C语言循环链表的原理与使用操作
目录
- 一.引入
- 二.循环链表的定义
- 三.单链表与循环链表对比
- 3.1图示对比
- 3.2代码对比
- 四.循环链表的操作
- 4.1循环链表的初始化
- 4.2循环链表的建立
- 4.2.1头插法建立循环链表
- 4.2.2尾插法建立循环链表
- 4.3循环链表的插入操作
- 4.4循环链表的删除操作
- 4.5循环链表的销毁
- 4.5.1无限头删
- 4.5.2两个指针变量
- 4.6其他操作
- 五.总结
- 六.全部代码
一.引入
在单链表中我们是把结点遍历一遍后就结束了,为了使表处理更加方便灵活,我们希望通过任意一个结点出发都可以找到链表中的其它结点,因此我们引入了循环链表。
二.循环链表的定义
将单链表中终端结点的指针端由空指针改为头结点,就使整个单链表形成了一个环,这种头尾相接的单链表称为循环链表。
简单理解就是形成一个闭合的环,在环内寻找自己需要的结点。
三.单链表与循环链表对比
3.1图示对比
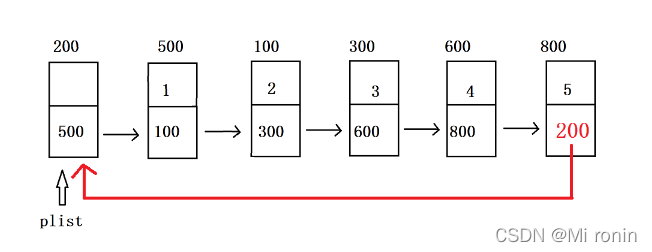
单链表:
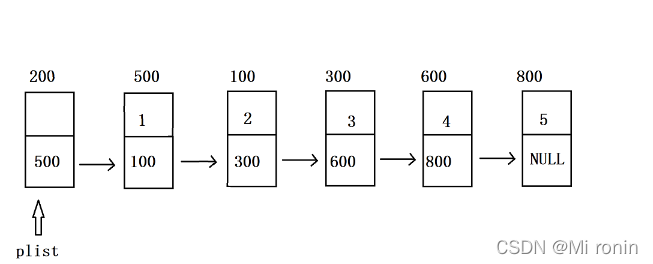
循环链表:
3.2代码对比
单链表:
typedef struct Node{ //定义单链表结点类型
int data; //数据域,可以是别的各种数据类型
struct Node *next; //指针域
}LNode, *LinkList;
循环链表:
typedef int ELEMTYPE;
typedef struct Clist
{
ELEMTYPE data; //数据域 存放数据
struct Clist* next;
//指针域存放下一个节点的地址(尾结点的next保存头结点的地址)
}Clist, * PClist;
四.循环链表的操作
循环链表是单链表中扩展出来的结构,所以有很多的操作是和单链表相同的,如求长度,查找元素,获取一个元素,这里我们对循环链表进行初始化,创建,插入,删除,销毁的一系列操作。
4.1循环链表的初始化
单链表和循环链表初始化对比如下:
| 单链表 | 循环链表 |
|---|---|
| 数据域不处理 | 数据域不处理 |
| next域赋值为NULL | next域赋值为头结点自身的地址 |
代码如下:
void InitClist(struct Clist* plist)
{
//assert
//plist->data; // 数据域不处理
plist->next = plist;
}
4.2循环链表的建立
循环链表的建立是基于单链表所以也有头插和尾插两种方式。
4.2.1头插法建立循环链表
头插法建立循环链表的主要是这两行代码:
pnewnode->next=plist->next;
plist->next=pnewnode;
这里我们需要思考一下当链表为空时是否适用:这里明确告诉大家不管是否是空链表,这两行代码均可以使用,下面给大家用示意图表示一下;
不是空链:

是空链:
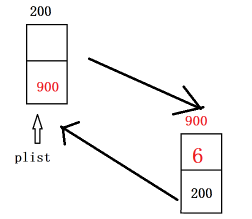
代码如下:
bool Insert_head(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置 (头插 不用找)
//3.插入
pnewnode->next = plist->next;
plist->next = pnewnode;
return true;
}
4.2.2尾插法建立循环链表
尾插法建立循环链表主要代码如下:
for(p=plist;p->next!=plist;p=p->next);
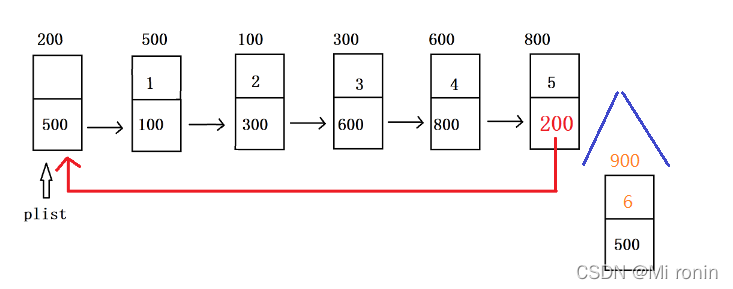
代码如下:
bool Insert_tail(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (p; p->next != plist; p = p->next);
//此时 for循环执行结束 p指向尾结点
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
4.3循环链表的插入操作
与单向链表的插入不同,循环单链表插入时只能往表头节点的后面插入,由初始结构可知,想完成插入操作,必须先找到要插入位置的前一个节点,然后修改相应指针即可完成操作。
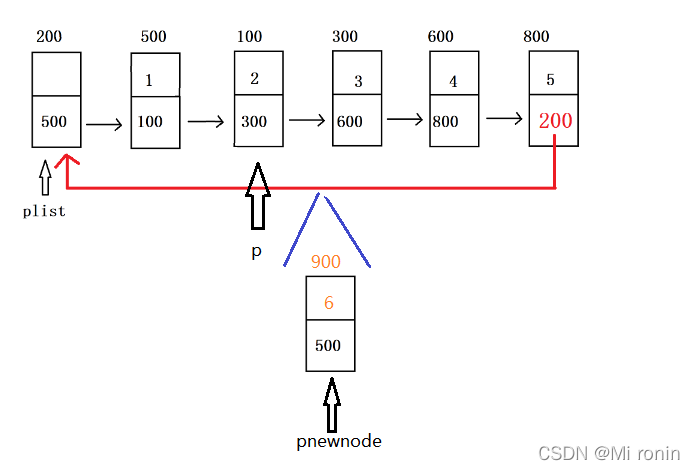
bool Insert_pos(PClist plist, int pos, ELEMTYPE val)
