PyTorch实现FedProx联邦学习算法
目录
- I. 前言
- III. FedProx
- 1. 模型定义
- 2. 服务器端
- 3. 客户端更新
- IV. 完整代码
I. 前言
FedProx的原理请见:FedAvg联邦学习FedProx异质网络优化实验总结
联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的。
数据集为某城市十个地区的风电功率,我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型。
III. FedProx
算法伪代码:

1. 模型定义
客户端的模型为一个简单的四层神经网络模型:
# -*- coding:utf-8 -*-
"""
@Time: 2022/03/03 12:23
@Author: KI
@File: model.py
@Motto: Hungry And Humble
"""
from torch import nn
class ANN(nn.Module):
def __init__(self, args, name):
super(ANN, self).__init__()
self.name = name
self.len = 0
self.loss = 0
self.fc1 = nn.Linear(args.input_dim, 20)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
self.dropout = nn.Dropout()
self.fc2 = nn.Linear(20, 20)
self.fc3 = nn.Linear(20, 20)
self.fc4 = nn.Linear(20, 1)
def forward(self, data):
x = self.fc1(data)
x = self.sigmoid(x)
x = self.fc2(x)
x = self.sigmoid(x)
x = self.fc3(x)
x = self.sigmoid(x)
x = self.fc4(x)
x = self.sigmoid(x)
return x
2. 服务器端
服务器端和FedAvg一致,即重复进行客户端采样、参数传达、参数聚合三个步骤:
# -*- coding:utf-8 -*-
"""
@Time: 2022/03/03 12:50
@Author: KI
@File: server.py
@Motto: Hungry And Humble
"""
import copy
import random
import numpy as np
import torch
from model import ANN
from client import train, test
class FedProx:
def __init__(self, args):
self.args = args
self.nn = ANN(args=self.args, name='server').to(args.device)
self.nns = []
for i in range(self.args.K):
temp = copy.deepcopy(self.nn)
temp.name = self.args.clients[i]
self.nns.append(temp)
def server(self):
for t in range(self.args.r):
print('round', t + 1, ':')
# sampling
m = np.max([int(self.args.C * self.args.K), 1])
index = random.sample(range(0, self.args.K), m) # st
# dispatch
self.dispatch(index)
# local updating
self.client_update(index, t)
# aggregation
self.aggregation(index)
return self.nn
def aggregation(self, index):
s = 0
for j in index:
# normal
s += self.nns[j].len
params = {}
for k, v in self.nns[0].named_parameters():
params[k] = torch.zeros_like(v.data)
for j in index:
for k, v in self.nns[j].named_parameters():
params[k] += v.data * (self.nns[j].len / s)
for k, v in self.nn.named_parameters():
v.data = params[k].data.clone()
def dispatch(self, index):
for j in index:
for old_params, new_params in zip(self.nns[j].parameters(), self.nn.parameters()):
old_params.data = new_params.data.clone()
def client_update(self, index, global_round): # update nn
for k in index:
self.nns[k] = train(self.args, self.nns[k], self.nn, global_round)
def global_test(self):
model = self.nn
model.eval()
for client in self.args.clients:
model.name = client
test(self.args, model)
3. 客户端更新
FedProx中客户端需要优化的函数为:

作者在FedAvg损失函数的基础上,引入了一个proximal term,我们可以称之为近端项。引入近端项后,客户端在本地训练后得到的模型参数 w将不会与初始时的服务器参数wt偏离太多。
对应的代码为:
def train(args, model, server, global_round):
model.train()
Dtr, Dte = nn_seq_wind(model.name, args.B)
model.len = len(Dtr)
global_model = copy.deepcopy(server)
if args.weight_decay != 0:
lr = args.lr * pow(args.weight_decay, global_round)
else:
lr = args.lr
if args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=lr,
weight_decay=args.weight_decay)
else:
optimizer = torch.optim.SGD(model.parameters(), lr=lr,
momentum=0.9, weight_decay=args.weight_decay)
print('training...')
loss_function = nn.MSELoss().to(args.device)
loss = 0
for epoch in range(args.E):
for (seq, label) in Dtr:
seq = seq.to(args.device)
label = label.to(args.device)
y_pred = model(seq)
optimizer.zero_grad()
# compute proximal_term
proximal_term = 0.0
for w, w_t in zip(model.parameters(), global_model.parameters()):
proximal_term += (w - w_t).norm(2)
loss = loss_function(y_pred, label) + (args.mu / 2) * proximal_term
loss.backward()
optimizer.step()
print('epoch', epoch, ':', loss.item())
return model
我们在原有MSE损失函数的基础上加上了一个近端项:
for w, w_t in zip(model.parameters(), global_model.parameters()):
proximal_term += (w - w_t).norm(2)
然后再反向传播求梯度,然后优化器step更新参数。
原始论文中还提出了一个不精确解的概念:
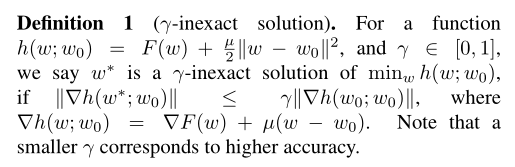

