python基本数据类型练习题
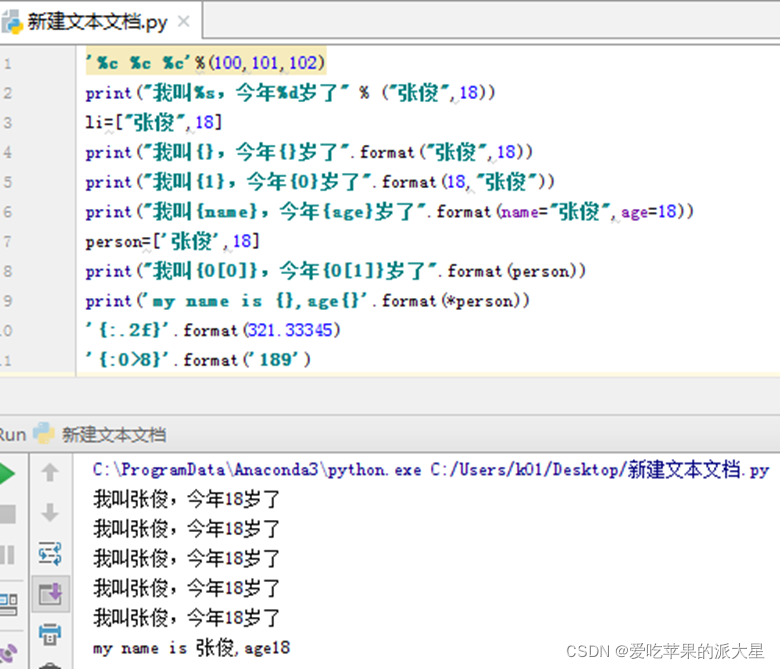
题目[1]:格式输出练习。在交互式状态下完成以下练习。

运行结果截图:
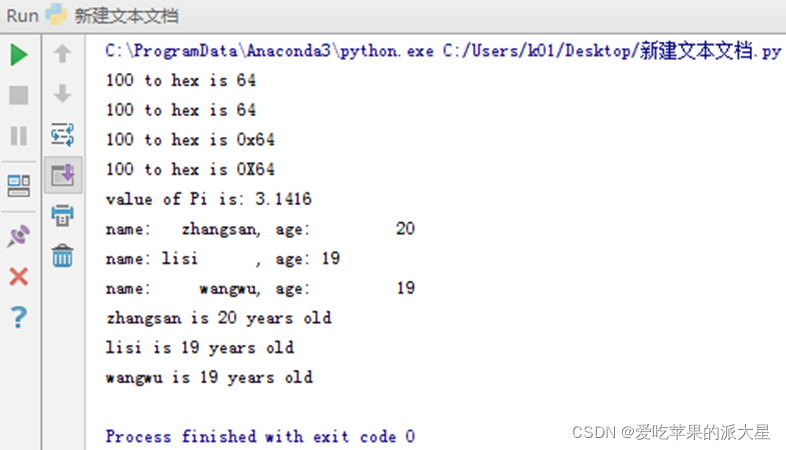
题目[2]:格式输出练习。在.py的文件中完成以下练习

代码:
num = 100
print('%d to hex is %x' % (num,num))
print('%d to hex is %X' % (num,num))
print('%d to hex is %#x' % (num,num))
print('%d to hex is %#X' % (num,num))
from math import pi
print('value of Pi is: %.4f' % pi)
students = [{'name':'zhangsan','age':20},
{'name': 'lisi', 'age': 19},
{'name': 'wangwu', 'age': 19}]
print('name: %10s, age: %10d' % (students[0]['name'],students[0]['age']))
print('name: %-10s, age: %-10d' % (students[1]['name'],students[1]['age']))
print('name: %10s, age: %10d' % (students[2]['name'],students[2]['age']))
for student in students:
print('%(name)s is %(age)d years old' % student)
运行:
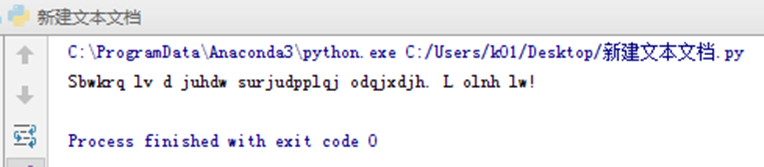
题目[3]:凯撒加密:

原理功能:
通过把字母移动一定的位数来实现加解密
明文中的所有字母从字母表向后(或向前)按照一个固定步长进行偏移后被替换成密文。
例如:当步长为3时,A被替换成D,B被替换成E,依此类推,X替换成A。
代码:
import string #ascii_letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' #ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz' #ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' def kaisa(s, k): lower = string.ascii_lowercase upper = string.ascii_uppercase before = string.ascii_letters after = lower[k:] + lower[:k] + upper[k:] + upper[:k] table = ''.maketrans(before,after) return s.translate(table) s = 'Python is a great programming language. I like it!' print(kaisa(s,3))
运行:
题目[4]:现有八部电影对其评分,有1-10分。
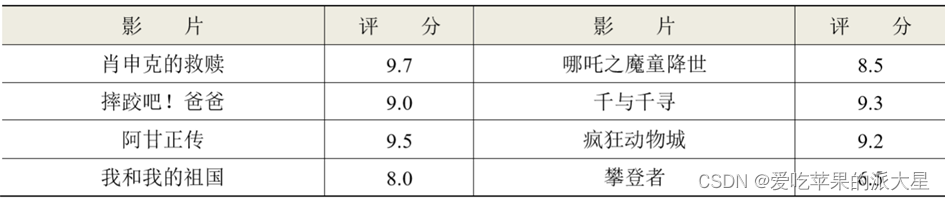
- 1)用字典记录下其豆瓣评分,并输出字典;
- 2)现又新出了两部影片及其评分(中国机长: 7.0,银河补习班: 6.2),将此影评加入1)中的字典中,同时输出字典中所有的影片名称。
- 3)现找出2)中的字典中影评得分最高的影片。
代码和运行结果:
1>
films = {'肖申克的救赎':9.7, '摔跤吧!爸爸':9.0,
'阿甘正传':9.5,'我和我的祖国':8.0,
'哪吒之魔童降世':8.5, '千与千寻':9.3,
'疯狂动物城':9.2,'攀登者':6.5}
print(films)

2>
films_new = {'中国机长':7.0,'银河补习班':6.2}
films.update(films_new) #字典中元素的插入 dict.update()函数
print("所有影片名称: ", films.keys())

3>
print("影片得分最高的影片: ", max(films,key=films.get))

题目[5]:编程实现:生成2组随机6位的数字验证码,每组10000个,且每组内不可重复。输出这2组的验证码重复个数。
代码和运行结果:
import random
code1 = [] #存储校验码列表
code2 = []
t = 0 #标志出现重复校验码个数
dict={}
#第一组校验码
for i in range(10000):
x = ''
for j in range(6):
x = x + str(random.randint(0, 9))
code1.append(x) # 生成的数字校验码追加到列表
#第二组校验码
for i in range(10000):
x = ''
for j in range(6):
x = x + str(random.randint(0, 9))
code2.append(x) # 生成的数字校验码追加到列表
#找重复
for i in range(len(code1)):
for j in range(len(code2)): # 对code1和code2所有校验码遍历
if (code1[i] == code2[j]):
t = t+1 #如果存在相同的,则t+1
if t > 0:
dict[code1[i]] = t # 如果重复次数大于0,用t表示其个数,存储在字典
#输出所有重复的校验码及其个数
for key in dict:
print(key + ":" + str(dict[key]))
截取几张:
题目[6]:统计英文句子“Life is short, we need Python."中各字符出现的次数。
代码和运行结果:
#去空格,转化为list,然后再转化为字典
str = 'Life is short, we need Python.'
list = []
list2 = []
dict={}
i= 0
for w in str:
if w!=' ':
list.append(w)
#将str字符串的空格去掉放在list列表
for w in list:
c = list.count(w) #用count()函数返回当前字符的个数
dict[w] = c #针对字符w,用c表示其个数,存储在字典
print(dict) #输出字典