{
assert(plist != NULL);
assert(pos >= 0 && pos <= Get_length(plist));
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
//此时 for循环执行结束 p指向待插入的合适位置
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
4.4循环链表的删除操作
循环链表的删除操作相当于单链表的删除操作,主要分为以下三个步骤:
- 指针p指向待删除的结点;
- 指针q指向待删除结点的前一个结点;
- 跨越指向。
void Delete(list **pNode,int place) //删除操作
{
list *temp,*target;
int i;
temp=*pNode;
if(temp==NULL) //首先判断链表是否为空
{
printf("这是一个空指针 无法删除\n");
return;
}
if(place==1) //如果删除的是头节点
{ //应当特殊处理,找到尾节点,使尾节点的next指向头节点的下一个节点
// rear->next=(*head)->next;然后让新节点作为头节点,释放原来的头节点
for(target=*pNode;target->next!=*pNode;target=target->next);
temp=*pNode;
*pNode=(*pNode)->next;
target->next=*pNode;
free(temp);
}
else //删除其他节点
{ //首先找出尾节点
for(i=1,target=*pNode;target->next!=*pNode&&i!=place-1;target=target->next,i++);
if(target->next==*pNode) //判断要删除的位置是否大于链表长度,若大于链表长度,
//特殊处理直接删除尾节点
{
//找出尾节的前一个节点
for(target=*pNode;target->next->next!=*pNode;target=target->next);
temp=target->next; // 尾节点的前一个节点直接指向头节点 释放原来的尾节点
target->next=*pNode;
printf("数字太大删除尾巴\n");
free(temp);
}
else
{
temp=target->next;// 删除普通节点 找到要删除节点的前一个节点target,
//使target指向要删除节点的下一个节点 转存删除节点地址
target->next=temp->next; // 然后释放这个节点
free(temp);
}
}
}
4.5循环链表的销毁
循环链表这里有两种销毁方式:
4.5.1无限头删
void Destroy1(PClist plist)
{
//assert
while (plist->next != plist)
{
struct Clist* p = plist->next;
plist->next = p->next;
free(p);
}
plist->next = plist;
}
4.5.2两个指针变量
void Destroy2(PClist plist)
{
//assert
struct Clist* p = plist->next;
struct Clist* q = NULL;
plist->next = plist;
while (p != plist)
{
q = p->next;
free(p);
p = q;
}
}
4.6其他操作
循环链表还有查找值,判空,求链表长度,清空等一系列操作,这些操作与单链表那的操作基本相同,这里不进行详细赘述,在后面的完整代码中会写出来。
五.总结
循环链表相对于单链表来说会稍微复杂一点,主要思想还是和单链表差不多的,只不过是将链表的首位进行相连,但是正是因为首尾的相连,便于我们通过任意一个结点出发都可以找到链表中的其它结点。
六.全部代码
#include <stdio.h>
#include <malloc.h>
#include <assert.h>
//循环链表里边很少出现NULL, nullptr
//初始化
void InitClist(struct Clist* plist)
{
//assert
//plist->data; // 数据域不处理
plist->next = plist;
}
//头插