不过值得注意的是,我并没有在原始论文的实验部分找到如何选择 γ \gamma γ的说明。查了一下资料后发现是涉及到了近端梯度下降的知识,本文代码并没有考虑不精确解,后期可能会补上。
IV. 完整代码
链接:https://pan.baidu.com/s/1hj2EOcqIUmM-C6R1cyjE5Q
提取码:fghp
项目结构:

其中:
- server.py为服务器端操作。
- client.py为客户端操作。
- data_process.py为数据处理部分。
- model.py为模型定义文件。
- args.py为参数定义文件。
- main.py为主文件,如想要运行此项目可直接运行:
python main.py
以上就是PyTorch实现FedProx的联邦学习算法的详细内容,更多关于PyTorch实现FedProx算法的资料请关注我们其它相关文章!
相关推荐
-

FedAvg联邦学习FedProx异质网络优化实验总结
目录 前言 I. FedAvg II. FedProx III. 实验 IV. 总结 前言 题目: Federated Optimization for Heterogeneous Networks 会议: Conference on Machine Learning and Systems 2020 论文地址:Federated Optimization for Heterogeneous Networks FedAvg对设备异质性和数据异质性没有太好的解决办法,FedProx在FedAvg的
-
pytorch 膨胀算法实现大眼效果
目录 算法思路: 应用场景: 代码实现: 实验效果: 论文:Interactive Image Warping(1993年Andreas Gustafsson) 算法思路: 以眼睛中心为中心点,对眼睛区域向外放大,就实现了大眼的效果.大眼的基本公式如下, 假设眼睛中心点为O(x,y),大眼区域半径为Radius,当前点位为A(x1,y1),对其进行改进,加入大眼程度控制变量Intensity,其中Intensity的取值范围为0-100. 其中,dis表示AO的欧式距离,k表示缩放比例因子,
-
pytorch 液态算法实现瘦脸效果
论文:Interactive Image Warping(1993年Andreas Gustafsson) 算法思路: 假设当前点为(x,y),手动指定变形区域的中心点为C(cx,cy),变形区域半径为r,手动调整变形终点(从中心点到某个位置M)为M(mx,my),变形程度为strength,当前点对应变形后的目标位置为U.变形规律如下, 圆内所有像素均沿着变形向量的方向发生偏移 距离圆心越近,变形程度越大 距离圆周越近,变形程度越小,当像素点位于圆周时,该像素不变形 圆外像素不发生偏移 其中,
-
Python强化练习之PyTorch opp算法实现月球登陆器
目录 概述 强化学习算法种类 PPO 算法 Actor-Critic 算法 Gym LunarLander-v2 启动登陆器 PPO 算法实现月球登录器 PPO main 输出结果 概述 从今天开始我们会开启一个新的篇章, 带领大家来一起学习 (卷进) 强化学习 (Reinforcement Learning). 强化学习基于环境, 分析数据采取行动, 从而最大化未来收益. 强化学习算法种类 On-policy vs Off-policy: On-policy: 训练数据由当前 agent 不断
-
PyTorch实现联邦学习的基本算法FedAvg
目录 I. 前言 II. 数据介绍 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 IV. 代码实现 1. 初始化 2. 服务器端 3. 客户端 4. 测试 V. 实验及结果 VI. 源码及数据 I. 前言 在之前的一篇博客联邦学习基本算法FedAvg的代码实现中利用numpy手搭神经网络实现了FedAvg,手搭的神经网络效果已经很好了,不过这还是属于自己造轮子,建议优先使用PyTorch来实现. II. 数据介绍 联邦学习中存在多个客户端,每个客户端都有自己的数据集
-
PyTorch实现FedProx联邦学习算法
目录 I. 前言 III. FedProx 1. 模型定义 2. 服务器端 3. 客户端更新 IV. 完整代码 I. 前言 FedProx的原理请见:FedAvg联邦学习FedProx异质网络优化实验总结 联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的. 数据集为某城市十个地区的风电功率,我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型. III. FedProx 算法伪代码: 1. 模型定义 客户端的模
-
联邦学习神经网络FedAvg算法实现
目录 I. 前言 II. 数据介绍 1. 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 4. 代码实现 4.1 初始化 4.2 服务器端 4.3 客户端 4.4 测试 IV. 实验及结果 V. 源码及数据 I. 前言 联邦学习(Federated Learning) 是人工智能的一个新的分支,这项技术是谷歌2016年于论文 Communication-Efficient Learning of Deep Networks from Decentralized Dat
-
利用Pytorch实现简单的线性回归算法
最近听了张江老师的深度学习课程,用Pytorch实现神经网络预测,之前做Titanic生存率预测的时候稍微了解过Tensorflow,听说Tensorflow能做的Pyorch都可以做,而且更方便快捷,自己尝试了一下代码的逻辑确实比较简单. Pytorch涉及的基本数据类型是tensor(张量)和Autograd(自动微分变量),对于这些概念我也是一知半解,tensor和向量,矩阵等概念都有交叉的部分,下次有时间好好补一下数学的基础知识,不过现阶段的任务主要是应用,学习掌握思维和方法即可,就不再
-
联邦学习论文解读分散数据的深层网络通信
目录 前言 Abstract Introduction Federated Learning Privacy Federated Optimization The FederatedAveraging Algorithm Experimental Results Increasing parallelism Increasing computation per client Can we over-optimize on the client datasets? Conclusions and
-
联邦学习FedAvg中模型聚合过程的理解分析
目录 问题 聚合 1. 聚合所有客户端 2. 仅聚合被选中的客户端 3. 选择 问题 联邦学习原始论文中给出的FedAvg的算法框架为: 参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率. 首先是服务器执行以下步骤: 对每一个本地客户端来说,要做的就是更新本地参数,具体来讲: 把自己的数据集按照参数B分成若干个块,每一块大小都为B. 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w . 更新
-
知识蒸馏联邦学习的个性化技术综述
目录 前言 摘要 I. 引言 II. 个性化需求 III. 方法 A. 添加用户上下文 B. 迁移学习 C. 多任务学习 D. 元学习 E. 知识蒸馏 F. 基础+个性化层 G. 全局模型和本地模型混合 IV. 总结 前言 题目: Survey of Personalization Techniques for FederatedLearning 会议: 2020 Fourth World Conference on Smart Trends in Systems, Security and S
-
如何用JavaScript学习算法复杂度
概述 在本文中,我们将探讨 "二次方" 和 "n log(n)" 等术语在算法中的含义. 在后面的例子中,我将引用这两个数组,一个包含 5 个元素,另一个包含 50 个元素.我还会用到JavaScript中方便的performance API来衡量执行时间的差异. const smArr = [5, 3, 2, 35, 2]; const bigArr = [5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3,
-
python人工智能深度学习算法优化
目录 1.SGD 2.SGDM 3.Adam 4.Adagrad 5.RMSProp 6.NAG 1.SGD 随机梯度下降 随机梯度下降和其他的梯度下降主要区别,在于SGD每次只使用一个数据样本,去计算损失函数,求梯度,更新参数.这种方法的计算速度快,但是下降的速度慢,可能会在最低处两边震荡,停留在局部最优. 2.SGDM SGM with Momentum:动量梯度下降 动量梯度下降,在进行参数更新之前,会对之前的梯度信息,进行指数加权平均,然后使用加权平均之后的梯度,来代替原梯度,进行参数的