山算法
随机爬山是一种优化算法.它利用随机性作为搜索过程的一部分.这使得该算法适用于非线性目标函数,而其他局部搜索算法不能很好地运行.它也是一种局部搜索算法,这意味着它修改了单个解决方案并搜索搜索空间的相对局部区域,直到找到局部最优值为止.这意味着它适用于单峰优化问题或在应用全局优化算法后使用. 在本教程中,您将发现用于函数优化的爬山优化算法完成本教程后,您将知道: 爬山是用于功能优化的随机局部搜索算法. 如何在Python中从头开始实现爬山算法. 如何应用爬山算法并检查算法结果. 教程概述 本教程分为
-
Python查找算法之插补查找算法的实现
一.插补查找算法 插补查找算法又称为插值查找,它是折半查找算法的改进版.插补查找是按照数据的分布,利用公式预测键值所在的位置,快速缩小键值所在序列的范围,慢慢逼近,直到查找到数据为止.根据描述来看,插值查找类似于平常查英文字典的方法.例如,在查一个以字母 D 开头的英文单词时,决不会用折半查找法.根据英文词典的查找顺序可知,D 开头的单词应该在字典较前的部分,因此可以从字典前部的某处开始查找.键值的索引计算,公式如下: middle=left+(target-data[left])/(data[
-
Python实现七大查找算法的示例代码
查找算法 -- 简介 查找(Searching)就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素. 查找表(Search Table):由同一类型的数据元素构成的集合 关键字(Key):数据元素中某个数据项的值,又称为键值 主键(Primary Key):可唯一的标识某个数据元素或记录的关键字 查找表按照操作方式可分为: 1.静态查找表(Static Search Table):只做查找操作的查找表.它的主要操作是: ①
-
python高效的素数判断算法
高效素数判断算法 算法概述 此算法将其他博主对基本素数算法的一些改进进行了整合,其中主要整合了如下三条规则: 1.大于3的素数一定在6的倍数前一个或后一个(如素数37在36的后面) 2.要判断n是否为素数,只需要让n从2开始,依次除到根号n即可 3.在进行"让n从2开始,依次除到根号n"过程中,若n除以2的余数不为0,可以直接跳过[2, sqrt(n)]里面的所有偶数 博主语文素养不高,表达不是很准确,在后面会对这三条规则进行解释. 规则详解 1.大于3的素数一定在6的倍数前一个或后一
-
python 图像增强算法实现详解
使用python编写了共六种图像增强算法: 1)基于直方图均衡化 2)基于拉普拉斯算子 3)基于对数变换 4)基于伽马变换 5)限制对比度自适应直方图均衡化:CLAHE 6)retinex-SSR 7)retinex-MSR其中,6和7属于同一种下的变化. 将每种方法编写成一个函数,封装,可以直接在主函数中调用. 采用同一幅图进行效果对比. 图像增强的效果为: 直方图均衡化:对比度较低的图像适合使用直方图均衡化方法来增强图像细节 拉普拉斯算子可以增强局部的图像对比度 log对数变换对于整体对比度
-
python入门之算法学习
前言 参考学习书籍:<算法图解>[美]Aditya Bhargava,袁国忠(译)北京人民邮电出版社,2017 二分查找 binary_search 实现二分查找的python代码如下: def binary_search(list, item): low = 0 #最低位索引位置为0 high = len(list)- 1 #最高位索引位置为总长度-1 while low <= high: mid = (low + high)//2 #检查中间的元素,书上是一条斜杠,我试过加两条斜杠才
-
Python实现粒子群算法的示例
粒子群算法是一种基于鸟类觅食开发出来的优化算法,它是从随机解出发,通过迭代寻找最优解,通过适应度来评价解的品质. PSO算法的搜索性能取决于其全局探索和局部细化的平衡,这在很大程度上依赖于算法的控制参数,包括粒子群初始化.惯性因子w.最大飞翔速度和加速常数与等. PSO算法具有以下优点: 不依赖于问题信息,采用实数求解,算法通用性强. 需要调整的参数少,原理简单,容易实现,这是PSO算法的最大优点. 协同搜索,同时利用个体局部信息和群体全局信息指导搜索. 收敛速度快, 算法对计算机内存和CPU要
-
python实现线性回归算法
本文用python实现线性回归算法,供大家参考,具体内容如下 # -*- coding: utf-8 -*- """ Created on Fri Oct 11 19:25:11 2019 """ from sklearn import datasets, linear_model # 引用 sklearn库,主要为了使用其中的线性回归模块 # 创建数据集,把数据写入到numpy数组 import numpy as np # 引用numpy库,主
-
python实现ROA算子边缘检测算法
python实现ROA算子边缘检测算法的具体代码,供大家参考,具体内容如下 代码 import numpy as np import cv2 as cv def ROA(image_path, save_path, threshold): img = cv.imread(image_path) image = cv.cvtColor(img, cv.COLOR_RGB2GRAY) new = np.zeros((512, 512), dtype=np.float64) # 开辟存储空间 widt
-
python中K-means算法基础知识点
能够学习和掌握编程,最好的学习方式,就是去掌握基本的使用技巧,再多的概念意义,总归都是为了使用服务的,K-means算法又叫K-均值算法,是非监督学习中的聚类算法.主要有三个元素,其中N是元素个数,x表示元素,c(j)表示第j簇的质心,下面就使用方式给大家简单介绍实例使用. K-Means算法进行聚类分析 km = KMeans(n_clusters = 3) km.fit(X) centers = km.cluster_centers_ print(centers) 三个簇的中心点坐标为: [