python实现A*寻路算法
A* 算法简介
A* 算法需要维护两个数据结构:OPEN 集和 CLOSED 集。OPEN 集包含所有已搜索到的待检测节点。初始状态,OPEN集仅包含一个元素:开始节点。CLOSED集包含已检测的节点。初始状态,CLOSED集为空。每个节点还包含一个指向父节点的指针,以确定追踪关系。
A* 算法会给每个搜索到的节点计算一个G+H 的和值F:
- F = G + H
- G:是从开始节点到当前节点的移动量。假设开始节点到相邻节点的移动量为1,该值会随着离开始点越来越远而增大。
- H:是从当前节点到目标节点的移动量估算值。
- 如果允许向4邻域的移动,使用曼哈顿距离。
- 如果允许向8邻域的移动,使用对角线距离。
算法有一个主循环,重复下面步骤直到到达目标节点:
1 每次从OPEN集中取一个最优节点n(即F值最小的节点)来检测。
2 将节点n从OPEN集中移除,然后添加到CLOSED集中。
3 如果n是目标节点,那么算法结束。
4 否则尝试添加节点n的所有邻节点n'。
- 邻节点在CLOSED集中,表示它已被检测过,则无需再添加。
- 邻节点在OPEN集中:
- 如果重新计算的G值比邻节点保存的G值更小,则需要更新这个邻节点的G值和F值,以及父节点;
- 否则不做操作
- 否则将该邻节点加入OPEN集,设置其父节点为n,并设置它的G值和F值。
有一点需要注意,如果开始节点到目标节点实际是不连通的,即无法从开始节点移动到目标节点,那算法在第1步判断获取到的节点n为空,就会退出
关键代码介绍
保存基本信息的地图类
地图类用于随机生成一个供寻路算法工作的基础地图信息
先创建一个map类, 初始化参数设置地图的长度和宽度,并设置保存地图信息的二维数据map的值为0, 值为0表示能移动到该节点。
class Map(): def __init__(self, width, height): self.width = width self.height = height self.map = [[0 for x in range(self.width)] for y in range(self.height)]
在map类中添加一个创建不能通过节点的函数,节点值为1表示不能移动到该节点。
def createBlock(self, block_num): for i in range(block_num): x, y = (randint(0, self.width-1), randint(0, self.height-1)) self.map[y][x] = 1
在map类中添加一个显示地图的函数,可以看到,这边只是简单的打印出所有节点的值,值为0或1的意思上面已经说明,在后面显示寻路算法结果时,会使用到值2,表示一条从开始节点到目标节点的路径。
def showMap(self):
print("+" * (3 * self.width + 2))
for row in self.map:
s = '+'
for entry in row:
s += ' ' + str(entry) + ' '
s += '+'
print(s)
print("+" * (3 * self.width + 2))
添加一个随机获取可移动节点的函数
def generatePos(self, rangeX, rangeY): x, y = (randint(rangeX[0], rangeX[1]), randint(rangeY[0], rangeY[1])) while self.map[y][x] == 1: x, y = (randint(rangeX[0], rangeX[1]), randint(rangeY[0], rangeY[1])) return (x , y)
搜索到的节点类
每一个搜索到将到添加到OPEN集的节点,都会创建一个下面的节点类,保存有entry的位置信息(x,y),计算得到的G值和F值,和该节点的父节点(pre_entry)。
class SearchEntry(): def __init__(self, x, y, g_cost, f_cost=0, pre_entry=None): self.x = x self.y = y # cost move form start entry to this entry self.g_cost = g_cost self.f_cost = f_cost self.pre_entry = pre_entry def getPos(self): return (self.x, self.y)
算法主函数介绍
下面就是上面算法主循环介绍的代码实现,OPEN集和CLOSED集的数据结构使用了字典,在一般情况下,查找,添加和删除节点的时间复杂度为O(1), 遍历的时间复杂度为O(n), n为字典中对象数目。
def AStarSearch(map, source, dest):
...