题目[7]:输入一句英文句子,输出其中最长的单词及其长度。
提示:可以使用split方法将英文句子中的单词分离出来存入列表后处理。
代码和运行结果:
test0 = 'It is better to live a beautiful life with all one''s ' \
'strength than to comfort oneself with ordinary and precious things!.'
test1 = test0.replace(',','').replace('.','') #用空格代替句子中“,”的空格和“。”
test2 = test1.split () #将英文句子中的单词分离出来存入列表
maxlen = max(len(word) for word in test2) #找到最大长度的单词长度值
C=[word for word in test2 if len(word)== maxlen] #找到最大长度的单词对应单词
print("最长的单词是:“{}” , 里面有 {} 个字母".format(C[0],maxlen))
到此这篇关于python基本数据类型介绍的文章就介绍到这了,更多相关python基本数据类型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
学好python基本数据类型
目录 一.基本用法 1.注释 2.输出 3.变量 4.命名规范 5.变量的定义方式 二.python的数据类型 1.字符串类型 2.数字类型 3.List列表类型 4.tuple 元组类型的定义 5.Dict字典类型 6.set集合类型 7.数据类型转换 8.自动类型转换 9.强制类型转换 一.基本用法 1.注释 Python中,#+语句 即为一条注释,也可以用 '''注释块 ''' #人生苦短,我用Python 2.输出 Python中,print()为输出函数 print("Hello Wo
-

