浅谈mysql 树形结构表设计与优化
前言
在诸多的管理类,办公类等系统中,树形结构展示随处可见,以“部门”或"机构"来说,接触过的同学应该都知道,最终展示到页面的效果就是层级结构的那种,下图随机列举了一个部门的树型结构展示图

设计考虑因素
1、表结构设计
稍稍有点开发和表结构设计经验的同学,设计出这样一张表,应该很容易,只需要在depart表中,添加一个pid/字段即可满足要求,参考下表:
CREATE TABLE `depart` ( `depart_id` varchar(32) NOT NULL COMMENT '部门ID', `pid` varchar(32) NOT NULL DEFAULT '0' COMMENT '组织父ID', `name` varchar(64) NOT NULL COMMENT '部门名称', `description` varchar(512) DEFAULT NULL COMMENT '部门描述', `code` varchar(64) DEFAULT NULL COMMENT '部门编码', PRIMARY KEY (`depart_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、业务设计
上图是一个通用的树状结构示意图,适合大多数的业务场景,以此为例,如果“部门”不是单独的存在,与部门相关的业务主要包括下面几点:
- 部门是否单独的存在,可能与部门存在直接关联的业务,比如:部门下面可以关联用户
- 部门的效果展示,加载部门树形列表时候,是动态加载呢?还是一次性返回呢?
- 和部门增删改查相关的业务
- 替他关联部门的业务,即部门是被关联的业务对象
3、性能考虑
- 全量加载不可取,没有办法的最后考虑,层级一旦过深,数据量一旦过大,查询性能将会成为噩梦
- 动态加载效果比较好,服务端开销和压力相对全量加载小很多,但动态加载的问题也很明显,层级一旦深了,用户操作体验不佳
- 层级结构的功能,对数据导入即excel导入功能实现的编码复杂度增加
关于第一点,第二点再做几点额外的补充,全量加载和动态加载的实现都可以,在小编历经的项目或产品中都有见到,实在是要看产品的设计和客户的要求,因为全量和动态加载的不同设计也会带来与之相对结果
举例来说,全量加载的好处是,数据一次性的返回给页面,页面做了渲染之后存缓存,后续再次加载的时候速度非常快,同时,类似下面这种搜索效率就非常高,因为不需要与接口交互啊

但问题也随之而来了,部门数据不是一成不变的,增删改的操作也是常有的事情,设计成全量加载,意味着初次查询的时候,一旦数据量超大,层级非常深,假如页面还需要渲染部门下关联的用户数据时,这个对服务端的压力就非常大了,稍有经验的同学应该能大概想到这个服务端的返回数据结构了吧

下面给出初步的实现思路
function(currentDepart_id){
1、查找当前部门
DB ......
2、查找当前部门的子级部门
DB ......
3、以当前部门的子部门列表为根基进行遍历,递归查询,包装返回数据
DB ......
}
从以上的代码实现来看,数据量上去之后,预估查询将会成为性能瓶颈,而且在小编的项目开发中,做过类似的测试,3个层级,每层1000条数据(未计算部门下关联用户的数据加载),在4核16G的服务器上(CPU性能普通),完成一次全量的数据加载平均在3秒左右,这个对于B端的产品,这种设计加上这种延时,用户还能接受(1000个部门,这种数据量是比较大的了)
上面分析到,全量加载的性能瓶颈在于数据库的IO,试想,查询的时候,从顶级节点或者某个节点算起,数据量越大,层级越深,查询的次数就越多,IO的开销自然就越大
解决的办法是什么呢?实践过程中,有2个经验可以参考:
- 设计合理的缓存存储结构
- 改进表结构
关于第一点,也是大家容易想到的,但如何设计才比较合理呢?以下面的这张图为例,我们可以考虑以非叶子节点为key,而叶子节点下面的集合为value,将所有的value存入一个redis的集合中,这种考虑来源于实际业务中,用户的需求验证,即真正那些具有实际意义的部门或机构数据都分布在叶子节点上面

如此一来,编码的实现上面,也许可以改造成下面这样,
1、部门新增
functiob add(params){
1、depart入库
DB ......
