在Tensorflow中实现leakyRelu操作详解(高效)
从github上转来,实在是厉害的想法,什么时候自己也能写出这种精妙的代码就好了
原地址:简易高效的LeakyReLu实现
代码如下:
我做了些改进,因为实在tensorflow中使用,就将原来的abs()函数替换成了tf.abs()
import tensorflow as tf
def LeakyRelu(x, leak=0.2, name="LeakyRelu"):
with tf.variable_scope(name):
f1 = 0.5 * (1 + leak)
f2 = 0.5 * (1 - leak)
return f1 * x + f2 * tf.abs(x) # 这里和原文有不一样的,我没试验过原文的代码,但tf.abs()肯定是对的
补充知识:激活函数ReLU、Leaky ReLU、PReLU和RReLU
“激活函数”能分成两类——“饱和激活函数”和“非饱和激活函数”。
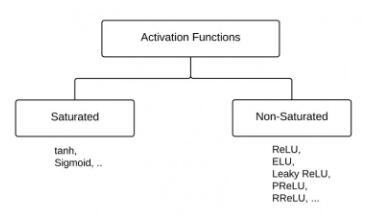
sigmoid和tanh是“饱和激活函数”,而ReLU及其变体则是“非饱和激活函数”。使用“非饱和激活函数”的优势在于两点:
1.首先,“非饱和激活函数”能解决所谓的“梯度消失”问题。
2.其次,它能加快收敛速度。
Sigmoid函数需要一个实值输入压缩至[0,1]的范围
σ(x) = 1 / (1 + exp(−x))
tanh函数需要讲一个实值输入压缩至 [-1, 1]的范围
tanh(x) = 2σ(2x) − 1
ReLU
ReLU函数代表的的是“修正线性单元”,它是带有卷积图像的输入x的最大函数(x,o)。ReLU函数将矩阵x内所有负值都设为零,其余的值不变。ReLU函数的计算是在卷积之后进行的,因此它与tanh函数和sigmoid函数一样,同属于“非线性激活函数”。这一内容是由Geoff Hinton首次提出的。
ELUs
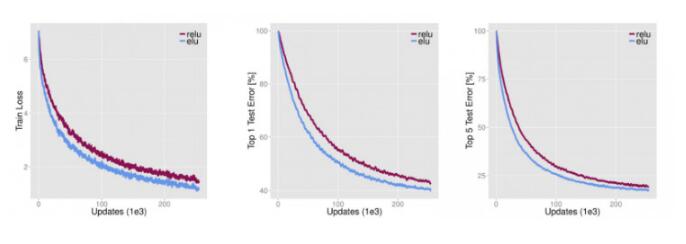
ELUs是“指数线性单元”,它试图将激活函数的平均值接近零,从而加快学习的速度。同时,它还能通过正值的标识来避免梯度消失的问题。根据一些研究,ELUs分类精确度是高于ReLUs的。下面是关于ELU细节信息的详细介绍:
Leaky ReLUs
ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。Leaky ReLU激活函数是在声学模型(2013)中首次提出的。以数学的方式我们可以表示为:

ai是(1,+∞)区间内的固定参数。
参数化修正线性单元(PReLU)
PReLU可以看作是Leaky ReLU的一个变体。在PReLU中,负值部分的斜率是根据数据来定的,而非预先定义的。作者称,在ImageNet分类(2015,Russakovsky等)上,PReLU是超越人类分类水平的关键所在。
随机纠正线性单元(RReLU)
“随机纠正线性单元”RReLU也是Leaky ReLU的一个变体。在RReLU中,负值的斜率在训练中是随机的,在之后的测试中就变成了固定的了。RReLU的亮点在于,在训练环节中,aji是从一个均匀的分布U(I,u)中随机抽取的数值。形式上来说,我们能得到以下结果:
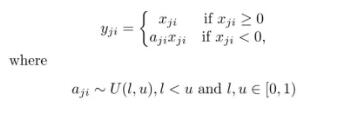
总结
下图是ReLU、Leaky ReLU、PReLU和RReLU的比较:
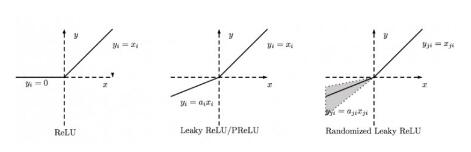
PReLU中的ai是根据数据变化的;
Leaky ReLU中的ai是固定的;
RReLU中的aji是一个在一个给定的范围内随机抽取的值,这个值在测试环节就会固定下来。
以上这篇在Tensorflow中实现leakyRelu操作详解(高效)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
TensorFlow损失函数专题详解
一.分类问题损失函数--交叉熵(crossentropy) 交叉熵刻画了两个概率分布之间的距离,是分类问题中使用广泛的损失函数.给定两个概率分布p和q,交叉熵刻画的是两个概率分布之间的距离: 我们可以通过Softmax回归将神经网络前向传播得到的结果变成交叉熵要求的概率分布得分.在TensorFlow中,Softmax回归的参数被去掉了,只是一个额外的处理层,将神经网络的输出变成一个概率分布. 代码实现: import tensorflow as tf y_ = tf.constant([[1.
