Python机器学习pytorch交叉熵损失函数的深刻理解
目录
- 1.交叉熵损失函数的推导
- 2. 交叉熵损失函数的直观理解
- 3. 交叉熵损失函数的其它形式
- 4.总结
说起交叉熵损失函数「Cross Entropy Loss」,脑海中立马浮现出它的公式:
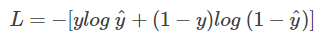
我们已经对这个交叉熵函数非常熟悉,大多数情况下都是直接拿来使用就好。但是它是怎么来的?为什么它能表征真实样本标签和预测概率之间的差值?上面的交叉熵函数是否有其它变种?
1.交叉熵损失函数的推导
我们知道,在二分类问题模型:例如逻辑回归「Logistic Regression」、神经网络「Neural Network」等,真实样本的标签为 [0,1],分别表示负类和正类。模型的最后通常会经过一个 Sigmoid 函数,输出一个概率值,这个概率值反映了预测为正类的可能性:概率越大,可能性越大。
Sigmoid 函数的表达式和图形如下所示:
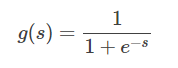
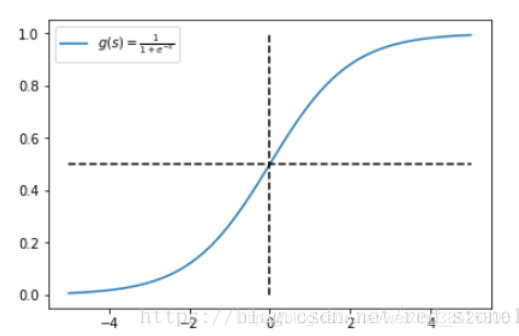
其中 s 是模型上一层的输出,Sigmoid 函数有这样的特点:s = 0 时,g(s) = 0.5;s >> 0 时, g ≈ 1,s << 0 时,g ≈ 0。显然,g(s) 将前一级的线性输出映射到 [0,1] 之间的数值概率上。这里的 g(s) 就是交叉熵公式中的模型预测输出 。
我们说了,预测输出即 Sigmoid 函数的输出表征了当前样本标签为 1 的概率:

很明显,当前样本标签为 0 的概率就可以表达成:
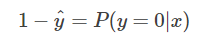
重点来了,如果我们从极大似然性的角度出发,把上面两种情况整合到一起:
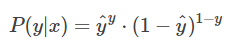
不懂极大似然估计也没关系。我们可以这么来看:
当真实样本标签 y = 0 时,上面式子第一项就为 1,概率等式转化为:
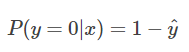
当真实样本标签 y = 1 时,上面式子第二项就为 1,概率等式转化为:
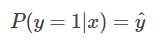
两种情况下概率表达式跟之前的完全一致,只不过我们把两种情况整合在一起了。
重点看一下整合之后的概率表达式,我们希望的是概率 P(y|x) 越大越好。首先,我们对 P(y|x) 引入 log 函数,因为 log 运算并不会影响函数本身的单调性。则有:
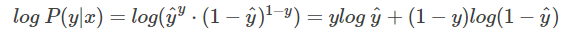
我们希望 log P(y|x) 越大越好,反过来,只要 log P(y|x) 的负值 -log P(y|x) 越小就行了。那我们就可以引入损失函数,且令 Loss = -log P(y|x)即可。则得到损失函数为:
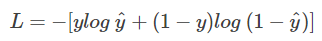
非常简单,我们已经推导出了单个样本的损失函数,是如果是计算 N 个样本的总的损失函数,只要将 N 个 Loss 叠加起来就可以了:
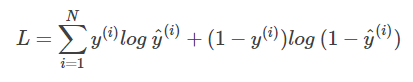
这样,我们已经完整地实现了交叉熵损失函数的推导过程。
2. 交叉熵损失函数的直观理解
我已经知道了交叉熵损失函数的推导过程。但是能不能从更直观的角度去理解这个表达式呢?而不是仅仅记住这个公式。好问题!接下来,我们从图形的角度,分析交叉熵函数,加深理解。
首先,还是写出单个样本的交叉熵损失函数:
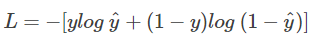
我们知道,当 y = 1 时
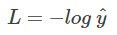
这时候,L 与预测输出的关系如下图所示:
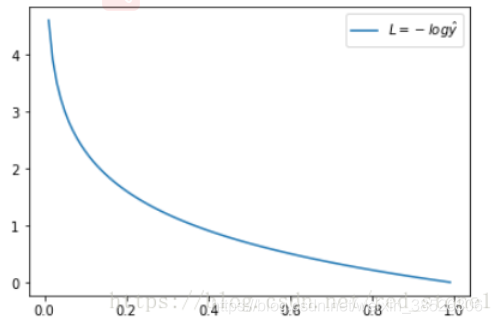
看了 L 的图形,简单明了!横坐标是预测输出,纵坐标是交叉熵损失函数 L。显然,预测输出越接近真实样本标签 1,损失函数 L 越小;预测输出越接近 0,L 越大。因此,函数的变化趋势完全符合实际需要的情况。
当 y = 0 时:
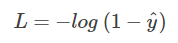
这时候,L 与预测输出的关系如下图所示:
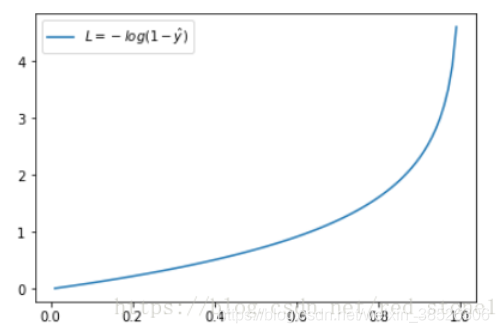
同样,预测输出越接近真实样本标签 0,损失函数 L 越小;预测函数越接近 1,L 越大。函数的变化趋势也完全符合实际需要的情况。
从上面两种图,可以帮助我们对交叉熵损失函数有更直观的理解。无论真实样本标签 y 是 0 还是 1,L 都表征了预测输出与 y 的差距。
另外,重点提一点的是,从图形中我们可以发现:预测输出与 y 差得越多,L 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。这样的好处是模型会倾向于让预测输出更接近真实样本标签 y。
3. 交叉熵损失函数的其它形式
什么?交叉熵损失函数还有其它形式?没错!我刚才介绍的是一个典型的形式。接下来我将从另一个角度推导新的交叉熵损失函数。
这种形式下假设真实样本的标签为 +1 和 -1,分别表示正类和负类。有个已知的知识点是Sigmoid 函数具有如下性质:
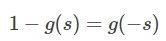
这个性质我们先放在这,待会有用。
好了,我们之前说了 y = +1 时,下列等式成立:
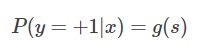
如果 y = -1 时,并引入 Sigmoid 函数的性质,下列等式成立:
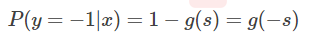
重点来了,因为 y 取值为 +1 或 -1,可以把 y 值带入,将上面两个式子整合到一起:
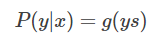
这个比较好理解,分别令 y = +1 和 y = -1 就能得到上面两个式子。
接下来,同样引入 log 函数,得到:
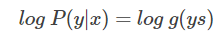
要让概率最大,反过来,只要其负数最小即可。那么就可以定义相应的损失函数为:
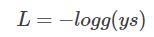
还记得 Sigmoid 函数的表达式吧?将 g(ys) 带入:
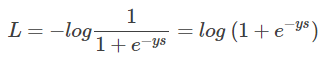
好咯,L 就是我要推导的交叉熵损失函数。如果是 N 个样本,其交叉熵损失函数为:
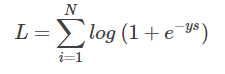
接下来,我们从图形化直观角度来看。当 y = +1 时:
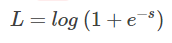
这时候,L 与上一层得分函数 s 的关系如下图所示:

横坐标是 s,纵坐标是 L。显然,s 越接近正无穷,损失函数 L 越小;s 越接近负无穷,L 越大。
另一方面,当 y = -1 时:
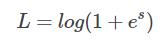
这时候,L 与上一层得分函数 s 的关系如下图所示:
同样,s 越接近负无穷,损失函数 L 越小;s 越接近正无穷,L 越大。
4.总结
本文主要介绍了交叉熵损失函数的数学原理和推导过程,也从不同角度介绍了交叉熵损失函数的两种形式。第一种形式在实际应用中更加常见,例如神经网络等复杂模型;第二种多用于简单的逻辑回归模型。
需要注意的是:第一个公式中的变量是sigmoid输出的值,第二个公式中的变量是sigmoid输入的值。
以上就是Python机器学习交叉熵损失函数的深刻理解的详细内容,更多关于pytorch交叉熵损失函数的资料请关注我们其它相关文章!
相关推荐
-

pytorch交叉熵损失函数的weight参数的使用
首先 必须将权重也转为Tensor的cuda格式: 然后 将该class_weight作为交叉熵函数对应参数的输入值. class_weight = torch.FloatTensor([0.13859937, 0.5821059, 0.63871904, 2.30220396, 7.1588294, 0]).cuda() 补充:关于pytorch的CrossEntropyLoss的weight参数 首先这个weight参数比想象中的要考虑的多 你可以试试下面代码 import torch im
-
pytorch中常用的损失函数用法说明
1. pytorch中常用的损失函数列举 pytorch中的nn模块提供了很多可以直接使用的loss函数, 比如MSELoss(), CrossEntropyLoss(), NLLLoss() 等 官方链接: https://pytorch.org/docs/stable/_modules/torch/nn/modules/loss.html pytorch中常用的损失函数 损失函数 名称 适用场景 torch.nn.MSELoss() 均方误差损失 回归 torch.nn.L1Loss() 平
-
PyTorch的SoftMax交叉熵损失和梯度用法
在PyTorch中可以方便的验证SoftMax交叉熵损失和对输入梯度的计算 关于softmax_cross_entropy求导的过程,可以参考HERE 示例: # -*- coding: utf-8 -*- import torch import torch.autograd as autograd from torch.autograd import Variable import torch.nn.functional as F import torch.nn as nn import nu
-
Pytorch十九种损失函数的使用详解
损失函数通过torch.nn包实现, 1 基本用法 criterion = LossCriterion() #构造函数有自己的参数 loss = criterion(x, y) #调用标准时也有参数 2 损失函数 2-1 L1范数损失 L1Loss 计算 output 和 target 之差的绝对值. torch.nn.L1Loss(reduction='mean') 参数: reduction-三个值,none: 不使用约简:mean:返回loss和的平均值: sum:返回loss的和.默认:
-
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果.这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文. 测试代码(一维) import torch import torch.nn as nn import math criterion = nn.CrossEntropyLoss() output = torch.randn(1, 5, requires_grad=True) label = tor
-
Python机器学习pytorch交叉熵损失函数的深刻理解
目录 1.交叉熵损失函数的推导 2. 交叉熵损失函数的直观理解 3. 交叉熵损失函数的其它形式 4.总结 说起交叉熵损失函数「Cross Entropy Loss」,脑海中立马浮现出它的公式: 我们已经对这个交叉熵函数非常熟悉,大多数情况下都是直接拿来使用就好.但是它是怎么来的?为什么它能表征真实样本标签和预测概率之间的差值?上面的交叉熵函数是否有其它变种? 1.交叉熵损失函数的推导 我们知道,在二分类问题模型:例如逻辑回归「Logistic Regression」.神经网络「Neural Ne
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
解决pytorch 交叉熵损失输出为负数的问题
网络训练中,loss曲线非常奇怪 交叉熵怎么会有负数. 经过排查,交叉熵不是有个负对数吗,当网络输出的概率是0-1时,正数.可当网络输出大于1的数,就有可能变成负数. 所以加上一行就行了 out1 = F.softmax(out1, dim=1) 补充知识:在pytorch框架下,训练model过程中,loss=nan问题时该怎么解决? 当我在UCF-101数据集训练alexnet时,epoch设为100,跑到三十多个epoch时,出现了loss=nan问题,当时是一脸懵逼,在查阅资料后,我通过
-
python机器学习pytorch 张量基础教程
目录 正文 1.初始化张量 1.1 直接从列表数据初始化 1.2 用 NumPy 数组初始化 1.3 从另一个张量初始化 1.4 使用随机值或常量值初始化 2.张量的属性 3.张量运算 3.1 标准的类似 numpy 的索引和切片: 3.2 连接张量 3.3 算术运算 3.4单元素张量 Single-element tensors 3.5 In-place 操作 4. 张量和NumPy 桥接 4.1 张量到 NumPy 数组 4.2 NumPy 数组到张量 正文 张量是一种特殊的数据结构,与数组
-
python机器学习pytorch自定义数据加载器
目录 正文 1. 加载数据集 2. 迭代和可视化数据集 3.创建自定义数据集 3.1 __init__ 3.2 __len__ 3.3 __getitem__ 4. 使用 DataLoaders 为训练准备数据 5.遍历 DataLoader 正文 处理数据样本的代码可能会逐渐变得混乱且难以维护:理想情况下,我们希望我们的数据集代码与我们的模型训练代码分离,以获得更好的可读性和模块化.PyTorch 提供了两个数据原语:torch.utils.data.DataLoader和torch.util
-
基于KL散度、JS散度以及交叉熵的对比
在看论文<Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection>时,文中提到了这三种方法来比较时间序列中不同区域概率分布的差异. KL散度.JS散度和交叉熵 三者都是用来衡量两个概率分布之间的差异性的指标.不同之处在于它们的数学表达. 对于概率分布P(x)和Q(x) 1)KL散度(Kullback–Leibler divergence) 又称KL距离,相对熵. 当P(x)和Q(x)的相似度越高
-
pytorch 实现二分类交叉熵逆样本频率权重
通常,由于类别不均衡,需要使用weighted cross entropy loss平衡. def inverse_freq(label): """ 输入label [N,1,H,W],1是channel数目 """ den = label.sum() # 0 _,_,h,w= label.shape num = h*w alpha = den/num # 0 return torch.tensor([alpha, 1-alpha]).cuda(