2、判断当前的depart的层级,是否叶子节点(是否即将成为叶子节点)
if(叶子节点){
3、寻找上级节点ID,并查询redis中的key
4、取出上级key对应的缓存集合,加入当前新增的part_id
} else {
5、创建一个新的key,即一个新的缓存空集合,等待后续数据添加(也可以不创建)
}
}
2、删除部门
functiob delete(params){
1、depart自身的删除
DB ......
2、如果当前部门下存在子集部门,是否需要一起删除子部门(结合自身的产品业务)
DB......
获取所有的非叶子节点集合
3、假设第二步成立,那么还需要以当前部门节点创建的key,并取出key中的list集合,一起进行删掉
Redis操作
拿到第二步中的所有非叶子节点集合,组装成key,循环遍历删除key(内存型操作,性能不是问题,也可以做异步)
}
全量加载结合redis是突破性能瓶颈的关键步骤,但从上面的实现上看,从编码的复杂性上确实有所提升,而且对开发者的编码要求有一定高度,但这种实现之后,可以说很大程度上将会提升查询的性能
优化查询性能的第二种考虑,表结构的改造
不少同学有疑问,表结构的改造对于性能影响能有多大呢?说出来可能你不信,模拟数据压测的时候,不采用改造后的实现,利用 5个层级的部门,每个部门1000的数据量(我指的是每个层级的每个部门数据量都是1000,大家可以计算下数据总量),每个部门下关联了500个用户,这样的数据量的最后表现是5分钟左右
看来,数据量上去了之后,查询压力确实很大,利用改造后的设计和测试效果,最终同样的数据表现,平均在15~20秒之间,这个直接是10倍多的提升,或许在我说出答案之前,也有不少同学用过,但是没有真正体会到它的妙处
在本文开始的表结构基础上面,我们加一个path字段,这样改造后的表如下:
CREATE TABLE `depart` ( `depart_id` varchar(32) NOT NULL COMMENT '部门ID', `pid` varchar(32) NOT NULL DEFAULT '0' COMMENT '组织父ID', `name` varchar(64) NOT NULL COMMENT '部门名称', `description` varchar(512) DEFAULT NULL COMMENT '部门描述', `code` varchar(64) DEFAULT NULL COMMENT '部门编码', PRIMARY KEY (`depart_id`), `path` varchar(128) NOT NULL COMMENT '部门路径', ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
这个path字段意义重大,通常的表现是,从第一个层级开始,每个层级假设最多可容纳10000个部门,这样第一层的数据大概长这样, 00001 ,00002,00003 … 往上依次累加,而第二层级,假如我们在00002这个部门下新增第二层级的部门时,数据表现大概长这样, 00002/00001 , 00002/00002 , 00002/00003 …往上依次累加
那么更深的层级,我就算不举例想必大家也能自行列举出后面的结构来
这么做有什么好处呢?
