带你了解C++初阶之引用
目录
- 一、 引用概念
- 二、 引用特性
- 三、 常引用
- 四、 使用场景
- 1、做参数
- 指针
- 引用
- 2、做返回值
- 2.1、传值返回
- 2.2、传引用返回
- 小结引用做返回值
- 五、函数参数及返回值 —— 传值、传引用效率比较
- 六、 引用和指针的区别
- 1.语法概念
- 2.底层实现
- 总结
一、 引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,语法理解上程序不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间
比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"

类型& 引用变量名(对象名) = 引用实体
int main()
{
//有一块空间a,后面给a取了三个别名b、c、d
int a = 10;
int& b = a;
int& c = a;
int& d = b;
//char& d = a;//err,引用类型和引用实体不是同类型(这里有争议————char a = b[int类型],留个悬念,下面会解答)
//会被修改
c = 20;
d = 30;
return 0;
}
注意
- 引用类型必须和引用实体是同种类型
- 注意区分 ‘&’ 取地址符号
二、 引用特性
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
int main()
{
//int& e;//err
int a = 10;
int& b = a;
//这里指的是把c的值赋值于b
int c = 20;
b = c;
return 0;
}
三、 常引用
void TestConstRef()
{
const int a = 10;
//int& ra = a; //该语句编译时会出错,a为常量;由const int到int
const int& ra = a;//ok
int b = 20;
const int& c = b; //ok,由int到const int
//b可以改,c只能读不能写
b = 30;
//c = 30;//err
//b、c分别起的别名的权限可以是不变或缩小
int& d = b;//ok
//int& e = c//err
const int& e = c;//ok
//int& f = 10; // 该语句编译时会出错,b为常量
const int& g = 10;//ok
int h = 10;
double i = h;//ok
//double& j = h;//err
const double& j = h;//ok
//?为啥h能赋值给i了(隐式类型转换),而给h起一个double类型的别名却不行————如果是仅仅是类型的问题那为啥加上const就行了?
//double i = h;并不是直接把h给i,而是在它们中间产生了一个临时变量(double类型、常量),并利用这个临时变量赋值
//也就是说const double& j = h;就意味着j不是直接变成h的别名,而是变成临时变量(doublde类型)的别名,但是这个临时变量是一个常量,这也解释了为啥需要加上const
}
小结
1.我能否满足你变成别名的条件:可以不变或者缩小你读写的权限 (const int -> const int 或 int -> const int),而不能放大你读写的权限 (const int -> int)
2.别名的意义可以改变,并不是每个别名都跟原名有一样的权限
3.不能给类型不同的变量起别名的真正原因不是类型不同,而是隐式类型转换后具有常性了
常引用的意义 (举例栈)
typedef struct Stack
{
int* a;
int top;
int capacity;
}ST;
void InitStack(ST& s)//传引用是为了形参的改变影响实参
{//...}
void PrintStack(const ST& s)//1.传引用是为了减少拷贝 2. 同时保护实参不会被修改
{//...}
void Test(const int& n)//即可以接收变量,也可以接收常量
{//...}
int main()
{
ST st;
InitStack(st);
//...
