据Python爬虫不靠谱预测可知今年双十一销售额将超过6000亿元
不知不觉,双十一到今年已经是13个年头,每年大家都在满心期待看着屏幕上的数字跳动,年年打破记录。而 2019 年的天猫双11的销售额却被一位微博网友提前7个月用数据拟合的方法预测出来了。他的预测值是2675.37或者2689.00亿元,而实际成交额是2684亿元。只差了5亿元,误差率只有千分之一。
但如果你用同样的方法去做预测2020年的时候,发现预测是3282亿,实际却到了 4982亿。原来2020改了规则,实际上统计的是11月1到11日的销量,理论上已经不能和历史数据合并预测,但咱们就为了图个乐,主要是为了练习一下 Python 的多项式回归和可视化绘图。
把预测先发出来:今年双十一的销量是 9029.688 亿元!坐等双十一,各位看官回来打我的脸。欢迎文末技术交流学习,喜欢点赞支持。
NO.1 统计历年双十一销量数据
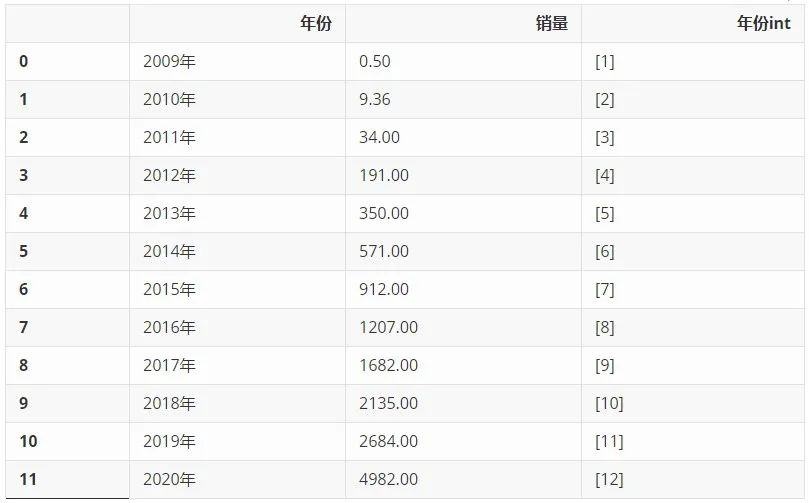
从网上搜集来历年淘宝天猫双十一销售额数据,单位为亿元,利用 Pandas 整理成 Dataframe,又添加了一列'年份int',留作后续的计算使用。
import pandas as pd
# 数据为网络收集,历年淘宝天猫双十一销售额数据,单位为亿元,仅做示范
double11_sales = {'2009年': [0.50],
'2010年':[9.36],
'2011年':[34],
'2012年':[191],
'2013年':[350],
'2014年':[571],
'2015年':[912],
'2016年':[1207],
'2017年':[1682],
'2018年':[2135],
'2019年':[2684],
'2020年':[4982],
}
df = pd.DataFrame(double11_sales).T.reset_index()
df.rename(columns={'index':'年份',0:'销量'},inplace=True)
df['年份int'] = [[i] for i in list(range(1,len(df['年份'])+1))]
df
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
NO.2 绘制散点图
利用 plotly 工具包,将年份对应销售量的散点图绘制出来,可以明显看到2020年的数据立马飙升。
# 散点图
import plotly as py
import plotly.graph_objs as go
import numpy as np
year = df[:]['年份']
sales = df['销量']
trace = go.Scatter(
x=year,
y=sales,
mode='markers'
)
data = [trace]
layout = go.Layout(title='2009年-2020年天猫淘宝双十一历年销量')
fig = go.Figure(data=data, layout=layout)
fig.show()