openlist = {}
closedlist = {}
location = SearchEntry(source[0], source[1], 0.0)
dest = SearchEntry(dest[0], dest[1], 0.0)
openlist[source] = location
while True:
location = getFastPosition(openlist)
if location is None:
# not found valid path
print("can't find valid path")
break;
if location.x == dest.x and location.y == dest.y:
break
closedlist[location.getPos()] = location
openlist.pop(location.getPos())
addAdjacentPositions(map, location, dest, openlist, closedlist)
#mark the found path at the map
while location is not None:
map.map[location.y][location.x] = 2
location = location.pre_entry
我们按照算法主循环的实现来一个个讲解用到的函数。
下面函数就是从OPEN集中获取一个F值最小的节点,如果OPEN集会空,则返回None。
# find a least cost position in openlist, return None if openlist is empty def getFastPosition(openlist): fast = None for entry in openlist.values(): if fast is None: fast = entry elif fast.f_cost > entry.f_cost: fast = entry return fast
addAdjacentPositions 函数对应算法主函数循环介绍中的尝试添加节点n的所有邻节点n'。
# add available adjacent positions def addAdjacentPositions(map, location, dest, openlist, closedlist): poslist = getPositions(map, location) for pos in poslist: # if position is already in closedlist, do nothing if isInList(closedlist, pos) is None: findEntry = isInList(openlist, pos) h_cost = calHeuristic(pos, dest) g_cost = location.g_cost + getMoveCost(location, pos) if findEntry is None : # if position is not in openlist, add it to openlist openlist[pos] = SearchEntry(pos[0], pos[1], g_cost, g_cost+h_cost, location) elif findEntry.g_cost > g_cost: # if position is in openlist and cost is larger than current one, # then update cost and previous position findEntry.g_cost = g_cost findEntry.f_cost = g_cost + h_cost findEntry.pre_entry = location
getPositions 函数获取到所有能够移动的节点,这里提供了2种移动的方式:
- 允许上,下,左,右 4邻域的移动
- 允许上,下,左,右,左上,右上,左下,右下 8邻域的移动
def getNewPosition(map, locatioin, offset): x,y = (location.x + offset[0], location.y + offset[1]) if x < 0 or x >= map.width or y < 0 or y >= map.height or map.map[y][x] == 1: return None return (x, y) def getPositions(map, location): # use four ways or eight ways to move offsets = [(-1,0), (0, -1), (1, 0), (0, 1)] #offsets = [(-1,0), (0, -1), (1, 0), (0, 1), (-1,-1), (1, -1), (-1, 1), (1, 1)] poslist = [] for offset in offsets: pos = getNewPosition(map, location, offset) if pos is not None: poslist.append(pos) return poslist
isInList 函数判断节点是否在OPEN集 或CLOSED集中
# check if the position is in list def isInList(list, pos): if pos in list: return list[pos] return None
calHeuristic 函数简单得使用了曼哈顿距离,这个后续可以进行优化。
getMoveCost 函数根据是否是斜向移动来计算消耗(斜向就是2的开根号,约等于1.4)
# imporve the heuristic distance more precisely in future def calHeuristic(pos, dest): return abs(dest.x - pos[0]) + abs(dest.y - pos[1]) def getMoveCost(location, pos): if location.x != pos[0] and location.y != pos[1]: return 1.4 else: return 1
代码的初始化
可以调整地图的长度,宽度和不可移动节点的数目。
可以调整开始节点和目标节点的取值范围。
WIDTH = 10
HEIGHT = 10
BLOCK_NUM = 15
map = Map(WIDTH, HEIGHT)
map.createBlock(BLOCK_NUM)
map.showMap()
source = map.generatePos((0,WIDTH//3),(0,HEIGHT//3))
dest = map.generatePos((WIDTH//2,WIDTH-1),(HEIGHT//2,HEIGHT-1))
print("source:", source)
print("dest:", dest)
AStarSearch(map, source, dest)
map.showMap()
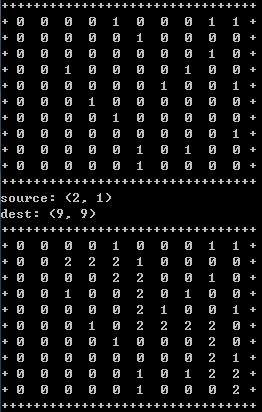
执行的效果图如下,第一个表示随机生成的地图,值为1的节点表示不能移动到该节点。
第二个图中值为2的节点表示找到的路径。
完整代码
使用python3.7编译
from random import randint
class SearchEntry():
def __init__(self, x, y, g_cost, f_cost=0, pre_entry=None):
self.x = x
self.y = y
# cost move form start entry to this entry
self.g_cost = g_cost
self.f_cost = f_cost
self.pre_entry = pre_entry
def getPos(self):
return (self.x, self.y)
class Map():
def __init__(self, width, height):
self.width = width
self.height = height
self.map = [[0 for x in range(self.width)] for y in range(self.height)]
def createBlock(self, block_num):
for i in range(block_num):
x, y = (randint(0, self.width-1), randint(0, self.height-1))
self.map[y][x] = 1
def generatePos(self, rangeX, rangeY):
x, y = (randint(rangeX[0], rangeX[1]), randint(rangeY[0], rangeY[1]))
while self.map[y][x] == 1:
x, y = (randint(rangeX[0], rangeX[1]), randint(rangeY[0], rangeY[1]))
return (x , y)
def showMap(self):
print("+" * (3 * self.width + 2))
for row in self.map:
s = '+'
for entry in row:
s += ' ' + str(entry) + ' '
s += '+'
print(s)
print("+" * (3 * self.width + 2))
def AStarSearch(map, source, dest):
def getNewPosition(map, locatioin, offset):
x,y = (location.x + offset[0], location.y + offset[1])
if x < 0 or x >= map.width or y < 0 or y >= map.height or map.map[y][x] == 1:
return None
return (x, y)
def getPositions(map, location):
# use four ways or eight ways to move
offsets = [(-1,0), (0, -1), (1, 0), (0, 1)]
#offsets = [(-1,0), (0, -1), (1, 0), (0, 1), (-1,-1), (1, -1), (-1, 1), (1, 1)]
poslist = []
for offset in offsets:
pos = getNewPosition(map, location, offset)
if pos is not None:
poslist.append(pos)
return poslist
# imporve the heuristic distance more precisely in future
def calHeuristic(pos, dest):
return abs(dest.x - pos[0]) + abs(dest.y - pos[1])
def getMoveCost(location, pos):
if location.x != pos[0] and location.y != pos[1]:
return 1.4
else:
return 1
# check if the position is in list
def isInList(list, pos):
if pos in list:
return list[pos]
return None
# add available adjacent positions
def addAdjacentPositions(map, location, dest, openlist, closedlist):
poslist = getPositions(map, location)
for pos in poslist:
# if position is already in closedlist, do nothing
if isInList(closedlist, pos) is None:
findEntry = isInList(openlist, pos)
h_cost = calHeuristic(pos, dest)
g_cost = location.g_cost + getMoveCost(location, pos)
if findEntry is None :
# if position is not in openlist, add it to openlist
openlist[pos] = SearchEntry(pos[0], pos[1], g_cost, g_cost+h_cost, location)
elif findEntry.g_cost > g_cost:
# if position is in openlist and cost is larger than current one,
# then update cost and previous position
findEntry.g_cost = g_cost
findEntry.f_cost = g_cost + h_cost
findEntry.pre_entry = location
# find a least cost position in openlist, return None if openlist is empty
def getFastPosition(openlist):
fast = None
for entry in openlist.values():
if fast is None:
fast = entry
elif fast.f_cost > entry.f_cost:
fast = entry
return fast
openlist = {}
closedlist = {}
location = SearchEntry(source[0], source[1], 0.0)
dest = SearchEntry(dest[0], dest[1], 0.0)
openlist[source] = location
while True:
location = getFastPosition(openlist)
if location is None:
# not found valid path
print("can't find valid path")
break;
if location.x == dest.x and location.y == dest.y:
break
closedlist[location.getPos()] = location
openlist.pop(location.getPos())
addAdjacentPositions(map, location, dest, openlist, closedlist)
#mark the found path at the map
while location is not None:
map.map[location.y][location.x] = 2
location = location.pre_entry
WIDTH = 10
HEIGHT = 10
BLOCK_NUM = 15
map = Map(WIDTH, HEIGHT)
map.createBlock(BLOCK_NUM)
map.showMap()
source = map.generatePos((0,WIDTH//3),(0,HEIGHT//3))
dest = map.generatePos((WIDTH//2,WIDTH-1),(HEIGHT//2,HEIGHT-1))
print("source:", source)
print("dest:", dest)
AStarSearch(map, source, dest)
map.showMap()
到此这篇关于python实现A*寻路算法的文章就介绍到这了,更多相关python A*寻路算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 实现A*算法的示例代码
A*作为最常用的路径搜索算法,值得我们去深刻的研究.路径规划项目.先看一下维基百科给的算法解释:https://en.wikipedia.org/wiki/A*_search_algorithm A *是最佳优先搜索它通过在解决方案的所有可能路径(目标)中搜索导致成本最小(行进距离最短,时间最短等)的问题来解决问题. ),并且在这些路径中,它首先考虑那些似乎最快速地引导到解决方案的路径.它是根据加权图制定的:从图的特定节点开始,它构造从该节点开始的路径树,一次一步地扩展路径,直到其一个路径在预定
-

python实现Dijkstra静态寻路算法
算法介绍 迪科斯彻算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树.该算法常用于路由算法或者作为其他图算法的一个子模块. 当然目前也有人将它用来处理物流方面,以获取代价最小的运送方案. 算法思路 Dijkstra算法采用的是一种贪心的策略. 1.首先,声明一个数组dis来保存源点到各个顶点的最短距离和一个保存已经找到了最短路径的顶点的集合T. 2.其次,原点 s 的路径权重被赋为 0 (dis[s] = 0).若对于顶点 s 存在能直接到达的边(s,m
-
Python3 A*寻路算法实现方式
我就废话不多说了,直接上代码吧! # -*- coding: utf-8 -*- import math import random import copy import time import sys import tkinter import threading # 地图 tm = [ '############################################################', '#S............................#........