PrintStack(st);
int i = 10;
Test(i);
Test(20);
return 0;
}
小结
1.函数传参如果想减少拷贝使用引用传参,如果函数中不改变这个参数最好使用 const 引用传参
2.const 引用的好处是保护实参,避免被误改,且它可以传普通对象也可以传 const 对象
四、 使用场景
1、做参数
void Swap1(int* p1, int* p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
void Swap2(int& rx, int& ry)
{
int temp = rx;
rx = ry;
ry = temp;
}
int main()
{
int x = 3, y = 5;
Swap1(&x, &y);//C传参
Swap2(x, y);//C++传参
return 0;
}
在 C++ 中形参变量的改变,要影响实参,可以用指针或者引用解决
意义:指针实现单链表尾插 || 引用实现单链表尾插
指针
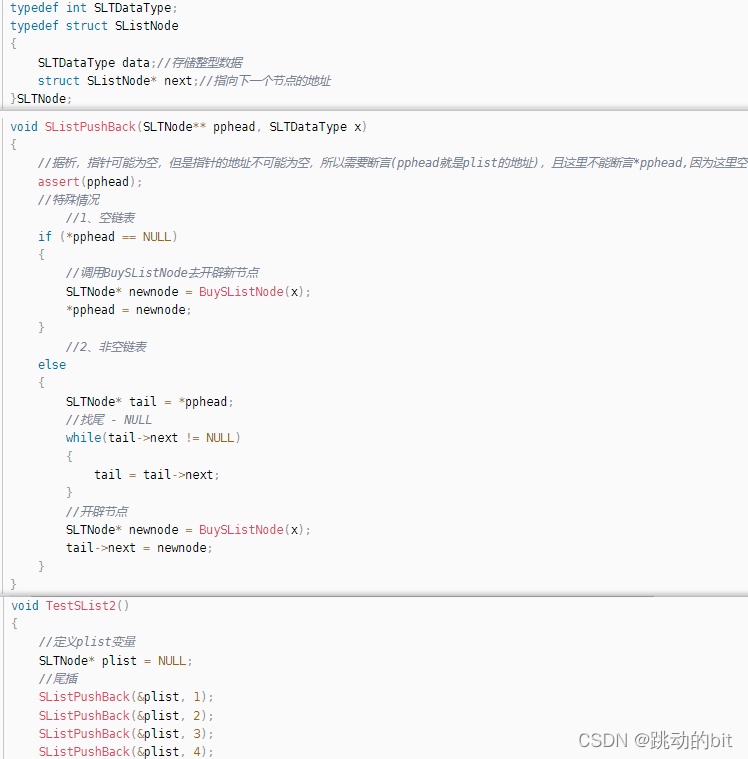
引用
void SListPushBack(SLTNode*& phead, int x)
{
//这里phead的改变就是plist的改变
}
void TestSList2()
{
SLTNode* plist = NULL;
SListPushBack(plist, 1);
SListPushBack(plist, 2);
}
有些书上喜欢这样写 (不推荐)
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode, *PSLTNode;
void SListPushBack(PSLTNode& phead, int x)
{
//...
}
2、做返回值
2.1、传值返回
//传值返回
int Add(int a, int b)
{
int c = a + b;
return c;//需要拷贝
}
int main()
{
int ret = Add(1, 2);//ok, 3
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
Add 函数里的 return c; —— 传值返回,临时变量作返回值。如果比较小,通常是寄存器;如果比较大,会在 main 函数里开辟一块临时空间
怎么证明呢
int Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
//int& ret = Add(1, 2);//err
const int& ret = Add(1, 2);//ok, 3
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
从上面就可以验证 Add 函数的返回值是先存储在临时空间里的
2.2、传引用返回
//传引用返回
int& Add(int a, int b)
{
int c = a + b;
return c;//不需要拷贝
}
int main()
{
int ret = Add(1, 2);//err, 3
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
结果是不确定的,因为 Add 函数的返回值是 c 的别名,所以在赋给 ret 前,c 的值到底是 3 还是随机值,跟平台有关系 (具体是平台销毁栈帧时是否会清理栈帧空间),所以这里的这种写法本身就是越界的 (越界抽查不一定报错)、错误的
发现这样也能跑,但诡异的是为啥 ret 是 7
//传引用返回
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);//err, 7
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
在上面我们在 VS 下运行,可以得出编译器并没有清理栈帧,那么这里进一步验证引用返回的危害
虽然能正常运行,但是它是有问题的

小结引用做返回值
1.出了 TEST 函数的作用域,ret 变量会销毁,就不能引用返回
2. 出了 TEST 函数的作用域,ret 变量不会销毁,就可以引用返回
3.引用返回的价值是减少拷贝
观察并剖析以下代码
int main()int main()
{
int x = 3, y = 5;
int* p1 = &x;
int* p2 = &y;
int*& p3 = p1;
*p3 = 10;
p3 = p2;
return 0;
}

五、函数参数及返回值 —— 传值、传引用效率比较