我们知道,mysql是支持正则表达式函数的,还有就是like,试想,我们要想一次性查询出从某个层级开始下面的所有的层级数据时,假如没有path这个字段,会怎么做呢?很明显,就是上文所说的通过递归了
但是有了path字段之后,我们可以直接利用mysql的正则表达式函数,,仍以上面的数据为例,通过下面的这两种sql,一次性的可以将一级部门(测试)这条数据的所有子集数据全部查出来,这样一来,可以说大大减少了与数据库的交互次数
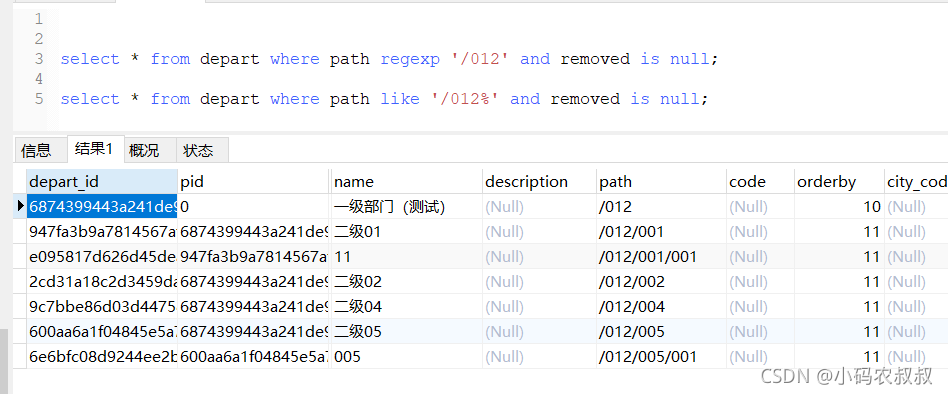
此种实现容易踩坑,或者实际操作中比较容易出问题的地方在路径规则的生成上面,通常需要提前自定义一个函数,专门用户生成path,只要确保生成的path字段数据准确无误,这种实现从优化查询的性能提升上面,是很大的突破,小编所在的开发项目中,使用的便是这种方式
function generatePath(pid){
1、pid是否为顶级
2、获取父级部门的depart
3、列举出父级部门下与当前即将新增的部门同级的所有path字段
4、取出第三步中的path最大值
5、根据第四步的path最大值生成新的path
}
另外一个比较难啃的业务是,以path字段的设计之后,做部门数据的excel导入时,这个path的处理仍然是个比较复杂的实现点,这一点留待大家思考。
以上探讨了全量加载下,从业务实现到代码设计层面的优化 , 以及表结构设计层面优化的2个方面做了比较深入的探讨,而动态加载的实现,相对来说,可以说在上面这两种实现方案的基础上,稍作引用即可,难度更小
总结下来,这里推荐一个关于这种带有层级结构形状的业务设计上的最佳实践,
表结构上,采用path字段数据加载上,尽量使用动态加载如果部门(层级结构的业务)变动不大,可以考虑引入缓存,具体实践参考本文上面所说
到此这篇关于浅谈mysql 树形结构表设计与优化的文章就介绍到这了,更多相关mysql 树形结构表优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈MYSQL中树形结构表3种设计优劣分析与分享
目录 简介 问题 设计1:邻接表 表设计 SQL示例 设计2:路径枚举 表设计 SQL示例 设计3:闭包表 表设计 SQL示例 结合使用 表设计 总结 简介 在开发中经常遇到树形结构的场景,本文将以部门表为例对比几种设计的优缺点: 问题 需求背景:根据部门检索人员, 问题:选择一个顶级部门情况下,跨级展示当前部门以及子部门下的所有人员,表怎么设计更合理 ? 递归吗 ?递归可以解决,但是势必消耗性能 设计1:邻接表 注:(常见父Id设计) 表设计 CREATE TABLE `dept_info01
-
浅谈mysql 树形结构表设计与优化
前言 在诸多的管理类,办公类等系统中,树形结构展示随处可见,以"部门"或"机构"来说,接触过的同学应该都知道,最终展示到页面的效果就是层级结构的那种,下图随机列举了一个部门的树型结构展示图 设计考虑因素 1.表结构设计 稍稍有点开发和表结构设计经验的同学,设计出这样一张表,应该很容易,只需要在depart表中,添加一个pid/字段即可满足要求,参考下表: CREATE TABLE `depart` ( `depart_id` varchar(32) NOT NULL
-
浅谈mysql一张表到底能存多少数据
程序员平时和mysql打交道一定不少,可以说每天都有接触到,但是mysql一张表到底能存多少数据呢?计算根据是什么呢?接下来咱们逐一探讨 知识准备 数据页 在操作系统中,我们知道为了跟磁盘交互,内存也是分页的,一页大小4KB.同样的在MySQL中为了提高吞吐率,数据也是分页的,不过MySQL的数据页大小是16KB.(确切的说是InnoDB数据页大小16KB).详细学习可以参考官网我们可以用如下命令查询到. mysql> SHOW GLOBAL STATUS LIKE 'innodb_page_s
-
浅谈MySQL user权限表
