详解如何用Python模拟登录淘宝
目录
- 一、淘宝登录流程
- 二、模拟登录实现
- 1.判断是否需要验证码
- 2.验证用户名密码
- 3.申请st码
- 4.使用st码登录
- 5.获取淘宝昵称
- 三、总结
- 1.代码结构
- 2.存在问题
看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy、pyppeteer、selenium等库来模拟登录,但是目前我们还没有讲到这些库,只讲了requests库,那我们今天就来使用requests库模拟登录淘宝!
讲模拟登录淘宝之前,我们来回顾一下之前用requests库模拟登录豆瓣和新浪微博的过程:这一类模拟登录是比较简单的登录,只需要在请求登录时将用户名和密码上传验证通过就成功了,也就是说一步到位!
而淘宝登录就比较复杂,为什么说复杂呢?因为淘宝登录涉及参数多且请求不止一次!我们就先来讲讲淘宝登录的流程,先把流程原理搞懂,再去敲代码,这样大家就容易理解!
一、淘宝登录流程

淘宝ua参数:ua(User-Agent)故名用户代理,淘宝的ua参数加入了浏览器、ip、电脑、时间等信息,然后加密生成,在很多地方使用,不仅仅是登录!
上图是比较详细的流程图,从代码层面考虑将模拟登录淘宝分为以下四个步骤:
输入用户名后,浏览器会向淘宝(taobao.com)发起一个post的请求,判断是否出现滑块验证!
用户输入密码后,浏览器向淘宝(taobao.com)又发起一个post请求,验证用户名密码是否正确,如果正确则返回一个token。
浏览器拿着token去阿里巴巴(alibaba.com)交换st码!
浏览器获取st码之后,拿着st码获取cookies,登录成功
这里也许有同学会提出疑问:为什么淘宝(taobao.com)验证通过之后还要拿着 token去阿里巴巴(alibaba.com)交换st码呢? 这个我们放后面讲!
二、模拟登录实现
上面我们只讲了大概的登录流程,这里猪哥会先详细讲解下每一步的操作,然后再贴出实现代码!
1.判断是否需要验证码
目前我们在登录淘宝的时候,大多数情况下是不会出现滑块验证码,猪哥尝试了很多次的登录退出也只是在中间出现过一次,那究竟是什么在控制是否需要滑块验证码的呢?

从上图可以看出,当猪哥输入用户名(必须是手机号)后,浏览器就会发起一个post请求,来验证是否需要出现滑块验证码,如果返回true,滑块验证码则出现!否则不出现,一般是不会出现!
图中我们可以看到这次post请求上传了两个参数:username、ua!
前面猪哥说过ua为浏览器、ip、设备信息等多信息加密参数,所以猪哥猜想淘宝的验证码是否出现不仅仅从账号角度,还有ip、设备等角度!
举个例子:某台设备可能出现登录过大量的账号,这时候淘宝就可以从ua参数中获取设备号,然后对该设备进行限制!
2.验证用户名密码
这里一步也就是上面时序图图中的第5步:请求登录,这里会将用户名、ua参数、加密密码等30十几个参数post到淘宝(taobao.com)去验证。我们来用代码实现一下,大家别被这么多参数吓到,都是从浏览器复制过来的!
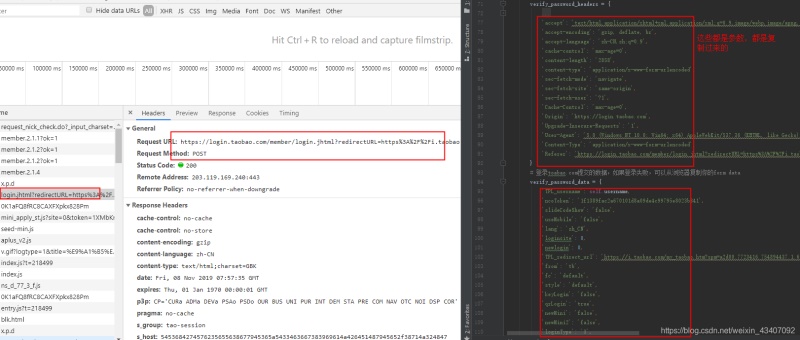
可以看到申请st码链接后面带了一个token,具体token是干什么用的后面我们再分析!