#include <time.h>#include<iostream>using namespace std;struct A { int a[10000]; };A a;void TestFunc1(A a) {}void TestFunc2(A& a) {}A TestFunc3() { return a; }A& TestFunc4() { return a; }void TestRefAndValue(){A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;}void TestReturnByRefOrValue(){// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc3();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc4();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;}int main(){//传值、传引用效率比较TestRefAndValue();cout << "----------cut----------" << endl;//值和引用作为返回值类型的性能比较TestReturnByRefOrValue();return 0;}#include <time.h>
#include<iostream>
using namespace std;
struct A { int a[10000]; };
A a;
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
A TestFunc3() { return a; }
A& TestFunc4() { return a; }
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc3();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc4();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
//传值、传引用效率比较
TestRefAndValue();
cout << "----------cut----------" << endl;
//值和引用作为返回值类型的性能比较
TestReturnByRefOrValue();
return 0;
}
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低
六、 引用和指针的区别
1.语法概念
引用就是一个别名,没有独立空间,和其引用实体共用同一块空间
指针变量是开辟一块空间,存储变量的地址
int main()
{
int a = 10;
int& ra = a;
cout<<"&a = "<<&a<<endl;
cout<<"&ra = "<<&ra<<endl;
int b = 20;
int* pb = &b;
cout<<"&b = "<<&b<<endl;
cout<<"&pb = "<<&pb<<endl;
return 0;
}
2.底层实现
引用和指针是一样的,因为引用是按照指针方式来实现的
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
这里我们对比一下 VS 下引用和指针的汇编代码可以看出来他俩是同根同源
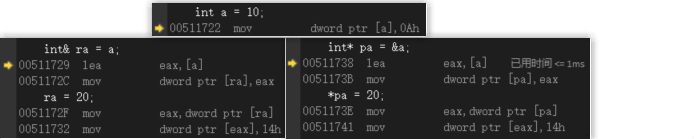
引用和指针的不同点:
1、引用在定义时必须初始化,指针没有要求
2、引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
3 、没有 NULL 引用,但有 NULL 指针
4、在 sizeof 中含义不同:引用结果为引用类型的大小,与类型有关;但指针始终是地址空间所占字节个数 (32 位平台下占 4 个字节,64 位平台下占 8 个字节),与类型无关
5、引用自加即引用的实体增加 1,与类型无关,指针自加即指针向后偏移一个类型的大小,与类型有关
6、有多级指针,但是没有多级引用
7、访问实体方式不同,指针需要解引用,引用编译器自己处理
8、引用比指针使用起来相对更安全,指针容易出现野指针、空指针等非法访问问题
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

C++成员解除引用运算符的示例详解
下面看下成员解除引用运算符,C++允许定义指向类成员的指针,对这种指针进行声明或解除引用时,需要使用一种特殊的表示法.例: class Example { private: int feet; int inches; public: Example(); Example(int ft); ~Example(); void show_in()const; void show_ft()const; void use_ptr()const; }; 如果没有具体的对象,则inches成员只是一个标签.也