NO.3引入 Scikit-Learn 库搭建模型
一元多次线性回归
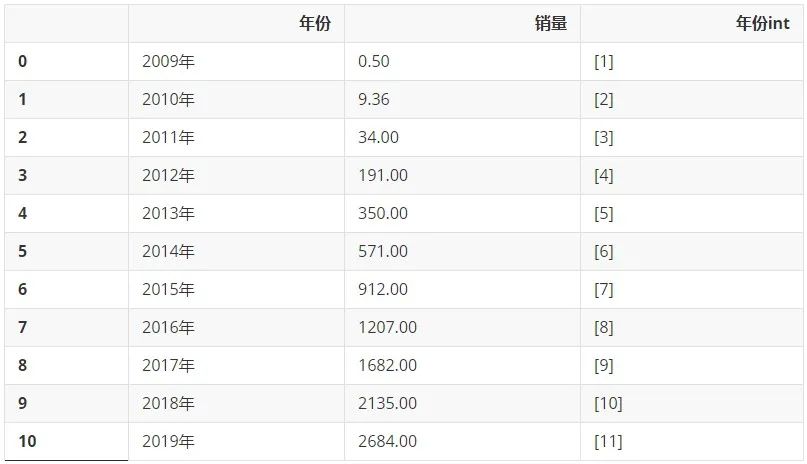
我们先来回顾一下2009-2019年的数据多么美妙。先只选取2009-2019年的数据:
df_2009_2019 = df[:-1] df_2009_2019
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
通过以下代码生成二次项数据:
from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree=2) X_ = poly_reg.fit_transform(list(df_2009_2019['年份int']))
1.第一行代码引入用于增加一个多次项内容的模块 PolynomialFeatures
2.第二行代码设置最高次项为二次项,为生成二次项数据(x平方)做准备
3.第三行代码将原有的X转换为一个新的二维数组X_,该二维数据包含新生成的二次项数据(x平方)和原有的一次项数据(x)
X_ 的内容为下方代码所示的一个二维数组,其中第一列数据为常数项(其实就是X的0次方),没有特殊含义,对分析结果不会产生影响;第二列数据为原有的一次项数据(x);第三列数据为新生成的二次项数据(x的平方)。
X_
array([[ 1., 1., 1.],
[ 1., 2., 4.],
[ 1., 3., 9.],
[ 1., 4., 16.],
[ 1., 5., 25.],
[ 1., 6., 36.],
[ 1., 7., 49.],
[ 1., 8., 64.],
[ 1., 9., 81.],
[ 1., 10., 100.],
[ 1., 11., 121.]])
from sklearn.linear_model import LinearRegression regr = LinearRegression() regr.fit(X_,list(df_2009_2019['销量']))
LinearRegression()
1.第一行代码从 Scikit-Learn 库引入线性回归的相关模块 LinearRegression;
2.第二行代码构造一个初始的线性回归模型并命名为 regr;
3.第三行代码用fit() 函数完成模型搭建,此时的regr就是一个搭建好的线性回归模型。
NO.4 模型预测
接下来就可以利用搭建好的模型 regr 来预测数据。加上自变量是12,那么使用 predict() 函数就能预测对应的因变量有,代码如下:
XX_ = poly_reg.fit_transform([[12]])
XX_
array([[ 1., 12., 144.]])
y = regr.predict(XX_) y
array([3282.23478788])
这里我们就得到了如果按照这个趋势2009-2019的趋势预测2020的结果,就是3282,但实际却是4982亿,原因就是上文提到的合并计算了,金额一下子变大了,绘制成图,就是下面这样:
# 散点图
import plotly as py
import plotly.graph_objs as go
import numpy as np
year = list(df['年份'])
sales = df['销量']
trace1 = go.Scatter(
x=year,
y=sales,
mode='markers',
name="实际销量" # 第一个图例名称
)
XX_ = poly_reg.fit_transform(list(df['年份int'])+[[13]])
regr = LinearRegression()
regr.fit(X_,list(df_2009_2019['销量']))
trace2 = go.Scatter(
x=list(df['年份']),
y=regr.predict(XX_),
mode='lines',
name="拟合数据", # 第2个图例名称
)
data = [trace1,trace2]
layout = go.Layout(title='天猫淘宝双十一历年销量',
xaxis_title='年份',
yaxis_title='销量')
fig = go.Figure(data=data, layout=layout)
fig.show()