-
TensorFlow设置日志级别的几种方式小结
TensorFlow中的log共有INFO.WARN.ERROR.FATAL 4种级别.有以下几种设置方式. 1. 通过设置环境变量控制log级别 可以通过环境变量TF_CPP_MIN_LOG_LEVEL进行设置,TF_CPP_MIN_LOG_LEVEL的不同值的含义分别如下: Level Level for Humans Level Description 0 DEBUG all messages are logged (Default) 1 INFO INFO messages are no
-
tensorflow自定义激活函数实例
前言:因为研究工作的需要,要更改激活函数以适应自己的网络模型,但是单纯的函数替换会训练导致不能收敛.这里还有些不清楚为什么,希望有人可以给出解释.查了一些博客,发现了解决之道.下面将解决过程贴出来供大家指正. 1.背景 之前听某位老师提到说tensorflow可以在不给梯度函数的基础上做梯度下降,所以尝试了替换.我的例子时将ReLU改为平方.即原来的激活函数是 现在换成 单纯替换激活函数并不能较好的效果,在我的实验中,迭代到一定批次,准确率就会下降,最终降为10%左右保持稳定.而事实上,这中间最
-
TensorFlow实现批量归一化操作的示例
批量归一化 在对神经网络的优化方法中,有一种使用十分广泛的方法--批量归一化,使得神经网络的识别准确度得到了极大的提升. 在网络的前向计算过程中,当输出的数据不再同一分布时,可能会使得loss的值非常大,使得网络无法进行计算.产生梯度爆炸的原因是因为网络的内部协变量转移,即正向传播的不同层参数会将反向训练计算时参照的数据样本分布改变.批量归一化的目的,就是要最大限度地保证每次的正向传播输出在同一分布上,这样反向计算时参照的数据样本分布就会与正向计算时的数据分布一样了,保证分布的统一. 了解了原理
-
在Tensorflow中实现leakyRelu操作详解(高效)
从github上转来,实在是厉害的想法,什么时候自己也能写出这种精妙的代码就好了 原地址:简易高效的LeakyReLu实现 代码如下: 我做了些改进,因为实在tensorflow中使用,就将原来的abs()函数替换成了tf.abs() import tensorflow as tf def LeakyRelu(x, leak=0.2, name="LeakyRelu"): with tf.variable_scope(name): f1 = 0.5 * (1 + leak) f2 =
-
jQuery中的select操作详解
下面给大介绍了jquery对select的操作介绍,非常不错,具有内容介绍如下所示: select的html标签如下: <select class="xxx" id="yyy"><option></option>...<option></option></select> 1.设置value为"lll"的option选中 $('#yyy').val("lll"
-
对TensorFlow中的variables_to_restore函数详解
variables_to_restore函数,是TensorFlow为滑动平均值提供.之前,也介绍过通过使用滑动平均值可以让神经网络模型更加的健壮.我们也知道,其实在TensorFlow中,变量的滑动平均值都是由影子变量所维护的,如果你想要获取变量的滑动平均值需要获取的是影子变量而不是变量本身. 1.滑动平均值模型文件的保存 import tensorflow as tf if __name__ == "__main__": v = tf.Variable(0.,name="
-
对tf.reduce_sum tensorflow维度上的操作详解
tensorflow中有很多在维度上的操作,本例以常用的tf.reduce_sum进行说明.官方给的api reduce_sum( input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None ) input_tensor:表示输入 axis:表示在那个维度进行sum操作. keep_dims:表示是否保留原始数据的维度,False相当于执行完后原始数据就会少一个维度. reduction_indices:
-
对Tensorflow中的矩阵运算函数详解
tf.diag(diagonal,name=None) #生成对角矩阵 import tensorflowas tf; diagonal=[1,1,1,1] with tf.Session() as sess: print(sess.run(tf.diag(diagonal))) #输出的结果为[[1 0 0 0] [0 1 0 0] [0 0 1 0] [0 0 0 1]] tf.diag_part(input,name=None) #功能与tf.diag函数相反,返回对角阵的对角元素 imp
-

C语言中的文件操作详解
目录 1.为什么使用文件 2.什么是文件 2.1程序文件 2.2数据文件 2.3文件名 3.文件的打开和关闭 3.1文件指针 3.2文件的打开和关闭 4.文件的顺序读写 5.文件的随机读写 5.1fseek 5.2ftell 5.3rewind 6.文本文件和二进制文件 7.文件读取结束的判定 7.1被错误使用的feof 8.文件缓冲区 结论 1.为什么使用文件 在学习结构体时,写了一个简易的通讯录的程序,当程序运行起来的时候,可以在通讯录中增加和删除数据,此时数据是存放在内存当中的,当程序退出
-
MySQL中数据视图操作详解
目录 1.视图概述 1.1创建视图 1.2视图的查询 2.操作视图 2.1通过视图操作数据 2.2修改视图定义 2.3删除视图 1.视图概述 视图是从一个或多个表(或视图)导出的表.视图与表(有时为与视图区别,也称表为基本表)不同,视图是一个虚表,即视图所对应的数据不进行实际存储,数据库中只存储视图的定义,对视图的数据进行操作时,系统根据视图的定义去操作与视图相关联的基本表. 视图一经定义,就可以像表一样被查询.修改.删除和更新.使用视图有下列优点: 1.为用户集中数据,简化用户的数据查询和处理
-
MongoDB中的push操作详解(将文档插入到数组)
目录 1. 概述 2. 数据库初始化 3. 使用 Mongo Query 进行推送操作 4. 使用Java驱动代码进行推送操作 4.1. 使用 DBObject 4.2. 使用 BSON 文档 5. 使用 addToSet操作符 5.1. 使用addToSet运算符的 Shell 查询 5.2. 使用addToSet运算符的 Java 驱动程序 6. 结论 总结 1. 概述 在本教程中,我们将介绍如何在MongoDB中将文档插入到数组中.此外,我们将看到 $push 和 $addToset 运算
-
Angular2学习教程之组件中的DOM操作详解
前言 有时不得不面对一些需要在组件中直接操作DOM的情况,如我们的组件中存在大量的CheckBox,我们想获取到被选中的CheckBox,然而这些CheckBox是通过循环产生的,我们无法给每一个CheckBox指定一个ID,这个时候可以通过操作DOM来实现.angular API中包含有viewChild,contentChild等修饰符,这些修饰符可以返回模板中的DOM元素. 指令中的DOM操作 @Directive({ selector: 'p' }) export class TodoD
-
Swift中的指针操作详解
前言 Objective-C和C语言经常需要使用到指针.Swift中的数据类型由于良好的设计,使其可以和基于指针的C语言API无缝混用.但是语法上有很大的差别. 默认情况下,Swift 是内存安全的,这意味着它禁止我们直接操作内存,并且确保所有的变量在使用前都已经被正确地初始化了.但是,Swift 也提供了我们使用指针直接操作内存的方法,直接操作内存是很危险的行为,很容易就出现错误,因此官方将直接操作内存称为 "unsafe 特性". 一旦我们开始直接操作内存,一切就得靠我们自己了,因