Python使用openpyxl批量处理数据
前言,因为经常使用Excel处理数据,像表格内的筛选,表格间数据的复制,都是简单重复的操作,十分枯燥无聊,为了提高效率,主要是自己懒,特地研究openpyxl,发现能够简化个人劳动量,自己也是小白,特意写一篇文章,共同探讨。
安装openpyxl
这个要说简单也很简单,就是 pip install openpyxl难也十分难,因为很多人安装不成功,各种报错,而且错误都是英文,还看不懂。大家可以搜索安装openpyxl,有教程指导,应该问题不大。
开始学习
首先导入库 openpyxl
import openpyxl as op
‘引入库,并把库的名字改为op,这样后面操作会少打很多字母,毕竟懒才是促进社会进步的阶梯'
打开指定工作表
wb = op.load_workbook('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
注意 \中第一个斜杠是转移符, .xlsx才是openpyxl可以处理的格式
显示工作表中有哪些子表
print(wb.sheetnames)
我操作的工作表中只有一个表,代码显示结果是

操作工作表
要实现操作工作表,首先要选中它
w1 = wb['表1']
有多种方法可以选中这个表,这里就用最简单的一种,就是 工作表 + 子表名字
打印一个A1表格的内容
print((w1['A1'].value))
打印一列表格的内容,
for i in w1['A']:
print(i.value)
打印一列表格中部分内容
for i in w1['A2':'A5']:
for j in i:
print(j.value)
注意,这里多加了一个循环,在选中一列中部分表格时(A2到A5),第一次循环产生的格式和选中整列的格式会不一样,需要再一次循环,才能访问到单元格的值
批量改变某一列的内容
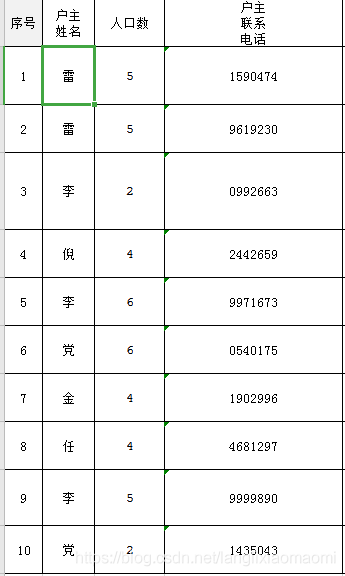
我们将给户主姓名这一列加入数字,一次为1,2,3,4…
import openpyxl as op
wb = op.load_workbook('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
print(wb.sheetnames)
w1 = wb['表1']
m = 0
for i in w1['B3':'B12']:
for j in i:
m = m + 1
s = j.value + str(m)
w1['B%d'%(m+2)] = s
wb.save('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
运行后表格如下
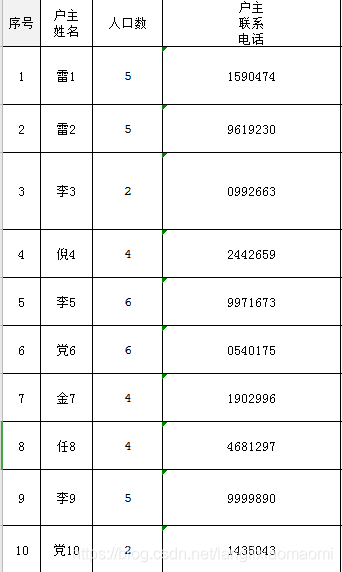
需要注意的是,操作时表格应处于关闭状态,操作完需要保存命令
根据某一项内容,改变对应项的内容
如果姓名含“雷”这个字,则要将其电话更改为0
import openpyxl as op
wb = op.load_workbook('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
print(wb.sheetnames)
w1 = wb['表1']
m = 0
for i in w1['B3':'B12']:
for j in i:
for n in j.value:
if n == '雷':
s = str(j)
s = s[-3:]
s = ''.join([x for x in s if x.isdigit()])
s = int(s)
w1['D%d'%s] = 0
print(s)
wb.save('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
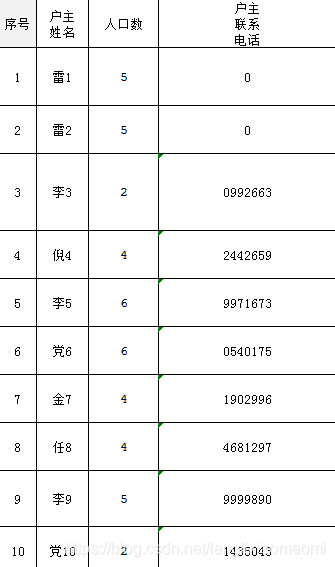
这段代码实现了我们的诉求,即如果姓名含“雷”这个字,则要将其电话更改为0,但是十分丑陋,因为我没找到一个简洁的命令或是方法,实现根据单元格参数筛选出对应的行数,希望有这个的大神指点迷津,这是这段代码的结果
总结
python 很强大,openpyxl也很强大,能够批量处理Excel数据,但本人python功底不足,代码实在不好看,希望有大神指点一二,共同提高python水平
以上就是Python使用openpyxl批量处理数据的详细内容,更多关于Python批量处理的资料请关注我们其它相关文章!