3.申请st码
上面我们已经申请到了淘宝(taobao.com)的token,这一步就是用token来换取st码。
到这里很多人可能会有疑问:为什么淘宝登录需要这么麻烦呢?直接在 taobao.com 登录不就可以吗?为什么要先在taobao验证用户名密码,通过之后再去 alibaba.com 换取st码登录呢?
任何公司的框架都是慢慢演变的结果,我想最开始的淘宝登录肯定没这么复杂。但是随着阿里巴巴的慢慢壮大,很多事业线都划分开来,但是这些事业线之间又有关联性,比如用户登录了淘宝账号之后天猫就不需要再登录了呢?(注意淘宝和天猫的顶级域名不同,所以不能共享cookis)为了解决这个问题,单点登录就出现了。
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。 ——百度百科
很多大企业几乎都有做单点登录,那阿里的单点登录系统肯定是由母公司阿里巴巴(alibaba.com)来做啦,所有子公司去调用母公司接口!
我们再回来分析淘宝登录为何要如此复杂就很好理解了:用户数据在淘宝这里,所以需要现在淘宝(taobao.com)验证用户名和密码,验证通过生成一个token,浏览器拿着token去和阿里巴巴(alibaba.com)申请单点登录码(st码),阿里巴巴收到请求验证token通过则返回st码,所以用token换st码的原因就在于单点登录!
理解了设计原理之后,代码实现起来就很清晰了!

4.使用st码登录
成功获取st码之后我们就可以来登录了,这一步是通过st码获取登录的cookies。
到这里我们就已经模拟登录淘宝成功了!
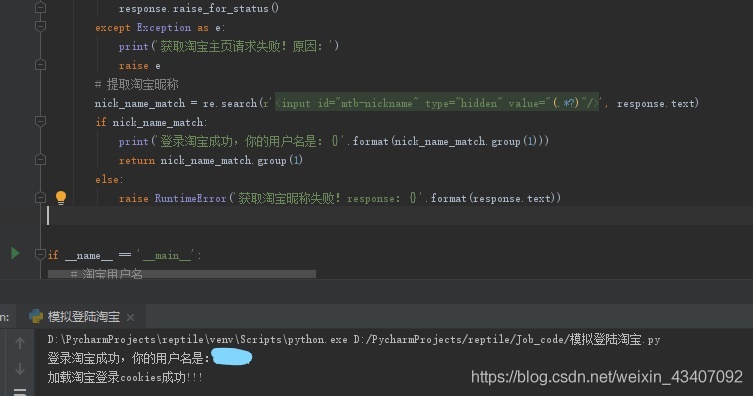
5.获取淘宝昵称
其实上面我们就已经登录淘宝成功并返回用户主页的链接,我们为了进一步验证登录成功,就请求一下淘宝用户主页,顺便把淘宝昵称提取出来吧!