bool Insert_head(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置 (头插 不用找)
//3.插入
pnewnode->next = plist->next;
plist->next = pnewnode;
return true;
}
//尾插
bool Insert_tail(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (p; p->next != plist; p = p->next);
//此时 for循环执行结束 p指向尾结点
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//按位置插
bool Insert_pos(PClist plist, int pos, ELEMTYPE val)
{
assert(plist != NULL);
assert(pos >= 0 && pos <= Get_length(plist));
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
//此时 for循环执行结束 p指向待插入的合适位置
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//头删
bool Del_head(PClist plist)
{
//assert
if (IsEmpty(plist))//不空 则至少存在一个有效值
{
return false;
}
//1.指针p指向待删除节点
struct Clist* p = plist->next;
//2.指针q指向待删除节点的前一个节点
//q 就是 头结点 这里就不再额外处理
//3.跨越指向
plist->next = p->next;
free(p);
return true;
}
//尾删
bool Del_tail(PClist plist)
{
//assert
if (IsEmpty(plist))//不空 则至少存在一个有效值
{
return false;
}
//1.指针p指向待删除节点(尾删的话,这里指向尾结点)
struct Clist* p = plist;
for (p; p->next != plist; p = p->next);
//此时 for指向结束 代表着p指向尾结点
//2.指针q指向倒数第二个节点
struct Clist* q = plist;
for (q; q->next != p; q = q->next);
//此时 for指向结束 代表着q指向p的上一个节点
//3.跨越指向
q->next = p->next;
free(p);
return true;
}
//按位置删
bool Del_pos(PClist plist, int pos)
{
assert(plist != NULL);
assert(pos >= 0 && pos < Get_length(plist));
if (IsEmpty(plist))
{
return false;
}
//1.指针p指向待删除节点
//2.指针q指向待删除节点的上一个节点
//这里采用第二种方案找pq,先找q再找p
struct Clist* q = plist;
for (int i = 0; i < pos; i++)
{
q = q->next;
}
struct Clist* p = q->next;
//3.跨越指向
q->next = p->next;
free(p);
return true;
}
//按值删除
bool Del_val(PClist plist, ELEMTYPE val)
{
//assert
struct Clist* p = Search(plist, val);
if (p == NULL)
{
return false;
}
struct Clist* q = plist;
for (q; q->next != p; q = q->next);
q->next = p->next;
free(p);
return true;
}
//查找(如果查找到,需要返回找到的这个节点的地址)
struct Clist* Search(struct Clist* plist, ELEMTYPE val)
{
//assert
for (struct Clist* p = plist->next; p != plist; p = p->next)
