python人工智能tensorflow函数tf.nn.dropout使用方法
目录
- 前言
- tf.nn.dropout函数介绍
- 例子
- 代码
- keep_prob = 0.5
- keep_prob = 1
前言
神经网络在设置的神经网络足够复杂的情况下,可以无限逼近一段非线性连续函数,但是如果神经网络设置的足够复杂,将会导致过拟合(overfitting)的出现,就好像下图这样。
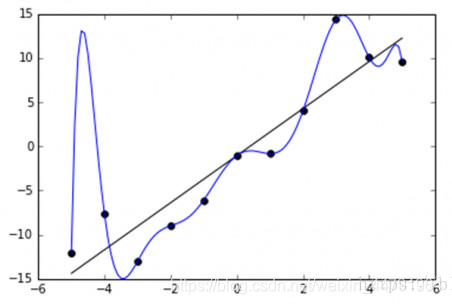
看到这个蓝色曲线,我就知道:
很明显蓝色曲线是overfitting的结果,尽管它很好的拟合了每一个点的位置,但是曲线是歪歪曲曲扭扭捏捏的,这个的曲线不具有良好的鲁棒性,在实际工程实验中,我们更希望得到如黑色线一样的曲线。
tf.nn.dropout函数介绍
tf.nn.dropout是tensorflow的好朋友,它的作用是为了减轻过拟合带来的问题而使用的函数,它一般用在每个连接层的输出。
Dropout就是在不同的训练过程中,按照一定概率使得某些神经元停止工作。也就是让每个神经元按照一定的概率停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重依然存在,下次更新时可能会使用到它。
def dropout(x, keep_prob, noise_shape=None, seed=None, name=None)
x 一般是每一层的输出
keep_prob,保留keep_prob的神经元继续工作,其余的停止工作与更新
在实际定义每一层神经元的时候,可以加入dropout。
def add_layer(inputs,in_size,out_size,n_layer,activation_function = None,keep_prob = 1):
layer_name = 'layer%s'%n_layer
with tf.name_scope(layer_name):
with tf.name_scope("Weights"):
Weights = tf.Variable(tf.random_normal([in_size,out_size]),name = "Weights")
tf.summary.histogram(layer_name+"/weights",Weights)
with tf.name_scope("biases"):
biases = tf.Variable(tf.zeros([1,out_size]) + 0.1,name = "biases")
tf.summary.histogram(layer_name+"/biases",biases)
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.matmul(inputs,Weights) + biases
#dropout一般加载每个神经层的输出
Wx_plus_b = tf.nn.dropout(Wx_plus_b,keep_prob)
#看这里看这里,dropout在这里。
tf.summary.histogram(layer_name+"/Wx_plus_b",Wx_plus_b)
if activation_function == None :
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+"/outputs",outputs)
return outputs
但需要注意的是,神经元的输出层不可以定义dropout参数。因为输出层就是输出的是结果,在输出层定义参数的话,就会导致输出结果被dropout掉。
例子
本次例子使用sklearn.datasets,在进行测试的时候,我们只需要改变最下方keep_prob:0.5的值即可,1代表不进行dropout。
代码
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train,X_test,Y_train,Y_test = train_test_split(X,y,test_size = 500)
def add_layer(inputs,in_size,out_size,n_layer,activation_function = None,keep_prob = 1):
layer_name = 'layer%s'%n_layer
with tf.name_scope(layer_name):
with tf.name_scope("Weights"):
Weights = tf.Variable(tf.random_normal([in_size,out_size]),name = "Weights")
tf.summary.histogram(layer_name+"/weights",Weights)
with tf.name_scope("biases"):
biases = tf.Variable(tf.zeros([1,out_size]) + 0.1,name = "biases")
tf.summary.histogram(layer_name+"/biases",biases)
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.matmul(inputs,Weights) + biases
Wx_plus_b = tf.nn.dropout(Wx_plus_b,keep_prob)
tf.summary.histogram(layer_name+"/Wx_plus_b",Wx_plus_b)
if activation_function == None :