三、总结
整体讲完之后我们来稍微总结一下吧,主要从代码结构和存在的问题两个方面说下:
1.代码结构
来放出一张代码结构图,让大家直观了解
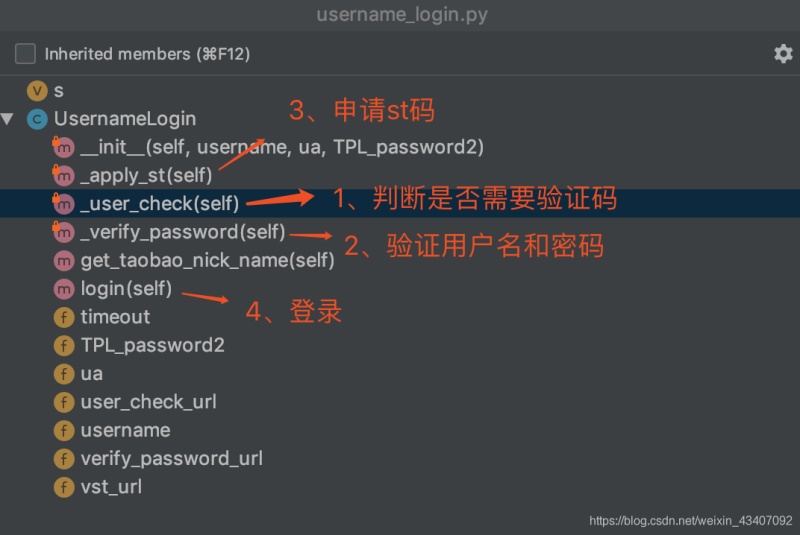
这就是我们前面说过的模拟登录淘宝的四个步骤,不过这里我们是用代码实现了!
2.存在问题
在写这篇教程之前也是先在网上了解,然后自己用浏览器和抓包工具(Charles)一步一步实践,最重要的是你先要了解淘宝登录的大概流程,不然你实际操作起来会一头雾水,下面就要讲讲目前遇到的问题和存在的问题吧
首先第一个问题便是淘宝的滑块解锁,目前requests还没有很好的破解办法,后面介绍了一些爬虫框架之后我们再来破解吧!
猪哥尝试了很多次(50次以上)登录退出都没出现过滑块验证码。
网上有人使用代理ip,这里猪哥也没用,只要你不是超级超级超级频繁且大量爬取数据,一般大厂都不太会去封ip,因为有误伤率和影响用户面太广,也许一封就是整个小区。
在第二步验证用户名和密码时,上传了近30个参数,如果你把username、ua、加密密码复制进去验证还是不通过可尝试把那30个参数换成你浏览器中的!
在第三步和第四步偶尔会出现一次错误,重试一下就可以!
看到这里是不是感觉淘宝模拟登录就清晰明了很多了,感兴趣的同学可以收藏转发,周末有空自己尝试一下。征服淘宝登录,其他登录也就相对简单了!
下面是源码
# -*- coding:utf-8 -*-
import re
import os
import json
import requests
s = requests.Session()
# cookies序列化文件
COOKIES_FILE_PATH = 'taobao_login_cookies.txt'
class UsernameLogin:
def __init__(self, username, ua, TPL_password2):
"""
账号登录对象
:param username: 用户名
:param ua: 淘宝的ua参数
:param TPL_password2: 加密后的密码
"""
# 检测是否需要验证码的URL
self.user_check_url = 'https://login.taobao.com/member/request_nick_check.do?_input_charset=utf-8'
# 验证淘宝用户名密码URL
self.verify_password_url = "https://login.taobao.com/member/login.jhtml"
# 访问st码URL
self.vst_url = 'https://login.taobao.com/member/vst.htm?st={}'
# 淘宝个人 主页
self.my_taobao_url = 'https://i.taobao.com/my_taobao.htm'
# 淘宝用户名
self.username = "手机号"
# 淘宝关键参数,包含用户浏览器等一些信息,很多地方会使用,从浏览器或抓包工具中复制,可重复使用
self.ua = ""
# 加密后的密码,从浏览器或抓包工具中复制,可重复使用
self.TPL_password2 = ""
# 请求超时时间
self.timeout = 3
def _user_check(self):
"""
检测账号是否需要验证码
:return:
"""
data = {
'username': self.username,
'ua': self.ua
}
try:
response = s.post(self.user_check_url, data=data, timeout=self.timeout)
response.raise_for_status()
except Exception as e:
print('检测是否需要验证码请求失败,原因:')
raise e
needcode = response.json()['needcode']
print('是否需要滑块验证:{}'.format(needcode))
return needcode
def _verify_password(self):
"""
验证用户名密码,并获取st码申请URL
:return: 验证成功返回st码申请地址
"""
verify_password_headers = {
redirectURL=https%3A%2F%2Fi.taobao.com%2Fmy_taobao.htm%3Fspm%3Da2d00.7723416.754894437.1.61531fc917M0p9%26ad_id%3D%26am_id%3D%26cm_id%3D%26pm_id%3D1501036000a02c5c3739',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'content-length': '2858',
'content-type': 'application/x-www-form-urlencoded',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'Cache-Control': 'max-age=0',
'Origin': 'https://login.taobao.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': 'https://login.taobao.com/member/login.jhtml?redirectURL=https%3A%2F%2Fi.taobao.com%2Fmy_taobao.htm%3Fspm%3Da2d00.7723416.754894437.1.61531fc917M0p9%26ad_id%3D%26am_id%3D%26cm_id%3D%26pm_id%3D1501036000a02c5c3739',