-
C++引用和结构体介绍
目录 文章转自微信公众号:Coder梁(ID:Coder_LT) 结构体是我们自定义的复合类型,本质上也是一种变量类型,所以一样可以使用引用.传递结构体引用的方式和其他变量一样: struct P { int x, y; }; void set_axis(P& a, P& b); 前文C++引用的使用与const修饰符当中也曾说过,虽然引用在基本类型上一样适用,但一般在实际使用当中,不在基本变量类型上使用引用.倒不是有什么问题,而是没有必要,毕竟基本变量类型占据的内存太小了,值传递和引用传
-
C++引用的详细解释
目录 一.C++ 引用 1.规则 2.应用 3.引用提高 1.可以定义指针的引用,但不能定义引用的引用. 2.可以定义指针的指针,不能定义引用的指针. 3.可以定义指针数组,但不能定义引用数组,可以定义数组引用. 4.常引用 4.常引用原理 5.const的好处 6.引用的本质浅析 总结 一.C++ 引用 变量名,本身是一段内存的引用,即别名(alias).此处引入的引用,是为己有变量起一个别名. 声明如下 int main() { int a; int &b = a; } 1.规则 1.引用没
-
C++引用和指针的区别你知道吗
目录 引用 1.引用概念 2.格式 3.引用特性 4.常引用 1.const引用 5.使用场景 1.引用作为参数 2. 引用作为做返回值 6.引用和指针的区别 7.引用和指针的不同点: 总结 引用 1.引用概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间. 比如:李逵,在家称为"铁牛",江湖上人称"黑旋风 2.格式 类型& 引用变量名(对象名) = 引用实体: 例: void TestRe
-
解析C++引用
引言 我选择写C++中的引用是因为我感觉大多数人误解了引用.而我之所以有这个感受是因为我主持过很多C++的面试,并且我很少从面试者中得到关于C++引用的正确答案. 那么c++中引用到底意味这什么呢?通常一个引用让人想到是一个引用的变量的别名,而我讨厌将c++中引用定义为变量的别名.这篇文章中,我将尽量解释清楚,c++中根本就没有什么叫做别名的东东. 背景 在c/c++中,访问一个变量只能通过两种方式被访问,传递,或者查询.这两种方式是: 1.通过值访问/传递变量 2.通过地址访问/传递变量–这种
-
C++指针与引用的异同
目录 1.引用与指针的区别 1.1 相同点 1.2 区别 1.引用与指针的区别 指针和引用的原理非常的相似,所以很多时候尤其是面试的时候经常会拿来比较. 本文来梳理一下引用和指针的一些异同. 1.1 相同点 两者都是关于地址的概念. 指针本身是一个变量,它存储的值是一块内存地址,而引用是某一个内存的别名.我们可以使用指针或引用修改对应内存的值. 1.2 区别 引用必须在声明时初始化,而指针可以不用 我们无法声明一个变量引用再给它赋值,只能在声明的同时进行初始化: int a = 3; int &
-
带你了解C++初阶之引用
目录 一. 引用概念 二. 引用特性 三. 常引用 四. 使用场景 1.做参数 指针 引用 2.做返回值 2.1.传值返回 2.2.传引用返回 小结引用做返回值 五.函数参数及返回值 —— 传值.传引用效率比较 六. 引用和指针的区别 1.语法概念 2.底层实现 总结 一. 引用概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,语法理解上程序不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间 比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"
-
C语言新手初阶教程之三子棋实现
目录 三子棋 创建项目环境 头文件内容 编写main函数(test.c) 实现每一个接口函数 1.board 2.printfboard 3.play 4.computerplay 5.win 总结 三子棋 大家小时候应该都玩过三子棋吧,学习了这么久的C语言,我们其实已经具备了做三子棋这种小型项目的能力,今天我会尽量沉浸式的教大家实现三子棋,如果看完这篇博客还是不会的可以去我最后附上的gitee仓库链接中寻找.但我还是希望大家能自己完成,在三子棋中体现自己的风格. 创建项目环境 首先,第一步,打
-
C++初阶教程之类和对象