python数据结构:数据类型
目录 1.数据是什么? 2.数据类型 2.1内建原子数据类型 2.2 内建集合数据类型 3.集合数据类型的方法 3.1 列表 3.2 字符串 3.3 元祖 3.4 集合 3.5 字典 1.数据是什么? 在 Python 以及其他所有面向对象编程语言中,类都是对数据的构成(状态)以及数据 能做什么(行为)的描述.由于类的使用者只能看到数据项的状态和行为,因此类与抽象数据类 型是相似的.在面向对象编程范式中,数据项被称作对象.一个对象就是类的一个实例. 2.数据类型 2.1内建原子数据类型 Pyth
-
Python全栈之基本数据类型
目录 1. number类型 1.1 int整型 1.2 float浮点型(小数) 1.3 bool布尔型 1.4 复数类型 2. 字符串类型 3. 列表_元组_字符串 3.1 列表类型 3.2 元组类型 3.3 字符串类型 4. 集合_字典 4.1 集合类型 4.2 字典类型 5. 变量的缓存机制 6. 小练习 总结 1. number类型 Number 数字类型 (int float bool complex) 1.1 int整型 # int 整型 (正整型 0 负整型) intvar =
-
Python数据类型-序列sequence
目录 1 概述 2 基本操作 2.1 索引 2.2 切片 2.3 加 2.4 乘 1 概述 在前面,我们已经对Python学习做了系统的知识梳理(Python思维导图),我们接下来把知识点分节进行细讲.这一节,我们讲解序列. 在介绍 Python 的常用数据类型之前,我们先看看 Python 最基本的数据结构 -——序列(sequence).序列的一个特点就是根据索引(index,即元素的位置)来获取序列中的元素,第一个索引是 0,第二 个索引是 1,以此类推. 所有序列类型都可以进行某些通用的
-
python基本数据类型练习题
题目[1]:格式输出练习.在交互式状态下完成以下练习. 运行结果截图: 题目[2]:格式输出练习.在.py的文件中完成以下练习 代码: num = 100 print('%d to hex is %x' % (num,num)) print('%d to hex is %X' % (num,num)) print('%d to hex is %#x' % (num,num)) print('%d to hex is %#X' % (num,num)) from math import pi pr
-
Python的内置数据类型中的数字
目录 Python的内置数据类型中的数字 1.变量 2.数据类型总览 3.Python是弱类型的语言 4.各数据类型的详细介绍 4.1 整数(int) 4.2 浮点数/小数(float) 5.复数(complex) 6.布尔类型(bool) Python的内置数据类型中的数字 1.变量 说数据类型之前,我们要先思考一下下面几个问题: 数据是怎么存的呢? 数据类型有啥作用呢? 各种数据类型有啥区别呢? 要想回答这些问题,首先还是要先了解一下变量的概念.那么何为变量呢? 变量(Variable)可以
-
python装饰器练习题及答案
这篇文章主要介绍了python装饰器练习题及答案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一:编写装饰器,为多个函数加上认证的功能(用户的账号密码) 要求登录成功一次,后续的函数都无需输入用户名和密码 FLAG=False#此时还未登录 全局变量 写这个步骤的意义在于:方便 知道已经登录成功了,就不再重复登录 def login(func):#为多个函数加上的认证功能 def inner(*args,**kwargs):#加上装饰器 gl
-
python 基本数据类型占用内存空间大小的实例
python中基本数据类型和其他的语言占用的内存空间大小有很大差别 import sys a = 100 b = True c = 100L d = 1.1 e ="" f = [] g =() h = {} i = set([]) print " %s size is %d "%(type(a),sys.getsizeof(a)) print " %s size is %d "%(type(b),sys.getsizeof(b)) print
-
Python基本数据类型之字符串str
字符串的表示方式 单引号 ' ' 双引号 " " 多引号 """ """" . ''' ''' print("hello world") print('hello world') print("""hello world""") # 输出结果 hello world hello world hello world 为什么需要单引号,又需
-
Python基础数据类型tuple元组的概念与用法
目录 元组简单介绍 声明元组 元组与列表的区别 特殊的元组 元组的简写 元组常见运算操作 索引 [ ] 取值 切片 [ : : ] 取值 运算符 + 运算符 * 关键字 in 常见函数 max(元组) 函数 min(元组) 函数 元组常见方法 index(item) count(value) 元组总结 元组简单介绍 元组是一个和列表和相似的数据类型,也是一个有序序列 两者拥有着基本相同的特性,但是也有很多不同的地方 声明元组 var = (1, 2, 3) var = ("1", &q
-
python 循环结构练习题
目录 1.求两个数最大公约数 2.整数反转:如12345,输出54321 3.1~10之间的整数相加,得到累加值大于20的当前数 4.输入从周一至周五每天的学习时间(以小时为单位),并计算每日平均学习时间. 5.输出10000以下的完全数 6.用户玩游戏 7.菜单自动循环 8.打印图形 1.求两个数最大公约数 num1 = int(input('请输入第一个数:')) num2 = int(input('请输入第二个数:')) max_num = max(num1, num2) min_num
-
Python 转换数据类型函数和转换数据类型的作用
目录 一.转换数据类型的作用(必要性) 二.转换数据类型的函数 三.快速体验数据类型转换 前言: 学习Python的转换数据类型前期主要学习目标有两个,一是数据类型转换的必要性,二是数据类型转换常用方法. 一.转换数据类型的作用(必要性) 先用一个问题来讲解一下为什么要学习转换数据类型? 问题:input()接收用户输入的数据都是字符串类型,如果用户输入8,想得到整型该怎么样操作? 回答:转换数据的数据类型即可,也就是把字符串转换成整型 二.转换数据类型的函数 在Python学习中我们可以借助P
-
Python基本数据类型及内置方法
目录 一 引子 二 数字类型int与float 2.1 定义 2.2 类型转换 2.3 使用 三 字符串 3.1 定义 3.2 类型转换 3.3 使用 3.3.1 优先掌握的操作 3.3.2 需要掌握的操作 3.3.3 了解操作 四 列表 4.1 定义 4.2 类型转换 4.3 使用 4.3.1 优先掌握的操作 4.3.2 了解操作 五 元组 5.1 作用 5.2 定义方式 5.3 类型转换 5.4 使用 六 字典 6.1 定义方式 6.2 类型转换 6.3 使用 6.3.1 优先掌握的操作 6