}
# 登录toabao.com提交的数据,如果登录失败,可以从浏览器复制你的form data
verify_password_data = {
'TPL_username': self.username,
'ncoToken': '1f1389fac2a670101d8a09de4c99795e8023b341',
'slideCodeShow': 'false',
'useMobile': 'false',
'lang': 'zh_CN',
'loginsite': 0,
'newlogin': 0,
'TPL_redirect_url': 'https://i.taobao.com/my_taobao.htm?spm=a2d00.7723416.754894437.1.61531fc917M0p9&ad_id=&am_id=&cm_id=&pm_id=1501036000a02c5c3739',
'from': 'tb',
'fc': 'default',
'style': 'default',
'keyLogin': 'false',
'qrLogin': 'true',
'newMini': 'false',
'newMini2': 'false',
'loginType': '3',
'gvfdcname': '10',
# 'gvfdcre': '68747470733A2F2F6C6F67696E2E74616F62616F2E636F6D2F6D656D6265722F6C6F676F75742E6A68746D6C3F73706D3D613231626F2E323031372E3735343839343433372E372E356166393131643970714B52693126663D746F70266F75743D7472756526726564697265637455524C3D68747470732533412532462532467777772E74616F62616F2E636F6D253246',
'TPL_password_2': self.TPL_password2,
'loginASR': '1',
'loginASRSuc': '1',
'oslanguage': 'zh-CN',
'sr': '1920*1080',
# 'osVer': 'macos|10.145',
'naviVer': 'chrome|78.039047',
'osACN': 'Mozilla',
'osAV': '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'osPF': 'Win32',
'appkey': '00000000',
'mobileLoginLink': 'https://login.taobao.com/member/login.jhtml?redirectURL=https://i.taobao.com/my_taobao.htm?spm=a2d00.7723416.754894437.1.61531fc917M0p9&ad_id=&am_id=&cm_id=&pm_id=1501036000a02c5c3739&useMobile=true',
'showAssistantLink': 'false',
'um_token': 'T274D86E0BEB4F2F2F527C889BADD92868CE10177BeFF895DE627CFE2D52A',
'ua': self.ua
}
try:
response = s.post(self.verify_password_url, headers=verify_password_headers, data=verify_password_data,
timeout=self.timeout)
response.raise_for_status()
# 从返回的页面中提取申请st码地址
except Exception as e:
print('验证用户名和密码请求失败,原因:')
raise e
# 提取申请st码url
apply_st_url_match = re.search(r'<script src="(.*?)"></script>', response.text)
# 存在则返回
if apply_st_url_match:
print('验证用户名密码成功,st码申请地址:{}'.format(apply_st_url_match.group(1)))
return apply_st_url_match.group(1)
else:
raise RuntimeError('用户名密码验证失败!response:{}'.format(response.text))
def _apply_st(self):
"""
申请st码
:return: st码
"""
apply_st_url = self._verify_password()
try:
response = s.get(apply_st_url)
# response.raise_for_status()
except Exception as e:
print('申请st码请求失败,原因:')
raise e
st_match = re.search(r'"data":{"st":"(.*?)"}', response.text)
if st_match:
print('获取st码成功,st码:{}'.format(st_match.group(1)))
return st_match.group(1)
else:
raise RuntimeError('获取st码失败!response:{}'.format(response.text))