相关推荐
-

python利用openpyxl拆分多个工作表的工作簿的方法
实现按目录拆分工作簿,源数据如下图 按目录拆分成N个文件. 上代码,没有找是否有整个sheet 复制的,先逐个cell复制解决问题.: # encoding: utf-8 """ @author: 陈年椰子 @contact: hndm@qq.com @version: 1.0 @file: Split_Xls.py @time: 2019/9/24 0028 15:04 说明 """ def Split_Xls(xls_file): from
-
python 的 openpyxl模块 读取 Excel文件的方法
Python 的 openpyxl 模块可以让我们能读取和修改 Excel 文件. 首先让我们先理解一些 Excel 基础概念. 1 Excel 基础概念 Excel 文件也称做为工作簿.每个工作簿可以包含多个工作表(Sheet).用户当前查看的表或关闭 Excel 前最后查看的表,称为活动表. 每一张表都是由列和行构成的.列是以 A 开始的字母表示:而行是以 1 开始的数字表示的.由特定行和列所指定的方格称为单元格.每个单元格都可以包含一个数字或文本.这些单元格就构成了这张表. 2 安装 op
-
python openpyxl使用方法详解
openpyxl特点 openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易 注意:如果文字编码是"gb2312" 读取后就会显示乱码,请先转成Unicode 1.openpyxl 读写单元格时,单元格的坐标位置起始值是(1,1),即下标最小值为1,否则报错! tableTitle = ['userName', 'Phone', 'age', 'Remark'] # 维护表头 # if row < 1 or co
-
python批量处理txt文件的实例代码
通过python对多个txt文件进行处理 读取路径,读取文件 获取文件名,路径名 对响应的文件夹名字进行排序 对txt文件内部的数据相应的某一列/某一行进行均值处理 写入到事先准备好的Excel文件中 关闭Excel文件 #import numpy as np import pandas as pd import os folder = 'D:/log/A190820C31N82' def all_files_in_a_folder_iter(folder): import os for roo
-
python 利用openpyxl读取Excel表格中指定的行或列教程
Worksheet 对象的 rows 属性和 columns 属性得到的是一 Generator 对象,不能用中括号取索引. 可先用列表推导式生成包含每一列中所有单元格的元组的列表,在对列表取索引. Worksheet 的 rows 属性亦可用相同的方法处理. 补充:python之表格数据读取 python 操作excel主要用到xlrd,xlwt这两个库,xlrd,是读取excel表,xlwt是写入表格 1.打开表格 table = xlrd.open("path_to_your_excel&
-
浅谈Python_Openpyxl使用(最全总结)
Python_Openpyxl 1. 安装 pip install openpyxl 2. 打开文件 ① 创建 from openpyxl import Workbook # 实例化 wb = Workbook() # 激活 worksheet ws = wb.active ② 打开已有 >>> from openpyxl import load_workbook >>> wb2 = load_workbook('文件名称.xlsx') 3. 储存数据 # 方式一:数据
-
python3.7 openpyxl 删除指定一列或者一行的代码
python3.7 openpyxl 删除指定一列或者一行 # encoding:utf-8 import pandas as pd import openpyxl xl = pd.read_excel(r"E:\55\CRM经营分析表-10001741-1570416265044.xls") xl.to_excel(r"E:\55\crms.xlsx") wk = openpyxl.load_workbook(r"E:\55\crms.xlsx"
-
python遍历文件目录、批量处理同类文件
本文实例为大家分享了python遍历文件目录.批量处理同类文件的具体代码,供大家参考,具体内容如下 目录操作 1.获取当前目录 import os curr_path=os.path.dirname(__file__) #返回当前文件所在的目录,即当前运行的脚本所在父目录 print curr_path 运行示例 (1)使用os.path.dirname(__file__)时,是针对运行时对所给程序脚本的路径来获取父目录的,即截取你输入的脚本路径的所在目录名称,如上图示例,输入绝对路径时返回绝对
-
基于python批量处理dat文件及科学计算方法详解
摘要:主要介绍一些python的文件读取功能,文件内容修改,文件名后缀更改等操作. 批处理文件功能 import os path1 = 'C:\\Users\\awake_ljw\\Documents\\python for data analysis\\test1' path2 = 'C:\\Users\\awake_ljw\\Documents\\python for data analysis\\test2' filelist = os.listdir(path1) for files i
-
Python使用openpyxl批量处理数据
前言,因为经常使用Excel处理数据,像表格内的筛选,表格间数据的复制,都是简单重复的操作,十分枯燥无聊,为了提高效率,主要是自己懒,特地研究openpyxl,发现能够简化个人劳动量,自己也是小白,特意写一篇文章,共同探讨. 安装openpyxl 这个要说简单也很简单,就是 pip install openpyxl 难也十分难,因为很多人安装不成功,各种报错,而且错误都是英文,还看不懂.大家可以搜索安装openpyxl,有教程指导,应该问题不大. 开始学习 首先导入库 openpyxl impo