{
if (p->data == val)
{
return p;
}
}
return NULL;
}
//判空
bool IsEmpty(PClist plist)
{
//assert
return plist->next == plist;
}
//判满(循环链表不需要这个操作)
//获取长度
/*指针p从头结点的下一个节点开始向后跑,如果p再次遇到了头结点,
证明p走了一圈回来了,这是有效节点肯定已经遍历结束*/
int Get_length(PClist plist)
{
//不带前驱的for循环 跑一遍就好
int count = 0;
for (struct Clist* p = plist->next; p != plist; p = p->next)
{
count++;
}
return count;
}
//清空
void Clear(PClist plist)
{
//assert
Destroy1(plist);
}
//销毁1(无限头删)
void Destroy1(PClist plist)
{
//assert
while (plist->next != plist)
{
struct Clist* p = plist->next;
plist->next = p->next;
free(p);
}
plist->next = plist;
}
//销毁2(要用到两个指针变量)
void Destroy2(PClist plist)
{
//assert
struct Clist* p = plist->next;
struct Clist* q = NULL;
plist->next = plist;
while (p != plist)
{
q = p->next;
free(p);
p = q;
}
}
//打印
void Show(struct Clist* plist)
{
//assert
for (struct Clist* p = plist->next; p != plist; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}
到此这篇关于C语言循环链表的原理与使用操作的文章就介绍到这了,更多相关C语言循环链表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言详解如何实现带头双向循环链表
目录 创建链表存储结构 创建结点 链表的初始化 双向链表的打印 双向链表尾插 双向链表尾删 双向链表头插 双向链表头删 双向链表查找 双向链表pos前插入结点 双向链表删除pos位置的结点 双向链表的销毁 顺序表和链表的区别 2022042311415360.{C}{C}png" /> 创建链表存储结构 我们需要创建一个结构体来存储一个链表结点的相关信息. typedef int ListDataType;//将ListDataType先定义为int类型,根据需要可以改为不同的类型 //创
-
C语言算法学习之双向链表详解
目录 一.练习题目 二.算法思路 1.设计浏览器历史记录 2.扁平化多级双向链表 3.展平多级双向链表 4.二叉搜索树与双向链表 一.练习题目 题目链接 难度 1472. 设计浏览器历史记录 ★★★☆☆ 430. 扁平化多级双向链表 ★★★☆☆ 剑指 Offer II 028. 展平多级双向链表 ★★★☆☆ 剑指 Offer 36. 二叉搜索树与双向链表 ★★★★☆ 二.算法思路 1.设计浏览器历史记录 1.这是一个模拟题: 2.初始化生成一个头结点,记录一个当前结点: 3.向前 和 向后 是两
-

C语言实题讲解快速掌握单链表上
目录 1.移除链表元素 2.反转链表 3.链表的中间节点 4.链表中倒数第k个节点 5.合并两个有序链表 6.链表分割 1.移除链表元素 链接直达: 移除链表元素 题目: 思路: 此题要综合考虑多种情况,常规情况就如同示例1,有多个节点,并且val不连续,但是非常规呢?当val连续呢?当头部就是val呢?所以要分类讨论 常规情况: 需要定义两个指针prev和cur,cur指向第一个数据,prev指向cur的前一个.依次遍历cur指向的数据是否为val,若是,则把prev的下一个节点指向cur的下
-
C语言双向链表的原理与使用操作
