java编程实现简单的网络爬虫示例过程
本项目中需要用到两个第三方jar包,分别为 jsoup 和 commons-io。
jsoup的作用是为了解析网页, commons-io 是为了把数据保存到本地。
1.爬取贴吧
第一步,打开eclipse,新建一个java项目,名字就叫做 pachong:

然后,新建一个类,作为我们程序的入口。
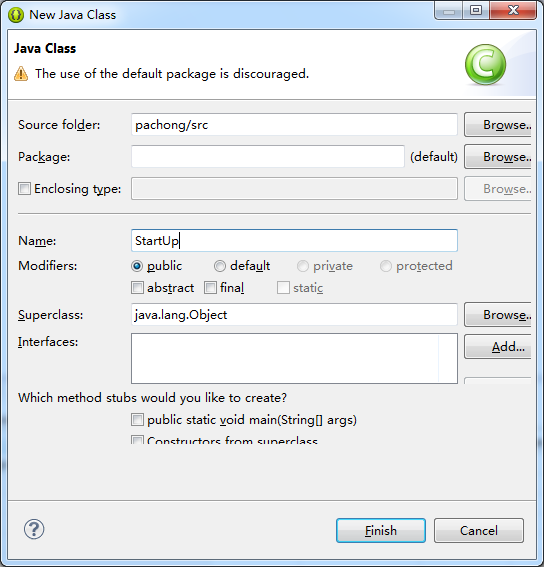
这个作为入口类,里面就写一个main方法即可。
public class StartUp {
public static void main(String[] args) {
}
}
第二步,导入我们的依赖,两个jar包:

右键jar包,Build path , add to Build path
接着,我们试着搜索一下动漫吧的数据:
https://tieba.baidu.com/f?kw=%B6%AF%C2%FE&tpl=5
public class StartUp {
public static void main(String[] args) {
String url = "https://tieba.baidu.com/f?kw=%B6%AF%C2%FE&tpl=5";
Connection connect = Jsoup.connect(url);
System.out.println(connect);
}
}
如果能够成功打印出来链接,说明我们的连接测试是成功的!

然后,我们调用connect的get方法,获取链接到的数据:
Document document = connect.get();

这边需要抛出一个异常,而且是强制性的,因为有可能会获取失败。这边我们直接抛出去,不去捕获。
public class StartUp {
public static void main(String[] args) throws IOException {
String url = "https://tieba.baidu.com/f?kw=%B6%AF%C2%FE&tpl=5";
Connection connect = Jsoup.connect(url);
System.out.println(connect);
Document document = connect.get();
System.out.println(document);
}
}
打印出来的结果:

可见,document对象装的就是一个完整HTML页面。
在这里,我们想要拿到的第一个数据,就是所有帖子的标题:
我们发现,每一个标题都是一个a连接,class为j_th_tit 。
下一步我们就考虑获取所有class为 j_th_tit 的元素。

我们发现,document对象给我们提供了 getElementsByClass 的方法,顾名思义,就是获取class为 XXX 的元素。
Elements titles = document.getElementsByClass("j_th_tit");
接着,遍历titles,打印出每一个标题的名称:
for (int i = 0; i < titles.size(); i++) {
System.out.println(titles.get(i).attr("title"));
}
当前代码:
import java.io.IOException;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class StartUp {
public static void main(String[] args) throws IOException {
String url = "https://tieba.baidu.com/f?kw=%B6%AF%C2%FE&tpl=5";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
Elements titles = document.getElementsByClass("j_th_tit");
for (int i = 0; i < titles.size(); i++) {
System.out.println(titles.get(i).attr("title"));
}
}
}
以上就是java编程实现简单的网络爬虫示例过程的详细内容,更多关于java实现网络爬虫的资料请关注我们其它相关文章!
相关推荐
-
Java 实现网络爬虫框架详细代码
目录 Java 实现网络爬虫框架 一.每个类的功能介绍 二.每个类的源代码 Java 实现网络爬虫框架 最近在做一个搜索相关的项目,需要爬取网络上的一些链接存储到索引库中,虽然有很多开源的强大的爬虫框架,但本着学习的态度,自己写了一个简单的网络爬虫,以便了解其中的原理.今天,就为小伙伴们分享下这个简单的爬虫程序!! 一.每个类的功能介绍 DownloadPage.java的功能是下载此超链接的页面源代码. FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式
-
半小时实现Java手撸网络爬虫框架(附完整源码)
最近在做一个搜索相关的项目,需要爬取网络上的一些链接存储到索引库中,虽然有很多开源的强大的爬虫框架,但本着学习的态度,自己写了一个简单的网络爬虫,以便了解其中的原理.今天,就为小伙伴们分享下这个简单的爬虫程序!! 首先介绍每个类的功能: DownloadPage.java的功能是下载此超链接的页面源代码. FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式匹配,获取URL链接的元素,判断是否创建文件,获取页面的Url并将其转换为规范的Url,截取网页网页源
-

Java爬虫范例之使用Htmlunit爬取学校教务网课程表信息
使用WebClient和htmlunit实现简易爬虫 import com.gargoylesoftware.htmlunit.WebClient; 提供了public P getPage(final String url)方法获得HtmlPage. import com.gargoylesoftware.htmlunit.html.*; 包含了HtmlPage.HtmlForm.HtmlTextInput.HtmlPasswordInput.HtmlElement.DomElement等元素.
-
Java 使用maven实现Jsoup简单爬虫案例详解
一.Jsoup的简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 二.我们可以利用Jsoup做什么 2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据, 2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本 2.3从而使我们输出我们想要的整洁文本 三.利用Jsoup爬
-
JAVA使用HtmlUnit爬虫工具模拟登陆CSDN案例
最近要弄一个爬虫程序,想着先来个简单的模拟登陆, 在权衡JxBrowser和HtmlUnit 两种技术, JxBowser有界面呈现效果,但是对于某些js跳转之后的效果获取比较繁琐. 随后考虑用HtmlUnit, 想着借用咱们CSND的登陆练练手.谁知道CSDN的登陆,js加载时间超长,不设置长一点的加载时间,按钮提交根本没效果,js没生效. 具体看代码注释吧. 奉劝做爬虫的同志们,千万别用CSDN登陆练手,坑死我了. maven配置如下: <dependencies> <!-- ht
-
Java中用爬虫进行解析的实例方法
我们都知道可以用爬虫来找寻一些想要的数据,除了可以使用python进行操作,我们最近学习的java同样也支持爬虫的运行,本篇小编就教大家用java爬虫来进行网页的解析,具体内容请往下看: 1.springboot项目,引入jsoup <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version&g
-
java能写爬虫程序吗
我们经常会使用网络爬虫去爬取需要的内容,提到爬虫,可能大家伙都会想到python,其实除了python,还有java.java的编程语言简单规范,是很好的爬虫工具.而且java爬虫的语言运行速度比python快,另外,java的多线程是可以利用多核的. 1.java为什么可以应用于网络爬虫? java语法比较规则,采用严格的面向对象编程方法: Java是Android开发的基石, 是Web开发的主流语言: 具有很好的扩展性可伸缩性,其是目前搜索引擎开发的重要组成部分: java爬虫的语言运行速度
-
java编程实现简单的网络爬虫示例过程
本项目中需要用到两个第三方jar包,分别为 jsoup 和 commons-io. jsoup的作用是为了解析网页, commons-io 是为了把数据保存到本地. 1.爬取贴吧 第一步,打开eclipse,新建一个java项目,名字就叫做 pachong: 然后,新建一个类,作为我们程序的入口. 这个作为入口类,里面就写一个main方法即可. public class StartUp { public static void main(String[] args) { } } 第二步,导入我们
-
java实现一个简单的网络爬虫代码示例
目前市面上流行的爬虫以python居多,简单了解之后,觉得简单的一些页面的爬虫,主要就是去解析目标页面(html).那么就在想,java有没有用户方便解析html页面呢?找到了一个jsoup包,一个非常方便解析html的工具呢. 使用方式也非常简单,引入jar包: <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.8.
-
hadoop中实现java网络爬虫(示例讲解)
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 Cygwin:一个在windows平台上运行的类UNIX模拟环境,直接网上搜索下载,并且安装: Hadoop:配置Hadoop环境,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,用来将收集的数据直接上传保存到HDFS,然后用MapReduce
-
Java编程异常简单代码示例
练习1 写一个方法void triangle(int a,int b,int c),判断三个参数是否能构成一个三角形.如果不能则抛出异常IllegalArgumentException,显示异常信息:a,b,c "不能构成三角形":如果可以构成则显示三角形三个边长.在主方法中得到命令行输入的三个整数,调用此方法,并捕获异常. 两边之和大于第三边:a+b>c 两边之差小于第三边:c-a package 异常; import java.util.Arrays; import java
-
Python3.4编程实现简单抓取爬虫功能示例
本文实例讲述了Python3.4编程实现简单抓取爬虫功能.分享给大家供大家参考,具体如下: import urllib.request import urllib.parse import re import urllib.request,urllib.parse,http.cookiejar import time def getHtml(url): cj=http.cookiejar.CookieJar() opener=urllib.request.build_opener(urllib.
-
Android编写简单的网络爬虫
一.网络爬虫的基本知识 网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念.爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的连接看做是有向边.图的遍历方式分为宽度遍历和深度遍历,但是深度遍历可能会在深度上过深的遍历或者陷入黑洞.所以,大多数爬虫不采用这种形式.另一方面,爬虫在按照宽度优先遍历的方式时候,会给待遍历的网页赋予一定优先级,这种叫做带偏好的遍历. 实际的爬虫是从一系列的种子链接开始.种子链接是起始节点,种子页面的超链接指向的页面是
-
Java编程redisson实现分布式锁代码示例
最近由于工作很忙,很长时间没有更新博客了,今天为大家带来一篇有关Redisson实现分布式锁的文章,好了,不多说了,直接进入主题. 1. 可重入锁(Reentrant Lock) Redisson的分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口,同时还支持自动过期解锁. public void testReentrantLock(RedissonClient redisson){ RLock lock = redisson.getL
-
Java编程实现逆波兰表达式代码示例
逆波兰表达式 定义:传统的四则运算被称作是中缀表达式,即运算符实在两个运算对象之间的.逆波兰表达式被称作是后缀表达式,表达式实在运算对象的后面. 逆波兰表达式: a+b ---> a,b,+ a+(b-c) ---> a,b,c,-,+ a+(b-c)*d ---> a,b,c,-,d,*,+ a+d*(b-c)--->a,d,b,c,-,*,+ a=1+3 ---> a=1,3 + http=(smtp+http+telnet)/1024 写成什么呢? http=smtp,
-
Java编程使用卡片布局管理器示例【基于swing组件】
本文实例讲述了Java编程使用卡片布局管理器.分享给大家供大家参考,具体如下: 运行效果: 完整示例代码: package com.han; import java.awt.BorderLayout; import java.awt.CardLayout; import java.awt.Container; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import javax.swing.JB
-
Node.js 利用cheerio制作简单的网页爬虫示例
本文介绍了Node.js 利用cheerio制作简单的网页爬虫示例,分享给大家,具有如下: 1. 目标 完成对网站的标题信息获取 将获取到的信息输出在一个新文件 工具: cheerio,使用npm下载npm install cheerio cheerio的API使用方法和jQuery的使用方法基本一致 如果熟练使用jQuery,那么cheerio将会很快上手 2. 代码部分 介绍: 获取segment fault页面的列表标题,将获取到的标题列表编号,最终输出到pageTitle.txt文件里