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+"/outputs",outputs)
return outputs
def compute_accuracy(x_data,y_data,prob = 1):
global prediction
y_pre = sess.run(prediction,feed_dict = {xs:x_data,keep_prob:prob})
correct_prediction = tf.equal(tf.arg_max(y_data,1),tf.arg_max(y_pre,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result = sess.run(accuracy,feed_dict = {xs:x_data,ys:y_data,keep_prob:prob})
return result
keep_prob = tf.placeholder(tf.float32)
xs = tf.placeholder(tf.float32,[None,64])
ys = tf.placeholder(tf.float32,[None,10])
l1 = add_layer(xs,64,100,'l1',activation_function=tf.nn.tanh, keep_prob = keep_prob)
l2 = add_layer(l1,100,100,'l2',activation_function=tf.nn.tanh, keep_prob = keep_prob)
prediction = add_layer(l1,100,10,'l3',activation_function = tf.nn.softmax, keep_prob = 1)
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=ys,logits = prediction),name = 'loss')
tf.summary.scalar("loss",loss)
train = tf.train.AdamOptimizer(0.01).minimize(loss)
init = tf.initialize_all_variables()
merged = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init)
train_writer = tf.summary.FileWriter("logs/strain",sess.graph)
test_writer = tf.summary.FileWriter("logs/test",sess.graph)
for i in range(5001):
sess.run(train,feed_dict = {xs:X_train,ys:Y_train,keep_prob:0.5})
if i % 500 == 0:
print("训练%d次的识别率为:%f。"%((i+1),compute_accuracy(X_test,Y_test,prob=0.5)))
train_result = sess.run(merged,feed_dict={xs:X_train,ys:Y_train,keep_prob:0.5})
test_result = sess.run(merged,feed_dict={xs:X_test,ys:Y_test,keep_prob:0.5})
train_writer.add_summary(train_result,i)
test_writer.add_summary(test_result,i)
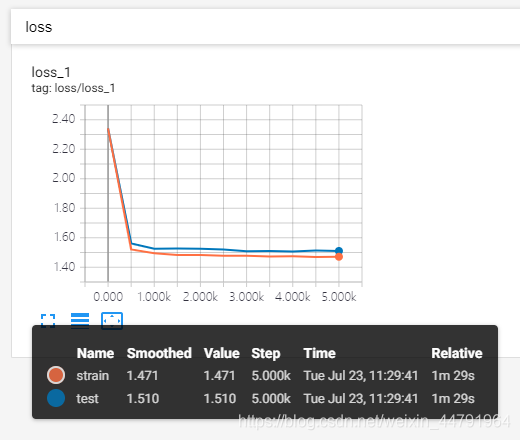
keep_prob = 0.5
训练结果为:
训练1次的识别率为:0.086000。
训练501次的识别率为:0.890000。
训练1001次的识别率为:0.938000。
训练1501次的识别率为:0.952000。
训练2001次的识别率为:0.952000。
训练2501次的识别率为:0.946000。
训练3001次的识别率为:0.940000。
训练3501次的识别率为:0.932000。
训练4001次的识别率为:0.970000。
训练4501次的识别率为:0.952000。
训练5001次的识别率为:0.950000。
这是keep_prob = 0.5时tensorboard中的loss的图像:
keep_prob = 1
训练结果为:
训练1次的识别率为:0.160000。
训练501次的识别率为:0.754000。
训练1001次的识别率为:0.846000。
训练1501次的识别率为:0.854000。
训练2001次的识别率为:0.852000。
训练2501次的识别率为:0.852000。
训练3001次的识别率为:0.860000。
训练3501次的识别率为:0.854000。
训练4001次的识别率为:0.856000。
训练4501次的识别率为:0.852000。
训练5001次的识别率为:0.852000。
这是keep_prob = 1时tensorboard中的loss的图像:
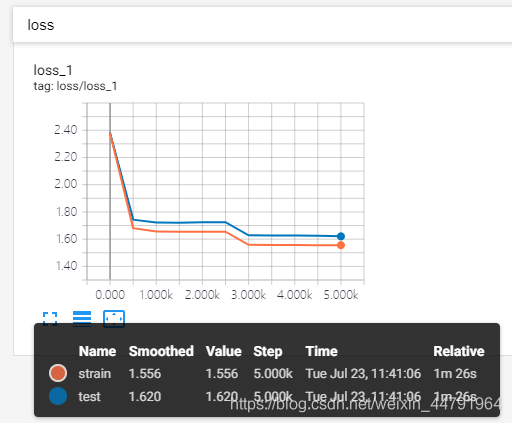
可以明显看出来keep_prob = 0.5的训练集和测试集的曲线更加贴近。
以上就是python人工智能tensorflow函数tf.nn.dropout使用示例的详细内容,更多关于tensorflow函数tf.nn.dropout的资料请关注我们其它相关文章!