目录 类和对象<上> 1. 类的定义 2. 类的封装 2.1 访问限定修饰符 2.2 类的封装 3. 类的使用 3.1 类的作用域 3.2 类的实例化 4. 类对象的存储 5. this 指针 5.1 this 指针的定义 5.2 this 指针的特性 类和对象<中> 1. 构造函数 1.2 构造函数的定义 2.2 构造函数的特性 2. 析构函数 2.1 析构函数的定义 3. 拷贝构函数 3.1 拷贝构造函数的定义 3.2 拷贝构造函数的特性 4. 运算符重载 4.1 运算符重载的
-
C++初阶之list的模拟实现过程详解
list的介绍 list的优点: list头部.中间插入不再需要挪动数据,O(1)效率高 list插入数据是新增节点,不需要增容 list的缺点: 不支持随机访问,访问某个元素效率O(N) 底层节点动态开辟,小节点容易造成内存碎片,空间利用率低,缓存利用率低. 今天来模拟实现list 我们先来看看官方文档中对于list的描述 我们先大致了解一下list的遍历 迭代器 对于迭代器我们可以用while循环+begin()end().同时还可以用迭代器区间. 当然迭代器区间的方式只适用于内存连续的结构
-
C语言中的指针 初阶
目录 1.指针是什么 2.指针和指针类型 3.野指针 3.1野指针成因 3.2如何规避野指针 4.指针的运算 4.1指针±整数 4.2指针-指针 4.3指针的关系运算 5.指针和数组 6.二级指针 7.指针数组 1.指针是什么 初学者都有一个疑问,那就是指针是什么?简单的说,就是通过它能找到以它为地址的内存单元. 地址指向了一个确定的内存空间,所以地址形象的被称为指针. int main() { int a = 10; int* pa = &a; return 0; } //pa是用来存放地址(
-
Python Matplotlib初阶使用入门教程
目录 0. 前言 1. 创建Figure的两种基本方法 1.1 第1种方法 1.2 第2种方法 2. Figure的解剖图及各种基本概念 2.1 Figure 2.2 Axes 2.3 Axis 2.4 Artist 3. 绘图函数的输入 4. 面向对象接口与pyplot接口 5. 绘图复用实用函数例 0. 前言 本文介绍Python Matplotlib库的入门求生级使用方法. 为了方便以下举例说明,我们先导入需要的几个库.以下代码在Jupyter Notebook中运行. %matplotl
-
C语言初阶之数组详细介绍
目录 插入排序讲解 二维数组 二维数组的初始化 二维数组的访问 n维数组 字符数组 字符数组和字符串 字符数组的输入输出 字符串函数的简单使用 综合使用字符串函数 总结 插入排序讲解 #include<stdio.h> int main() { int arr[8] = { 1,2,3,4,6,7,10 }; int i = 0; int sz = sizeof(arr) / sizeof(arr[0]); int n = 0; scanf("%d", &n); f
-
10分钟带你理解Java中的弱引用
前言 本文尝试从What.Why.How这三个角度来探索Java中的弱引用,帮助大家理解Java中弱引用的定义.基本使用场景和使用方法. 一. What--什么是弱引用? Java中的弱引用具体指的是java.lang.ref.WeakReference<T>类,我们首先来看一下官方文档对它做的说明: 弱引用对象的存在不会阻止它所指向的对象被垃圾回收器回收.弱引用最常见的用途是实现规范映射(canonicalizing mappings,比如哈希表). 假设垃圾收集器在某个时间点决定一个对象是
-
C语言中的初阶指针详解
目录 1.指针是什么 2.指针和指针类型 3.野指针 3.1野指针成因 3.2如何规避野指针 4.指针的运算 4.1指针±整数 4.2指针-指针 4.3指针的关系运算 5.指针和数组 6.二级指针 7.指针数组 总结 1.指针是什么 初学者都有一个疑问,那就是指针是什么?简单的说,就是通过它能找到以它为地址的内存单元. 地址指向了一个确定的内存空间,所以地址形象的被称为指针. int main() { int a = 10; int* pa = &a; return 0; } //pa是
-
C语言中的指针新手初阶指南
目录 1.指针是什么 2.指针和指针类型 3.野指针 3.1野指针成因 3.2如何规避野指针 4.指针的运算 4.1指针±整数 4.2指针-指针 4.3指针的关系运算 5.指针和数组 6.二级指针 7.指针数组 总结 1.指针是什么 初学者都有一个疑问,那就是指针是什么?简单的说,就是通过它能找到以它为地址的内存单元. 地址指向了一个确定的内存空间,所以地址形象的被称为指针. int main() { int a = 10; int* pa = &a; return 0; } //pa是用来