# raise RuntimeError('获取st码失败!')
def login(self):
"""
使用st码登录
:return:
"""
# 加载cookies文件
if self._load_cookies():
return True
# 判断是否需要滑块验证
self._user_check()
st = self._apply_st()
headers = {
'Host': 'login.taobao.com',
'Connection': 'Keep-Alive',
'User-Agent': '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
try:
response = s.get(self.vst_url.format(st), headers=headers)
response.raise_for_status()
except Exception as e:
print('st码登录请求,原因:')
raise e
# 登录成功,提取跳转淘宝用户主页url
my_taobao_match = re.search(r'top.location.href = "(.*?)"', response.text)
if my_taobao_match:
print('登录淘宝成功,跳转链接:{}'.format(my_taobao_match.group(1)))
self._serialization_cookies()
return True
else:
raise RuntimeError('登录失败!response:{}'.format(response.text))
def _load_cookies(self):
# 1、判断cookies序列化文件是否存在
if not os.path.exists(COOKIES_FILE_PATH):
return False
# 2、加载cookies
s.cookies = self._deserialization_cookies()
# 3、判断cookies是否过期
try:
self.get_taobao_nick_name()
except Exception as e:
os.remove(COOKIES_FILE_PATH)
print('cookies过期,删除cookies文件!')
return False
print('加载淘宝登录cookies成功!!!')
return True
def _serialization_cookies(self):
"""
序列化cookies
:return:
"""
cookies_dict = requests.utils.dict_from_cookiejar(s.cookies)
with open(COOKIES_FILE_PATH, 'w+', encoding='utf-8') as file:
json.dump(cookies_dict, file)
print('保存cookies文件成功!')
def _deserialization_cookies(self):
"""
反序列化cookies
:return:
"""
with open(COOKIES_FILE_PATH, 'r+', encoding='utf-8') as file:
cookies_dict = json.load(file)
cookies = requests.utils.cookiejar_from_dict(cookies_dict)
return cookies
def get_taobao_nick_name(self):
"""
获取淘宝昵称
:return: 淘宝昵称
"""
headers = {
'User-Agent': '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
try:
response = s.get(self.my_taobao_url, headers=headers)
response.raise_for_status()
except Exception as e:
print('获取淘宝主页请求失败!原因:')
raise e
# 提取淘宝昵称
nick_name_match = re.search(r'<input id="mtb-nickname" type="hidden" value="(.*?)"/>', response.text)
if nick_name_match:
print('登录淘宝成功,你的用户名是:{}'.format(nick_name_match.group(1)))
return nick_name_match.group(1)
else:
raise RuntimeError('获取淘宝昵称失败!response:{}'.format(response.text))
if __name__ == '__main__':
# 淘宝用户名
username = '手机号'
# 淘宝重要参数,从浏览器或抓包工具中复制,可重复使用
ua = ''
# 加密后的密码,从浏览器或抓包工具中复制,可重复使用
TPL_password2 = ''
ul = UsernameLogin(username, ua, TPL_password2)
ul.login()
到此这篇关于详解如何用Python模拟登录淘宝的文章就介绍到这了,更多相关Python模拟登录淘宝内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解python项目实战:模拟登陆CSDN
前言 今天为大家介绍一个利用Python模拟登陆CSDN的案例,虽然看起来很鸡肋,有时候确会有大用处,在这里就当做是一个案例练习吧,提高自己的代码水平,也了解Python如何做到模拟登陆的, 下面来看代码 导入库 获取头部信息 解析网页 返回登录过后的session 检测是否登陆正常 运行结果 以上所述是小编给大家介绍的python项目实战:模拟登陆CSDN详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
python模拟登陆,用session维持回话的实例
python模拟登陆的几种方法 客户端向服务器发送请求,cookie则是表明我们身份的标志.而"访问登录后才能看到的页面"这一行为,恰恰需要客户端向服务器证明:"我是刚才登录过的那个客户端".于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态) 1.先在浏览器中登录,然后打开开发者选项,找到一个请求方法为POST的请求,复制Requests Headers中的cookie在爬取需要登录的页面时加上此cookies即可 import requests
-

python 模拟登陆github的示例
# -*- coding: utf-8 -*- # @Author: CriseLYJ # @Date: 2020-08-14 12:13:11 import re import requests class GithubLogin(object): def __init__(self, email, password): # 初始化信息 self.headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2)
-
python模拟登陆网站的示例
使用已有cookie登陆 使用浏览器登陆,获取浏览器中的cookie信息,来进行登陆. 我们以博客园为例,先登录博客园账号.我们访问随笔列表,在控制台我们可以看到我们登陆后浏览器的cookie 剔除一些数据统计及分析的cookie,剩下的就是登陆可能需要的.CNBlogsCookie和.Cnblogs.AspNetCore.Cookies # _ga google分析 cookie # UM_distinctid 友盟cookie # CNZZxxx CNZZcookie # __utma,__
-
selenium携带cookies模拟登陆CSDN的实现
首先是获取cookies保存到本地 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/12/20 11:00 # @Author : huni # @File : cookies获取.py # @Software: PyCharm from selenium import webdriver from time import sleep import json if __name__ == '__main__': drive
-
python requests模拟登陆github的实现方法
1. Cookie 介绍 HTTP 协议是无状态的.因此,若不借助其他手段,远程的服务器就无法知道以前和客户端做了哪些通信.Cookie 就是「其他手段」之一. Cookie 一个典型的应用场景,就是用于记录用户在网站上的登录状态. 用户登录成功后,服务器下发一个(通常是加密了的)Cookie 文件. 客户端(通常是网页浏览器)将收到的 Cookie 文件保存起来. 下次客户端与服务器连接时,将 Cookie 文件发送给服务器,由服务器校验其含义,恢复登录状态(从而避免再次登录). 2.requ
-
详解如何用Python模拟登录淘宝
目录 一.淘宝登录流程 二.模拟登录实现 1.判断是否需要验证码 2.验证用户名密码 3.申请st码 4.使用st码登录 5.获取淘宝昵称 三.总结 1.代码结构 2.存在问题 看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy.pyppeteer.selenium等库来模拟登录,但是目前我们还没有讲到这些库,只讲了requests库,那我们今天就来使用requests库模拟登录淘宝! 讲模拟登录淘宝之前,我们来回顾一下之前用requests库模拟登录豆瓣和新浪微博的过程:这一类模拟
-
详解如何用Python登录豆瓣并爬取影评
目录 一.需求背景 二.功能描述 三.技术方案 四.登录豆瓣 1.分析豆瓣登录接口 2.代码实现登录豆瓣 3.保存会话状态 4.这个Session对象是我们常说的session吗? 五.爬取影评 1.分析豆瓣影评接口 2.爬取一条影评数据 3.影评内容提取 4.批量爬取 六.分析影评 1.使用结巴分词 七.总结 上一篇我们讲过Cookie相关的知识,了解到Cookie是为了交互式web而诞生的,它主要用于以下三个方面: 会话状态管理(如用户登录状态.购物车.游戏分数或其它需要记录的信息) 个性化
-
python使用sessions模拟登录淘宝的方式
之前想爬取一些淘宝的数据,后来发现需要登录,找了很多的资料,有个使用request的sessions加上cookie来登录的,cookie的获取在登录后使用开发者工具可以找到.不过这个登录后获得的网页的代码是静态的,获取动态网页还得另寻他法,一般需要的数据可以在网页的源码中得到,但是你知道的,有些动态加载的就不是那么简单了,而且我发现这样获得的源码中,有些想要获取的数据的格式是经过改动的,比如我要某个商品的具体链接,发现并不能直接使用. 总体而言,这是一次失败的尝试,不过倒是了解到使用sessi
-
详解如何用Python实现感知器算法
目录 一.题目 二.数学求解过程 三.感知器算法原理及步骤 四.python代码实现及结果 一.题目 二.数学求解过程 该轮迭代分类结果全部正确,判别函数为g(x)=-2x1+1 三.感知器算法原理及步骤 四.python代码实现及结果 (1)由数学求解过程可知: (2)程序运行结果 (3)绘图结果 ''' 20210610 Julyer 感知器 ''' import numpy as np import matplotlib.pyplot as plt def get_zgxl(xn, a):
-
详解如何用Python写个听小说的爬虫
目录 书名和章节列表 音频地址 下载 完整代码 总结 在路上发现好多人都喜欢用耳机听小说,同事居然可以一整天的带着一只耳机听小说.小编表示非常的震惊.今天就用 Python 下载听小说 tingchina.com的音频. 书名和章节列表 随机点开一本书,这个页面可以使用 BeautifulSoup 获取书名和所有单个章节音频的列表.复制浏览器的地址,如:https://www.tingchina.com/yousheng/disp_31086.htm. from bs4 import Beaut
-
Python 自动登录淘宝并保存登录信息的方法
前段时间时间为大家讲解了如何使用requests库模拟登录淘宝,而今天我们将对该功能进行丰富.所以我们把之前的那个版本定为1.0,而今天修改的版本定为2.0.版本的迭代意味着功能的升级,那今天的2.0版本较之前的1.0版本有哪些改进呢?我们一起来看看! 1.0版本实现步骤 我们先来回顾一下模拟登录淘宝的步骤吧,我们还是先看看淘宝登录的详细时序图: 这是淘宝网登录的一个请求流程,而我们模拟登录也是根据这样的一个流程.但是在代码模拟登录的时候就不会分的这么细,我们根据封装的思想将整个登录流程封装在四
-
selenium跳过webdriver检测并模拟登录淘宝
简介 模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网站的升级,采取该策略比较难实现了.因为你使用get/post方式进行爬取数据,会提示需要登录,而登录又是一大难题,需要滑动验证码验证.当你想使用IP代理池进行跳过检验时,发现登录时需要手机短信验证码验证,由此可以知道旧的全自动爬取数据对于大型网站比较困难了. selenium是一款优秀的WEB自动化测试工具,所以现在采用selenium进行半自动化爬取数据,支持模
-
Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享
支付宝十年账单上的数字有点吓人,但它统计的项目太多,只是想看看到底单纯在淘宝上支出了多少,于是写了段脚本,统计任意时间段淘宝订单的消费情况,看那结果其实在淘宝上我还是相当节约的说. 脚本的主要工作是模拟了浏览器登录,解析"已买到的宝贝"页面以获得指定的订单及宝贝信息. 使用方法见代码或执行命令加参数-h,另外需要BeautifulSoup4支持,BeautifulSoup的官方项目列表页:https://www.crummy.com/software/BeautifulSoup/bs4
-
详解npm 配置项registry修改为淘宝镜像
在使用npm 的过程中,搜索网上的资料基本上可以看到类似如下的描述:"npm是国外的,使用起来比较慢,我们这里使用淘宝的cnpm镜像".初体验,不知道淘宝cnpm镜像为何物.根据这句描述,我们应该可以理解有2件事要做: 1:找到淘宝的镜像地址: 2:更改当前npm所使用的下载包服务器地址: 打开https://npm.taobao.org/ 上面的地址太多,根本不知道那个是我可以用的地址: 百度看了一下,例如执行下面的指令就可以使用cnpm利用国内镜像服务了: npm install
-
详解如何用python实现一个简单下载器的服务端和客户端
话不多说,先看代码: 客户端: import socket def main(): #creat: download_client=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #link: serv_ip=input("please input server IP") serv_port=int(input(("please input server port"))) serv_addr=(serv_ip,ser