相关推荐
-
tensorflow自定义激活函数实例
前言:因为研究工作的需要,要更改激活函数以适应自己的网络模型,但是单纯的函数替换会训练导致不能收敛.这里还有些不清楚为什么,希望有人可以给出解释.查了一些博客,发现了解决之道.下面将解决过程贴出来供大家指正. 1.背景 之前听某位老师提到说tensorflow可以在不给梯度函数的基础上做梯度下降,所以尝试了替换.我的例子时将ReLU改为平方.即原来的激活函数是 现在换成 单纯替换激活函数并不能较好的效果,在我的实验中,迭代到一定批次,准确率就会下降,最终降为10%左右保持稳定.而事实上,这中间最
-
python人工智能tensorflow函数tf.get_collection使用方法
目录 参数数量及其作用 例子 参数数量及其作用 该函数共有两个参数,分别是key和scope. def get_collection(key, scope=None) Wrapper for Graph.get_collection() using the default graph. See tf.Graph.get_collection for more details. Args: key: The key for the collection. For example, the `Gra
-

python人工智能tensorflow函数tensorboard使用方法
目录 tensorboard相关函数及其常用参数设置 1 with tf.name_scope(layer_name): 2 tf.summary.histogram(layer_name+"/biases",biases) 3 tf.summary.scalar(“loss”,loss) 4 tf.summary.merge_all() 5 tf.summary.FileWriter(“logs/”,sess.graph) 6 write.add_summary(result,i)
-
python 深度学习中的4种激活函数
这篇文章用来整理一下入门深度学习过程中接触到的四种激活函数,下面会从公式.代码以及图像三个方面介绍这几种激活函数,首先来明确一下是哪四种: Sigmoid函数 Tahn函数 ReLu函数 SoftMax函数 激活函数的作用 下面图像A是一个线性可分问题,也就是说对于两类点(蓝点和绿点),你通过一条直线就可以实现完全分类. 当然图像A是最理想.也是最简单的一种二分类问题,但是现实中往往存在一些非常复杂的线性不可分问题,比如图像B,你是找不到任何一条直线可以将图像B中蓝点和绿点完全分开的,你必须圈出
-
python人工智能tensorflow常用激活函数Activation Functions
目录 常见的激活函数种类及其图像 1 sigmoid(logsig)函数 2 tanh函数 3 relu函数 4 softplus函数 tensorflow中损失函数的表达 1 sigmoid(logsig)函数 2 tanh函数 3 relu函数 4 softplus函数 激活函数在机器学习中常常用在神经网络隐含层节点与神经网络的输出层节点上,激活函数的作用是赋予神经网络更多的非线性因素,如果不用激励函数,输出都是输入的线性组合,这种情况与最原始的感知机相当,网络的逼近能力相当有限.如果能够引
-
python人工智能tensorflow函数tf.get_variable使用方法
目录 参数数量及其作用 例子 参数数量及其作用 该函数共有十一个参数,常用的有: 名称name 变量规格shape 变量类型dtype 变量初始化方式initializer 所属于的集合collections def get_variable(name, shape=None, dtype=None, initializer=None, regularizer=None, trainable=True, collections=None, caching_device=None, partiti
-
python人工智能tensorflow函数tf.nn.dropout使用方法
目录 前言 tf.nn.dropout函数介绍 例子 代码 keep_prob = 0.5 keep_prob = 1 前言 神经网络在设置的神经网络足够复杂的情况下,可以无限逼近一段非线性连续函数,但是如果神经网络设置的足够复杂,将会导致过拟合(overfitting)的出现,就好像下图这样. 看到这个蓝色曲线,我就知道: 很明显蓝色曲线是overfitting的结果,尽管它很好的拟合了每一个点的位置,但是曲线是歪歪曲曲扭扭捏捏的,这个的曲线不具有良好的鲁棒性,在实际工程实验中,我们更希望得到
-
python人工智能tensorflow函数tf.layers.dense使用方法
目录 参数数量及其作用 部分参数解释: 示例 参数数量及其作用 tf.layers.dense用于添加一个全连接层. 函数如下: tf.layers.dense( inputs, #层的输入 units, #该层的输出维度 activation=None, #激活函数 use_bias=True, kernel_initializer=None, # 卷积核的初始化器 bias_initializer=tf.zeros_initializer(), # 偏置项的初始化器 kernel_regul
-
python人工智能tensorflow函数tf.assign使用方法
目录 参数数量及其作用 例子 参数数量及其作用 该函数共有五个参数,分别是: 被赋值的变量 ref 要分配给变量的值 value. 是否验证形状 validate_shape 是否进行锁定保护 use_locking 名称 name def assign(ref, value, validate_shape=None, use_locking=None, name=None) Update 'ref' by assigning 'value' to it. This operation outp
-
python人工智能tensorflow函数np.random模块使用方法
目录 np.random模块常用的一些方法介绍 例子 numpy.random.rand(d0, d1, …, dn): numpy.random.randn(d0, d1, …, dn): numpy.random.randint(low, high=None, size=None, dtype=‘I’): numpy.random.uniform(low=0.0, high=1.0, size=None): numpy.random.normal(loc=0.0, scale=1.0, si
-
python循环神经网络RNN函数tf.nn.dynamic_rnn使用
目录 学习前言 tf.nn.dynamic_rnn的定义 tf.nn.dynamic_rnn的使用举例 单层实验 多层实验 学习前言 已经完成了RNN网络的构建,但是我们对于RNN网络还有许多疑问,特别是tf.nn.dynamic_rnn函数,其具体的应用方式我们并不熟悉,查询了一下资料,我心里的想法是这样的. tf.nn.dynamic_rnn的定义 tf.nn.dynamic_rnn( cell, inputs, sequence_length=None, initial_state=Non
-
python人工智能tensorflow构建卷积神经网络CNN
目录 简介 隐含层介绍 1.卷积层 2.池化层 3.全连接层 具体实现代码 卷积层.池化层与全连接层实现代码 全部代码 学习神经网络已经有一段时间,从普通的BP神经网络到LSTM长短期记忆网络都有一定的了解,但是从未系统的把整个神经网络的结构记录下来,我相信这些小记录可以帮助我更加深刻的理解神经网络. 简介 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),
-
python人工智能tensorflow构建循环神经网络RNN
目录 学习前言 RNN简介 tensorflow中RNN的相关函数 tf.nn.rnn_cell.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 学习前言 在前一段时间已经完成了卷积神经网络的复习,现在要对循环神经网络的结构进行更深层次的明确. RNN简介 RNN 是当前发展非常火热的神经网络中的一种,它擅长对序列数据进行处理. 什么是序列数据呢?举个例子. 现在假设有四个字,“我” “去” “吃” “饭”.我们可以对它们进行任意的排列组合. “我去吃饭”,表示的就是我