目录 一.引入 二.双向链表的定义 三.双向链表与单链表对比 3.1图示对比 3.2代码对比 四.双向链表的操作 4.1双向链表的创建 4.2双向链表的插入 4.3双向链表的删除 4.4双向链表的销毁 五.总结 六.全部代码 一.引入 我们在单链表中,有了next指针,这个指针是用来指向下一个节点的,如果我们需要查找下一个结点的时间复杂度为o(1),如果我们需要查找上一个节点的时候,那么时间复杂度就变为o(n)了,需要从头进行遍历一遍:这时我们就会想:如果可以向前查找就方便了许多,因此我们引入了
-
C语言深入讲解链表的使用
目录 一.链表的概念 二.链表的分类 1. 单向或者双向链表 2. 带头或者不带头(是否有自带哨兵位头结点) 3. 循环或者非循环链表 4. 无头单向非循环链表和带头双向循环链表 3.链表的实现(代码和注释) 4.链表oj题(小试牛刀) 总结 现实生活中的火车就像一个完整的链表,现在我们来深入理解一下链表这个数据结构. 一.链表的概念 概念:链表是一种物理存储结构上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链 接次序实现的 . 注: 1.从上图中可看出,链式结构在逻辑上是连续
-
C语言超详细i讲解双向链表
目录 一.双向链表的概念 二.双向链表的实现 三.链表与顺序表的差别 四.链表oj 总结 一.双向链表的概念 1.概念:概念:双向链表是每个结点除后继指针外还有⼀个前驱指针.双向链表也有带头结点结构和不带头结点结构两种,带头结点的双向链表更为常用:另外,双向链表也可以有循环和非循环两种结构,循环结构的双向链表更为常用. 二.双向链表的实现 头文件List.h #pragma once #include<stdio.h> #include<assert.h> #include<
-
C语言实题讲解快速掌握单链表下
目录 1.移除链表元素 2.反转链表 3.链表的中间节点 4.链表中倒数第k个节点 5.合并两个有序链表 6.链表分割 1.移除链表元素 链接直达: 移除链表元素 题目: 思路: 此题要综合考虑多种情况,常规情况就如同示例1,有多个节点,并且val不连续,但是非常规呢?当val连续呢?当头部就是val呢?所以要分类讨论 常规情况: 需要定义两个指针prev和cur,cur指向第一个数据,prev指向cur的前一个.依次遍历cur指向的数据是否为val,若是,则把prev的下一个节点指向cur的下
-
C语言一篇精通链表的各种操作
目录 前言 一.链表的介绍 1.什么是链表 2.链表的分类 2.1.根据方向 2.2.头结点 2.3.循环/非循环 二.链表的实现 1.结构体 2.开辟结点 3.打印 4.尾插 5.头插 6.测试 7.头删/尾删 8.查找 9.在pos的前面插入x 10.删除pos位置的值 三.主函数Test 结束语 前言 关于线性表的一些相关介绍,大家可以看看我们之前写的点我-链表 点我-顺序表,里面有一些相关的知识介绍,都是比较基础的,一些比较常见的操作里面也有具体的介绍与实现到,然后呢,今天我们学习的是链
-
C语言实现单链表基本操作方法
目录 存储结构 基本功能 头插法创建单链表 尾插法创建单链表 获取指定位置的元素 在指定位置插入元素 删除指定位置的元素 获取单链表的长度 合并两个非递减的单链表 晴链表 遍历打印单链表 附上完整代码 存储结构 typedef int dataType://爱护据类型 typedef struct Node { DataType data; // 结点数据 struct Node *next; // 指向下一个结点的指针 } Node, *LinkList; 基本功能 头插法创建单链表void
-
C语言循环链表的原理与使用操作
目录 一.引入 二.循环链表的定义 三.单链表与循环链表对比 3.1图示对比 3.2代码对比 四.循环链表的操作 4.1循环链表的初始化 4.2循环链表的建立 4.2.1头插法建立循环链表 4.2.2尾插法建立循环链表 4.3循环链表的插入操作 4.4循环链表的删除操作 4.5循环链表的销毁 4.5.1无限头删 4.5.2两个指针变量 4.6其他操作 五.总结 六.全部代码 一.引入 在单链表中我们是把结点遍历一遍后就结束了,为了使表处理更加方便灵活,我们希望通过任意一个结点出发都可以找到链表中
-
C语言SQLite3事务和锁的操作实例
本文实例讲述了C语言SQLite3事务和锁的操作.分享给大家供大家参考,具体如下: #include <stdio.h> #include <sqlite3.h> static int lib_get_value_callback(void *buf, int argc, char *argv[], char *column_name[]) { printf("argc:%d,%s argv[0]:%s,%s argv[1]:%s\n",argc,column_