MySQL 在安装时会自动创建一个名为 mysql 的数据库,mysql 数据库中存储的都是用户权限表.用户登录以后,MySQL 会根据这些权限表的内容为每个用户赋予相应的权限. user 表是 MySQL 中最重要的一个权限表,用来记录允许连接到服务器的账号信息.需要注意的是,在 user 表里启用的所有权限都是全局级的,适用于所有数据库. user 表中的字段大致可以分为 4 类,分别是用户列.权限列.安全列和资源控制列,下面主要介绍这些字段的含义. 用户列 用户列存储了用户连接 MySQL
-
浅谈mysql 针对单张表的备份与还原
A.MySQL 备份工具xtrabackup 的安装 1. percona 官方xtrabackup 的二进制版本:二进制版本解压就能用了. 2. 解压xtrabackup & 创建连接 tar -xzvf percona-xtrabackup-2.3.4-Linux-x86_64.tar.gz -C /usr/local/ ln -s /usr/local/percona-xtrabackup-2.3.4 /usr/local/xtrabackup 3. 设置PATH环境变量 export P
-
浅谈mysql中多表不关联查询的实现方法
大家在使用MySQL查询时正常是直接一个表的查询,要不然也就是多表的关联查询,使用到了左联结(left join).右联结(right join).内联结(inner join).外联结(outer join).这种都是两个表之间有一定关联,也就是我们常常说的有一个外键对应关系,可以使用到 a.id = b.aId这种语句去写的关系了.这种是大家常常使用的,可是有时候我们会需要去同时查询两个或者是多个表的时候,这些表又是没有互相关联的,比如要查user表和user_history表中的某一些数据
-
浅谈MySQL 亿级数据分页的优化
背景 下班后愉快的坐在在回家的地铁上,心里想着周末的生活怎么安排. 突然电话响了起来,一看是我们的一个开发同学,顿时紧张了起来,本周的版本已经发布过了,这时候打电话一般来说是线上出问题了. 果然,沟通的情况是线上的一个查询数据的接口被疯狂的失去理智般的调用,这个操作直接导致线上的MySql集群被拖慢了. 好吧,这问题算是严重了,下了地铁匆匆赶到家,开电脑,跟同事把Pinpoint上的慢查询日志捞出来.看到一个很奇怪的查询,如下 POST domain/v1.0/module/method?ord
-
浅谈mysql的索引设计原则以及常见索引的区别
索引定义:是一个单独的,存储在磁盘上的数据库结构,其包含着对数据表里所有记录的引用指针. 数据库索引的设计原则: 为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引. 那么索引设计原则又是怎样的? 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录. 例如,学生表中学号是具有唯一性的字段.为该字段建立唯一性索引可以很快的确定某个学生的信息. 如果使用姓名的话,可能存在同名现象,从而降低查询速度. 2.为经常需要排序.分组和联合操
-
浅谈MySQL大表优化方案
背景 阿里云RDS FOR MySQL(MySQL5.7版本)数据库业务表每月新增数据量超过千万,随着数据量持续增加,我们业务出现大表慢查询,在业务高峰期主业务表的慢查询需要几十秒严重影响业务 方案概述 一.数据库设计及索引优化 MySQL数据库本身高度灵活,造成性能不足,严重依赖开发人员的表设计能力以及索引优化能力,在这里给几点优化建议 时间类型转化为时间戳格式,用int类型储存,建索引增加查询效率 建议字段定义not null,null值很难查询优化且占用额外的索引空间 使用TINYINT类
-
浅谈MySQL如何优雅的做大表删除
随着时间的推移或者业务量的增长,数据库空间使用率也不断的呈稳定上升状态,当数据库空间将要达到瓶颈的时候,可能我们才会发现数据库有那么一两张的超级大表!他们堆积了从业务开始到现在的全部数据,但是90%的数据都是没有业务价值的,这时候该如何处理这些大表? 既然是没有价值的数据,我们通常一般会选择直接删除或者归档后删除两种,对于数据删除的操作方式来说又可分为两大类: 通过truncate直接删除表中全部数据 通过delete删除表中满足条件记录 一.Truncate操作 从逻辑意义上来讲,trunca