python列表与列表算法详解(2)
目录
- 2. 案例【三酷猫冒泡法排序】
- 3. 案例【三酷猫二分法查找】
- 总结
1. 案例【三酷猫列表记账】
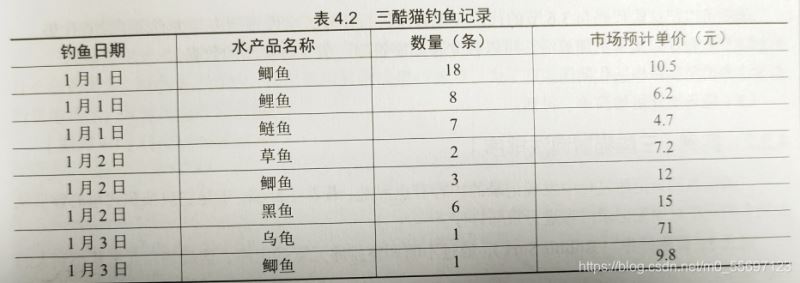
操作需求:
(1)用列表对象记录三酷猫每天钓鱼的种类和数量
(2)统计三酷猫所钓水产品的总数量和预计收获金额
(3)打印财务报表一张。
#三酷猫列表记账
nums = 0 #统计数量变量
amount = 0 #统计金额数量
i = 0 #循环控制变量
fish_record = ['1月1日','鲫鱼',18,10.5,'1月1日','鲤鱼',8,6.2,'1月1日','鲢鱼',7,4.7,'1月2日','草鱼',2,7.2,'1月2日','鲫鱼',3,12,'1月2日','黑鱼',6,15,'1月3日','乌龟',1,71,'1月3日','鲫鱼',1,9.8]
print('钓鱼日期名称数量单价(元)')
print('-'*30)
while i<len(fish_record):
nums = nums + fish_record[i+2] #累计数量
amount = amount + fish_record[i+2]*fish_record[i+3] #累计金额
print('%s,%s,%.2f,%.2f'%(fish_record[i],fish_record[i+1],fish_record[i+2],fish_record[i+3]))
i += 4 #循环控制
print('-'*30)
print(' 总数:%d,总金额%.2f元'%(nums,amount))
结果:

2. 案例【三酷猫冒泡法排序】
冒泡排序:通过不断调整排序元素的次序,实现集合元素从小到大的排序过程。
** 冒泡排序过程**
(1)取左边第一个元素,然后与后面的元素进行比较,若发现后面的元素比第一个元素小,则交换位置,继续往后比较,一直比较调整到最后一个元素,该元素为最大的元素。
(2)再取第一个元素,根据第一步一次比较、调整,直到倒数第二个停止;其他元素都依次循环比较、调整,每次循环多减一次,n-m(n为集合长度,m为每循环一次,增加一次,m从0 开始)。
(3)所有元素比较、调整完毕,完成集合元素增序排序。
冒泡法排序示意图

fish_records = [18,8,7,2,3,6,1,1]
i = 0 #循环控制变量
compare = 0 #比较元素初始值
fish_len = len(fish_records) #获取列表长度
while i<fish_len:
j = 1 #循环控制变量
while j<fish_len-i: #循环一遍,长度减1
if fish_records[j-1]>fish_records[j]: #比较前后两个元素的大小
compare = fish_records[j-1] #前一个大的放到临时比较变量里
fish_records[j-1] = fish_records[j] #把小的元素放到前面
fish_records[j] = compare #把临时变量里的大元素放到后面
j += 1 #内循环控制变量+1
i += 1 #外循环控制变量+1
print(fish_records)
结果:

3. 案例【三酷猫二分法查找】
二分法查找:指在有序集合里,对集合下标范围通过取中位法获取对应的元素值,进行叠代查找比较,直至找到所需要的元素。如set1[1…N],(1…N为集合元素下标顺序值)先取一个下标中位值K1= (1+N)/2,获取set1[K1]值与查找对象M进行比较。若set1[K1]等于M,则查找成功,返回查找位置;若set1[K1]小于M,则在[K+1,N]区间里再取中位值,进行查找比较;若set1[K1]大于M,则在[1,K-1]区间里再取中位值,进行查找比较。通过不断缩小查找区间范围,可以快速获取所需要查找的值。
fish_records = [1,1,2,3,6,7,8,18]
low = 0 #查找范围下界
high = len(fish_records)-1 #查找范围上界
find_value = 7 #要寻找的值
find_OK = False #是否找到标志,True为找到
i = 1
while low<=high:
middle = int((low+high)/2) #用int取整数,避免浮点数问题的发生
if find_value == fish_records[middle]: #找到时
find_OK = True #设置标志为True
break
elif find_value>fish_records[middle]: #没有找到,要找的值范围大于中位值时
low = middle+1 #范围在middle+1和high之间
elif find_value<fish_records[middle]: #没有找到,要找的值范围小于中间值时
high = middle-1 #范围在low和middle-1之间
i += 1
if find_OK:
print('%d在列表下标%d处,找了%d次。'%(find_value,middle,i))
else:
print('要找的数%d没有!找了%d次。'%(find_value,i))
结果:
代码运算示意图:

总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
python3操作redis实现List列表实例
目录 下面是具体例子详解和代码: ①lrange(key , start , stop) ②lpush(key , value) ③rpush(key , value) ④lpop(key) ⑤rpop(key) ⑥blpop(key) ⑦brpop(key) ⑧brpoplpush(source,destination,timeout) ⑨lindex(key,index) ⑩linsert(key,before|after,privot,value) ①①llen(key) ①②lpushx
-
python列表的特点分析
特点 1.一组有序的项目集合,可变的数据类型,可增删改查. 2.列表围绕方括号[]进行数据集合,不同成员以,分隔. 3.列表可以包含任何数据类型或另一个列表,不需要相同的类型. 4.列表可以通过序号访问成员. 实例 >>> list1=[1,2,3,4,5] >>> list1 [1, 2, 3, 4, 5] >>> list2=[12,"kkk",["12","bb"]] >>&
-
Python实现列表拼接和去重的三种方式
目录 列表拼接三种方式 方式一:简简单单的"+" 方法二:切片赋值 方式三:列表自带的extend() 列表去重的三种方式 利用集合set的特性 利用字典key的不可重复属性 利用index()获取到的是第一次出现的索引 列表拼接三种方式 列表拼接主要有以下三种方式: 最简单的使用"+"; 使用切片赋值的方法: 使用列表自带的extend方法 方式一:简简单单的"+" >>> list1 = [1,2,3] >>&g
-