-
用C语言实现单链表的各种操作(二)
上一篇文章<用C语言实现单链表的各种操作(一)>主要是单链表的一些最基本的操作,下面,主要是一些其他的典型的算法和测试程序. 复制代码 代码如下: /* 对单链表进行排序处理*/struct LNode *sort(struct LNode *head){ LinkList *p; int n,i,j; int temp; n = ListLength(head); if(head == NULL || head->next == NULL) return head;
-
vue中的双向数据绑定原理与常见操作技巧详解
本文实例讲述了vue中的双向数据绑定原理与常见操作技巧.分享给大家供大家参考,具体如下: 什么是双向数据绑定? vue是一个mvvm框架,即数据双向绑定,即当数据发生变化的时候,视图也就发生变化,当视图发生变化的时候,数据也会跟着同步变化.这也是算是vue的精髓之处了.值得注意的是,我们所说的数据双向绑定,一定是对于UI控件来说的,非UI控件不会涉及到数据双向绑定.单向数据绑定是使用状态管理工具的前提,如果我们使用vuex,那么数据流也是单向的,这时就会和双向数据绑定有冲突,我们可以这么解决.
-
C语言超详细讲解文件的操作
目录 一.为什么使用文件 二.什么是文件 1.程序文件 2.数据文件 3.文件名 三.文件指针 四.文件的打开和关闭 五.文件的顺序读写 六.文件的随机读写 fseek ftell rewind 七.文件结束判定 一.为什么使用文件 当我们写一些项目的时候,我们应该要把写的数据存储起来.只有我们自己选择删除数据的时候,数据才不复存在.这就涉及到了数据的持久化的问题,为我们一般数据持久化的方法有,把数据存在磁盘文件.存放到数据库等方式.使用文件我们可以将数据直接存放在电脑的硬盘上,做到了数据的持久
-
C语言实现顺序表的全操作详解
目录 线性表 顺序表 顺序表接口实现 1.顺序表初始化 2.顺序表空间增容 3.顺序表打印 4.尾插数据 5.尾删数据 6.头插数据 7.头删数据 8.在pos下标处插入数据 9.删除pos下标处数据 10.数据查找 11.顺序表摧毁 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列.线性表是一种在实际中广泛使用的数据结构,常见的线性表有:顺序表.链表.栈.队列.字符串等. 线性表在逻辑上是线性结构,也就是连续的一条直线.但在物理结构上并不一定是连续的,线性表在物理
-
C语言全面讲解顺序表使用操作
目录 一.顺序表的结构定义 二.顺序表的结构操作 1.初始化 2.插入操作 3.删除操作 4.扩容操作 5.释放操作 6.输出 三.示例 编程环境为 ubuntu 18.04. 顺序表需要连续一片存储空间,存储任意类型的元素,这里以存储 int 类型数据为例. 一.顺序表的结构定义 size 为容量,length 为当前已知数据表元素的个数 typedef struct Vector{ int *data; //该顺序表这片连续空间的首地址 int size, length; } Vec; 二.
-
图文详解go语言反射实现原理
Go反射的实现和 interface 和 unsafe.Pointer 密切相关.如果对golang的 interface 底层实现还没有理解,可以去看我之前的文章: Go语言interface底层实现 , unsafe.Pointer 会在后续的文章中做介绍. (本文目前使用的Go环境是Go 1.12.9) interface回顾 首先我们简单的回顾一下interface的结构,总体上是: 细分下来分为有函数的 iface 和无函数的 eface (就是 interface{} ); 无函数的
-
C语言数据结构详细解析二叉树的操作
目录 二叉树分类 二叉树性质 性质的使用 二叉树的遍历 前序遍历 中序遍历 后序遍历 层序遍历 求二叉树的节点数 求二叉树叶子结点个数 求二叉树的最大深度 二叉树的销毁 二叉树分类 满二叉树 除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树.也可以理解为每一层的结点数都达到最大值的二叉树. 完全二叉树 一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下.从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为