-
Python向MySQL批量插数据的实例讲解
背景:最近测试web项目需要多条测试数据,sql中嫌要写多条,就看了看python如何向MySQL批量插数据(pymysql库) 1.向MySQL批量插数据 import pymysql #import datetime #day = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')#参数值插入时间 db = pymysql.connect(host='服务器IP', user='账号', passwd='密码', port=端口号) c
-
Python操控mysql批量插入数据的实现方法
在Python中,通过pymysql模块,编写简短的脚本,即方便快捷地控制MySQL数据库 一.连接数据库 使用的函数:pymysql.connect 语法:db=pymysql.connect(host='localhost',user='root',port=3306,password='Your password',db='database_name') 参数说明:host:MySQL服务器地址 user:用户名
-
python 使用openpyxl读取excel数据
openpyxl介绍 openpyxl是一个开源项目,它是一个用于读取/写入Excel 2010文档(如xlsx .xlsm .xltx .xltm文件 )的Python库,如果要处理更早格式的Excel文档(xls),需要用到其它库(如:xlrd.xlwt等),这是openpyxl比较其他模块的不足之处.openpyxl是一款比较综合的工具,不仅能够同时读取和修改Excel文档,而且可以对Excel文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入.打印设置等内容. p
-
python Django批量导入数据
前言: 这期间有研究了Django网页制作过程中,如何将数据批量导入到数据库中. 这个过程真的是惨不忍睹,犯了很多的低级错误,这会在正文中说到的.再者导入数据用的是py脚本,脚本内容参考至自强学堂--中级教程--数据导入. 注:本文主要介绍自己学习的经验总结,而非教程! 正文:首先说明采用Django中bulk_create()函数来实现数据批量导入功能,为什么会选择它呢? 1 bulk_create()是执行一条SQL存入多条数据,使得导入速度更快; 2 bulk_create()减少了SQ
-
python使用openpyxl库修改excel表格数据方法
1.openpyxl库可以读写xlsx格式的文件,对于xls旧格式的文件只能用xlrd读,xlwt写来完成了. 简单封装类: from openpyxl import load_workbook from openpyxl import Workbook from openpyxl.chart import BarChart, Series, Reference, BarChart3D from openpyxl.styles import Color, Font, Alignment from
-
python批量导入数据进Elasticsearch的实例
ES在之前的博客已有介绍,提供很多接口,本文介绍如何使用python批量导入.ES官网上有较多说明文档,仔细研究并结合搜索引擎应该不难使用. 先给代码 #coding=utf-8 from datetime import datetime from elasticsearch import Elasticsearch from elasticsearch import helpers es = Elasticsearch() actions = [] f=open('index.txt') i=
-
Python从数据库读取大量数据批量写入文件的方法
使用机器学习训练数据时,如果数据量较大可能我们不能够一次性将数据加载进内存,这时我们需要将数据进行预处理,分批次加载进内存. 下面是代码作用是将数据从数据库读取出来分批次写入txt文本文件,方便我们做数据的预处理和训练机器学习模型. #%% import pymssql as MySQLdb #这里是python3 如果你是python2.x的话,import MySQLdb #数据库连接属性 hst = '188.10.34.18' usr = 'sa' passwd = 'p@ssw0rd'
-
python数据库批量插入数据的实现(executemany的使用)
正常情况下往数据库多张表中批量插入1000条数据,若一条一条insert插入,则调用sql语句查询插入需要执行几千次,花费时间长 现使用cursor.executemany(sql,args) ,可对数据进行批量插入, 其中args是一个包含多个元组的list列表,每个元组对应mysql当中的一条数据 以下是实例: 往数据库中的order表.order_detail表和pay表中插入1000条订单数据,订单详情数据以及支付数据 1.pay表中的id字段是order表中的pay_id字段 2.or
-
Python自动化之批量生成含指定数据的word文档
目录 一.需求说明 二.开始动手动脑 三.总结 一.需求说明 在平时工作当中,经常需要处理文件,特别是Word,处理Word时会遇一类比较常见的场景:文档中大部分文字固定不变,小部分内容需要修改. 这时我们会机械的重复打开.修改.保存文档等一系列操作,内容少还可勉强接受,内容一旦多了,心里难免会心浮气躁. 今天我要给大家介绍一个秘密武器-docxtpl开发包,有了这个只需写一份模板,其他的都交给电脑自己进行. 首先需要你的电脑安装好了Python环境,并且安装好了Python开发工具. 如果你还