-
python实现A*寻路算法
A* 算法简介 A* 算法需要维护两个数据结构:OPEN 集和 CLOSED 集.OPEN 集包含所有已搜索到的待检测节点.初始状态,OPEN集仅包含一个元素:开始节点.CLOSED集包含已检测的节点.初始状态,CLOSED集为空.每个节点还包含一个指向父节点的指针,以确定追踪关系. A* 算法会给每个搜索到的节点计算一个G+H 的和值F: F = G + H G:是从开始节点到当前节点的移动量.假设开始节点到相邻节点的移动量为1,该值会随着离开始点越来越远而增大. H:是从当前节点到目标节点的
-
python实现八大排序算法(2)
本文接上一篇博客python实现的八大排序算法part1,将继续使用python实现八大排序算法中的剩余四个:快速排序.堆排序.归并排序.基数排序 5.快速排序 快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的. 算法思想: 已知一组无序数据a[1].a[2].--a[n],需将其按升序排列.首先任取数据a[x]作为基准.比较a[x]与其它数据并排序,使a[x]排在数据的第k位,并且使a[1]~a[k-1]中的每一个数据<a[x],a[k+1]~a[n]中的每一个数
-
python实现八大排序算法(1)
排序 排序是计算机内经常进行的一种操作,其目的是将一组"无序"的记录序列调整为"有序"的记录序列.分内部排序和外部排序.若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序.反之,若参加排序的记录数量很大,整个序列的排序过程不可能完全在内存中完成,需要访问外存,则称此类排序问题为外部排序.内部排序的过程是一个逐步扩大记录的有序序列长度的过程. 看图使理解更清晰深刻: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序
-
赫赫大名的A*寻路算法(vb.net版本)
在网上看到一篇A*寻路算法的译文 http://data.gameres.com/message.asp?TopicID=25439 按此原理写了以下程序 另外补充:1.此算法不是最短路径算法. 2.在实际应用中肯定还需要优化,以适合具体游戏. 3.(vb.net2005测试通过) /Files/bearhunter/6f1e1005-a5a3-4fc9-9bfe-99a615e113ed.rar 本地下载 //
-
python简单实现基数排序算法
本文实例讲述了python简单实现基数排序算法.分享给大家供大家参考.具体实现方法如下: from random import randint def main(): A = [randint(1, 99999999) for _ in xrange(9999)] for k in xrange(8): S = [ [] for _ in xrange(10)] for j in A: S[j / (10 ** k) % 10].append(j) A = [a for b in S for a
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,
-
python实现红包裂变算法
本文实例介绍了python实现红包裂变算法,分享给大家供大家参考,具体内容如下 Python语言库函数 安装:pip install redpackets 使用: import redpackets redpackets.split(total, num, min=0.01) 1.前情提要 过年期间支付宝红包.微信红包成了全民焦点,虽然大多数的红包就一块八角的样子,还是搞得大家乐此不疲.作为一名程序猿,自然会想了解下红包的实现细节,微信目前是没有公布红包的实现细节的,所以这里就综合网上的讨论通过
-
Python实现的快速排序算法详解
本文实例讲述了Python实现的快速排序算法.分享给大家供大家参考,具体如下: 快速排序基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 如序列[6,8,1,4,3,9],选择6作为基准数.从右向左扫描,寻找比基准数小的数字为3,交换6和3的位置,[3,8,1,4,6,9],接着从左向右扫描,寻找比基准数大的数字为8,交换6和8的位置
-
js版本A*寻路算法
说到做游戏,必不可少的需要用到寻路算法,一般游戏里的寻路算法大多数都以A*算法为主,这里也就实现了js里采用a*寻路的程序,在51js和蓝色都开了帖. 程序是以前写的,后来也没有修正或者精简,有冗余之处大家还见谅一下. 当然,这个寻路算法也不是最优化的,像幻宇开发的"交点寻径法"也是个中精品,两者可谓各有千秋,只是如果地图很大的情况下,我们会惊讶于"交点寻径法"的迅速. use A* to find path... /* written by 百晓生 email:j