Python内置数据结构列表与元组示例详解
目录 1. 序列 2. 列表 2.1 列表的特性 2.1.1 列表的连接操作符和重复操作符 2.1.3 列表的索引 2.1.4 列表的切片 2.1.5 列表的循环(for) 2.2 列表的基本操作(增删改查) 2.2.1 列表的增加 2.2.2 列表的修改 2.2.3 查看 2.2.4 列表的删除 2.2.5 其他操作 3. 元组 3.1 元组的创建 3.2 元组的特性 3.3 元组的命名 4. 深拷贝和浅拷贝 4.1 值的引用 4.2 浅拷贝 4.3 深拷贝 5. is 和 ==的对比 总结
-
python列表与列表算法详解
目录 1. 序列类型定义 2. 列表的基础知识 2.1 列表定义 2.2 列表基本操作 总结 1. 序列类型定义 序列是具有先后关系的一组元素 序列是一维元素向量,元素类型可以不同 类似数学运算序列:S0,S1,-,S(n-1) 元素间由序号引导,通过下表访问序列的特定元素 序列是一个基类类型 序列处理函数及方法 序列类型通用函数和方法 2. 列表的基础知识 2.1 列表定义 列表(list):是可变的序列型数据,也是一种可以存储各种数据类型的集合,用中括号([ ])表示列表的开始和结束,列表中
-
Python实现聚类K-means算法详解
目录 手动实现 sklearn库中的KMeans K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差 注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行. 下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现.数据我们采用<机器学习>的西瓜数据(P202表9.1): # 下面的内容保存在 melons.txt 中 # 第一列为西瓜的密度:第
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))
-
python查找与排序算法详解(示图+代码)
目录 查找 二分查找 线性查找 排序 插入排序 快速排序 选择排序 冒泡排序 归并排序 堆排序 计数排序 希尔排序 拓扑排序 总结 查找 二分查找 二分搜索是一种在有序数组中查找某一特定元素的搜索算法.搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束:如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较.如果在某一步骤数组为空,则代表找不到.这种搜索算法每一次比较都使搜索范围缩小一半. # 返回 x 在 ar
-
python实现感知器算法详解
在1943年,沃伦麦卡洛可与沃尔特皮茨提出了第一个脑神经元的抽象模型,简称麦卡洛可-皮茨神经元(McCullock-Pitts neuron)简称MCP,大脑神经元的结构如下图.麦卡洛可和皮茨将神经细胞描述为一个具备二进制输出的逻辑门.树突接收多个输入信号,当输入信号累加超过一定的值(阈值),就会产生一个输出信号.弗兰克罗森布拉特基于MCP神经元提出了第一个感知器学习算法,同时它还提出了一个自学习算法,此算法可以通过对输入信号和输出信号的学习,自动的获取到权重系数,通过输入信号与权重系数的乘积来
-
Python实现的快速排序算法详解
本文实例讲述了Python实现的快速排序算法.分享给大家供大家参考,具体如下: 快速排序基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 如序列[6,8,1,4,3,9],选择6作为基准数.从右向左扫描,寻找比基准数小的数字为3,交换6和3的位置,[3,8,1,4,6,9],接着从左向右扫描,寻找比基准数大的数字为8,交换6和8的位置
-
Python高级特性之切片迭代列表生成式及生成器详解
目录 切片 迭代 列表生成式 生成器 迭代器 在Python中,代码越少越好.越简单越好.基于这一思想,需要掌握Python中非常有用的高级特性,1行代码能实现的功能,决不写5行代码.代码越少,开发效率越高. 切片 tuple,list,字符串都可以进行切片操作 L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack'] L[0:3] # ['Michael', 'Sarah', 'Tracy'] L[:3] # ['Michael', 'Sarah', '
-
对Python 3.5拼接列表的新语法详解
在Python 3.5之前的版本,拼接列表可以有这两种方法: 1.列表相加 list1 = [1,2,3] list2 = [4,5,6] result = list1 + list2 结果为一个新的列表 2.在原来列表上扩展 list1 = [1,2,3] list2 = [4,5,6] list1.extend(list2) list1扩展后,结果为[1,2,3,4,5,6] 3.新语法 如果列表是由range()生成: list1 = [1,2,3] list2 = range(4,6)
-
python列表切片和嵌套列表取值操作详解
给出列表切片的格式: [开头元素::步长] # 输出直到最后一个元素,(最后一个冒号和步长可以省略,下同) [开头元素:结尾元素(不含):步长] # 其中,-1表示list最后一个元素 首先来看最简单的单一列表: a = [1,2,3,4] a[:] a[::] a[:3] a[1:3:2] a[3] 输出依次为: [1,2,3,4] [1,2,3,4] [1,2,3] [2] 4 注意,这里只有最后一个输出是不带[]的,表明只有最后一个输出是元素,其他在切片中只用了:符号的输出均为list,不
-
Python列表常用函数使用详解
目录 介绍 append() extend() insert() pop() remove() 介绍 append() 语法 list.append( element ) 参数 element:任何类型的元素 列表「末尾」添加元素 name_list = ['zhangsan', 'lisi', 'wangwu'] name_list.append('zhaoliu') print(name_list) 输出: ['zhangsan', 'lisi', 'wangwu', 'zhaoliu'
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat