springboot+spring data jpa实现新增及批量新增方式
目录
- springboot+spring data jpa实现新增及批量新增
- springdatajpa 新增操作注意
springboot+spring data jpa实现新增及批量新增
spring data jpa (以下简称jpa)。这个orm其实和mybatis还是差不多的。但是相对于mybatis来说,省去很多方法,毕竟jpa来说,官方文档给的说法是编写者只需要书写接口。剩下的事就交由jpa来完成。当时,洒家还是不信的。当你用过一次后,你就会发现。真的是这样。只能用两个字来形容,即是“真香”。
好了,废话不多说了。今天贴的代码不包含基础配置哈。。
实体类如下:
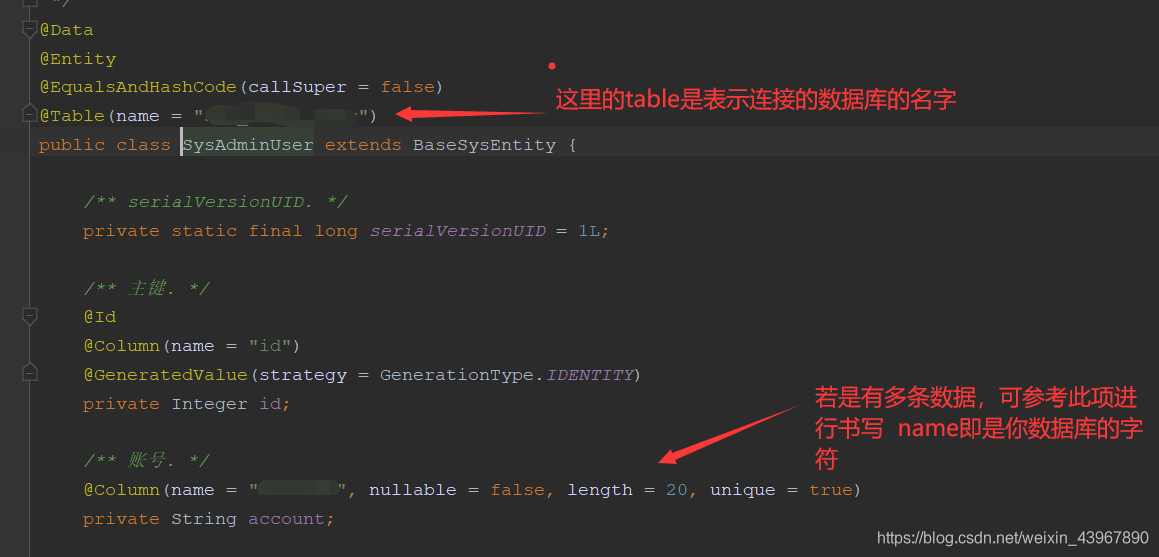
controller层:
@PostMapping(value = "/add")
@ApiOperation(value = "新增功能", notes = "新增功能")
public ResultVo<?> addInfo(@RequestBody @Valid SysAdminUser adminUser){
return demoService.addInfo(adminUser);
}
service层:
public ResultVo<?> addInfo(SysAdminUser adminUser){
SysAdminUser sysAdminUser = modelMapper.map(adminUser, SysAdminUser.class);
demoRepository.save(sysAdminUser);
return ResultVo.success();
}
repository层:

其实,具体的单条数据添加还是看个人的业务逻辑而说,每个人想法不一样,写的代码方式也不一样。如您有更好的写法。也可以贴出来,大家一起进步。
说完单条,该说批量了
用的实体类都是一样的
controller层:
@PostMapping(value = "/batch/add")
@ApiOperation(value = "新增功能", notes = "批量新增")
public Map<String,Object> addListModelParams(@RequestBody List<SysAdminUser> list) {
int listsize = list.size();
Map<String,Object> resultMap = new HashMap<>();
if (listsize == 0) {
throw new RuntimeException("集合为空!") ;
} else {
//批量存储的集合
List<SysAdminUser> data = new ArrayList<SysAdminUser>();
//批量存储
for (SysAdminUser s : list) {
if(data.size() == listsize/10) {
demoService.save(data);
data.clear();
}
data.add(s);
}
//将剩下的数据也导入
if(!data.isEmpty()) {
demoService.save(data);
resultMap.put("code", "0000");
resultMap.put("message", "批量添加成功");
}
}
return resultMap;
}
service层:
public void save(List<SysAdminUser> list) {
demoRepository.saveAll(list);
}
因为在service层的时候,它其实也调的是jpa里面自带的方法。
而repository层的代码也是单纯的一个接口罢了
如下:

springdatajpa 新增操作注意
org.hibernate.PersistentObjectException: detached entity passed to persist异常
简单地来看,将一个游离的对象要被持久化(save)时报错。
我们知道要持久化对象时候,通常Hibernate会根据ID生成策略自动生成ID值,但是这个对象ID已经有值,所有抛错。
这个错误是我在配置如下1一对多@OneToMany的关联关系时报的错。
@OneToMany(targetEntity = Role.class, cascade = CascadeType.ALL, fetch = FetchType.EAGER) @JoinTable(name = "sys_user_role", joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "id"), inverseJoinColumns = @JoinColumn(name = "role_id", referencedColumnName = "id", unique = true)) private Set<Role> roles = new HashSet<>();
因为级联关系是CascadeType.ALL,所以save时会保存级联的对象Role,但是Role已经存在,因此就报错了。
将cascade改为CascadeType.MERGE或者CascadeType.REFRESH即可,表示级联对象在Role表存在则进行update操作,而不做save操作。级联操作时谨慎用CascadeType.ALL
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

详解SpringBoot实现JPA的save方法不更新null属性
序言:直接调用原生Save方法会导致null属性覆盖到数据库,使用起来十分不方便.本文提供便捷方法解决此问题. 核心思路 如果现在保存某User对象,首先根据主键查询这个User的最新对象,然后将此User对象的非空属性覆盖到最新对象. 核心代码 直接修改通用JpaRepository的实现类,然后在启动类标记此实现类即可. 一.通用CRUD实现类 public class SimpleJpaRepositoryImpl<T, ID> extends SimpleJpaRepository&l
-
Spring Data JPA实现动态查询的两种方法
前言 一般在写业务接口的过程中,很有可能需要实现可以动态组合各种查询条件的接口.如果我们根据一种查询条件组合一个方法的做法来写,那么将会有大量方法存在,繁琐,维护起来相当困难.想要实现动态查询,其实就是要实现拼接SQL语句.无论实现如何复杂,基本都是包括select的字段,from或者join的表,where或者having的条件.在Spring Data JPA有两种方法可以实现查询条件的动态查询,两种方法都用到了Criteria API. Criteria API 这套API可用于构建对数据
-
JPA save()方法将字段更新为null的解决方案
这篇文章主要介绍了JPA save()方法将字段更新为null的解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天在开发上碰到一个问题,在做页面展示的时候传给前端十个字段,前端修改了其中3个的值,所以只传了3个值给后端,其余字段默认为null,更新后其他7个字段在全部变为了空值. 在前端没法全量回传所有属性的前提下,由后端来处理这类问题. 解决方法: 1.写一个工具方法(UpdateUtil) 用来筛选出所有的空值字段 2.更新时先通
-
详解Spring Data JPA动态条件查询的写法
我们在使用SpringData JPA框架时,进行条件查询,如果是固定条件的查询,我们可以使用符合框架规则的自定义方法以及@Query注解实现. 如果是查询条件是动态的,框架也提供了查询接口. JpaSpecificationExecutor 和其他接口使用方式一样,只需要在你的Dao接口继承即可(官网代码). public interface CustomerRepository extends CrudRepository<Customer, Long>, JpaSpecification
-
springboot+spring data jpa实现新增及批量新增方式
目录 springboot+spring data jpa实现新增及批量新增 springdatajpa 新增操作注意 springboot+spring data jpa实现新增及批量新增 spring data jpa (以下简称jpa).这个orm其实和mybatis还是差不多的.但是相对于mybatis来说,省去很多方法,毕竟jpa来说,官方文档给的说法是编写者只需要书写接口.剩下的事就交由jpa来完成.当时,洒家还是不信的.当你用过一次后,你就会发现.真的是这样.只能用两个字来形容,即
-
SpringBoot+Spring Data JPA整合H2数据库的示例代码
目录 前言 Maven依赖 Conroller 实体类 Repository 数据库脚本文件 配置文件 启动项目 访问H2数据库 查看全部数据 H2数据库文件 运行方式 前言 H2数据库是一个开源的关系型数据库.H2采用java语言编写,不受平台的限制,同时支持网络版和嵌入式版本,有比较好的兼容性,支持相当标准的sql标准 提供JDBC.ODBC访问接口,提供了非常友好的基于web的数据库管理界面 官网:http://www.h2database.com/ Maven依赖 <!--jpa-->
-
在Spring Data JPA中引入Querydsl的实现方式
一.环境说明 基础框架采用Spring Boot.Spring Data JPA.Hibernate.在动态查询中,有一种方式是采用Querydsl的方式. 二.具体配置 1.在pom.xml中,引入相关包和配置插件. (1)引入包(注:不需要版本号,Spring Boot 会自动匹配合适的版本) <!-- Querydsl相关包 --> <dependency> <groupId>com.querydsl</groupId> <artifactId&
-
spring data JPA 中的多属性排序方式
目录 springdataJPA的多属性排序 第一步,引包 第二步,service方法代码 springdataJPA排序问题(orderby) spring data JPA的多属性排序 在此介绍我所用的一种方式: 第一步,引包 import org.springframework.data.domain.Sort; import org.springframework.data.domain.Sort.Order; 第二步,service方法代码 @Override public P
-
解决spring data jpa saveAll() 保存过慢问题
目录 spring data jpa saveAll() 保存过慢 问题发现 解决方案1 此方案在第二天失效了 以上方案有问题,下面附上彻底解决的截图和记录 JPA的saveAll方法执行效率很差 spring data jpa saveAll() 保存过慢 问题发现 今天在生产环境执行保存数据时 影响队列中其他程序的运行 随后加日志排查 发现 执行 4500条 insert操作时 耗时 9分钟 我类个去- 解决方案1 此方案在第二天失效了 废话不多说 直接上配置文件参数 application
-
Spring Data JPA 映射VO/DTO对象方式
目录 Spring Data JPA 映射VO/DTO对象 HQL方式 原生SQL的形式 Spring Data Jpa 自定义repository转DTO Spring Data JPA 映射VO/DTO对象 在项目开发中,时常需要根据业务需求来映射VO/DTO对象(这两个概念理解感觉很模糊- .- ),本文将简单介绍以Spring Data JPA的方式处理实体类映射 HQL方式 public interface MusicTypeRepository extends JpaReposito
-
spring data jpa开启批量插入、批量更新的问题解析
最近准备上spring全家桶写一下个人项目,该学的都学学,其中ORM框架,最早我用的是jdbcTemplate,后来用了Mybatis,唯独没有用过JPA(Hibernate)系的,过去觉得Hibernate太重量级了,后来随着springboot和spring data jpa出来之后,让我觉得好像还不错,再加上谷歌趋势... 只有中日韩在大规模用Mybatis(我严重怀疑是中国的外包),所以就很奇怪,虽然说中国的IT技术在慢慢抬头了,但是这社会IT发展的主导目前看来还是美国.欧洲,这里JPA
-
Springboot使用Spring Data JPA实现数据库操作
SpringBoot整合JPA 使用数据库是开发基本应用的基础,借助于开发框架,我们已经不用编写原始的访问数据库的代码,也不用调用JDBC(Java Data Base Connectivity)或者连接池等诸如此类的被称作底层的代码,我们将从更高的层次上访问数据库,这在Springboot中更是如此,本章我们将详细介绍在Springboot中使用 Spring Data JPA 来实现对数据库的操作. JPA & Spring Data JPA JPA是Java Persistence API
-
SpringBoot整合Spring Data JPA的详细方法
目录 前言 核心概念 新建SpringBoot项目 创建MySQL数据库 创建实体类 创建Repository 创建处理器 准备SQL文件 编写配置文件 最终效果 启动SpringBoot项目 查看数据库 自动更新数据表结构 测试JPA的增删改查 测试查询所有 测试保存数据 测试更新数据 测试删除数据 前言 Spring Data JPA 是更大的 Spring Data 家族的一部分,可以轻松实现基于 JPA 的存储库.该模块处理对基于 JPA 的数据访问层的增强支持.它使构建使用数据访问技术
-
SpringBoot集成Spring Data JPA及读写分离
相关代码: github OSCchina JPA是什么 JPA(Java Persistence API)是Sun官方提出的Java持久化规范,它为Java开发人员提供了一种对象/关联映射工具 来管理Java应用中的关系数据.它包括以下几方面的内容: 1.ORM映射 支持xml和注解方式建立实体与表之间的映射. 2.Java持久化API 定义了一些常用的CRUD接口,我们只需直接调用,而不需要考虑底层JDBC和SQL的细节. 3.JPQL查询语言 这是持久化操作中很重要的一个方面,通过面向对象