NO.5 预测2021年的销量
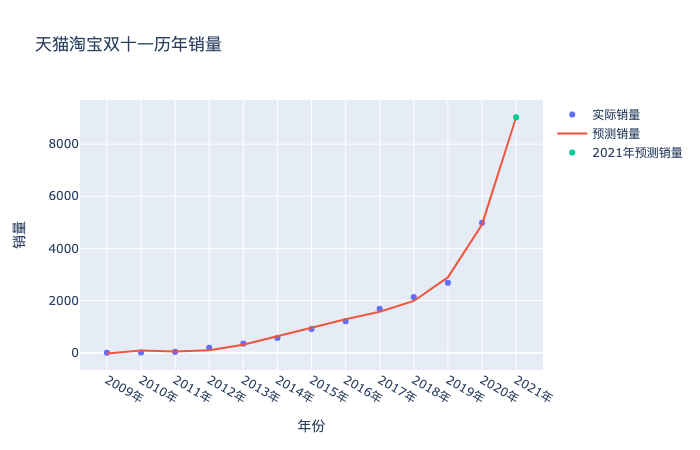
既然数据发生了巨大的偏离,咱们也别深究了,就大力出奇迹。同样的方法,把2020年的真实数据纳入进来,二话不说拟合一样,看看会得到什么结果:
from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree=5) X_ = poly_reg.fit_transform(list(df['年份int']))
## 预测2020年 regr = LinearRegression() regr.fit(X_,list(df['销量']))
LinearRegression()
XXX_ = poly_reg.fit_transform(list(df['年份int'])+[[13]])
# 散点图
import plotly as py
import plotly.graph_objs as go
import numpy as np
year = list(df['年份'])
sales = df['销量']
trace1 = go.Scatter(
x=year+['2021年','2022年','2023年'],
y=sales,
mode='markers',
name="实际销量" # 第一个图例名称
)
trace2 = go.Scatter(
x=year+['2021年','2022年','2023年'],
y=regr.predict(XXX_),
mode='lines',
name="预测销量" # 第一个图例名称
)
trace3 = go.Scatter(
x=['2021年'],
y=[regr.predict(XXX_)[-1]],
mode='markers',
name="2021年预测销量" # 第一个图例名称
)
data = [trace1,trace2,trace3]
layout = go.Layout(title='天猫淘宝双十一历年销量',
xaxis_title='年份',
yaxis_title='销量')
fig = go.Figure(data=data, layout=layout)
fig.show()
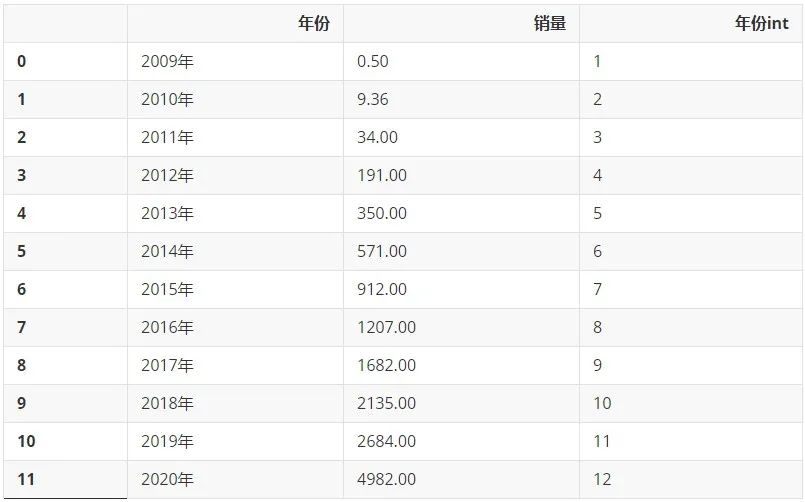
NO.6多项式预测的次数到底如何选择
在选择模型中的次数方面,可以通过设置程序,循环计算各个次数下预测误差,然后再根据结果反选参数。
df_new = df.copy() df_new['年份int'] = df['年份int'].apply(lambda x: x[0]) df_new
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
# 多项式回归预测次数选择
# 计算 m 次多项式回归预测结果的 MSE 评价指标并绘图
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_squared_error
train_df = df_new[:int(len(df)*0.95)]
test_df = df_new[int(len(df)*0.5):]
# 定义训练和测试使用的自变量和因变量
train_x = train_df['年份int'].values
train_y = train_df['销量'].values
# print(train_x)
test_x = test_df['年份int'].values
test_y = test_df['销量'].values
train_x = train_x.reshape(len(train_x),1)
test_x = test_x.reshape(len(test_x),1)
train_y = train_y.reshape(len(train_y),1)
mse = [] # 用于存储各最高次多项式 MSE 值
m = 1 # 初始 m 值
m_max = 10 # 设定最高次数
while m <= m_max:
model = make_pipeline(PolynomialFeatures(m, include_bias=False), LinearRegression())
model.fit(train_x, train_y) # 训练模型
pre_y = model.predict(test_x) # 测试模型
mse.append(mean_squared_error(test_y, pre_y.flatten())) # 计算 MSE
m = m + 1
print("MSE 计算结果: ", mse)
# 绘图
plt.plot([i for i in range(1, m_max + 1)], mse, 'r')
plt.scatter([i for i in range(1, m_max + 1)], mse)
# 绘制图名称等
plt.title("MSE of m degree of polynomial regression")
plt.xlabel("m")
plt.ylabel("MSE")
MSE 计算结果: [1088092.9621201046, 481951.27857828484, 478840.8575107471, 477235.9140442428, 484657.87153138855, 509758.1526412842, 344204.1969956556, 429874.9229308078, 8281846.231771571, 146298201.8473966]
Text(0, 0.5, 'MSE')

从误差结果可以看到,次数取2到8误差基本稳定,没有明显的减少了,但其实你试试就知道,次数选择3的时候,预测的销量是6213亿元,次数选择5的时候,预测的销量是9029亿元,对于销售量来说,这个范围已经够大的了。我也就斗胆猜到9029亿元,我的胆量也就预测到这里了,破万亿就太夸张了,欢迎胆子大的同学留下你们的预测结果,让我们11月11日,拭目以待吧。
NO.7 总结最后
希望这篇文章带着对 Python 的多项式回归和 Plotly可视化绘图还不熟悉的同学一起练习一下。

技术交流
欢迎转载、收藏、有所收获点赞支持一下!

以上就是据Python爬虫不靠谱预测可知今年双十一销售额将超过6000亿元的详细内容,更多关于Python 爬虫预测的资料请关注我们其它相关文章!
相关推荐
-
基于Python爬取京东双十一商品价格曲线
一年一度的双十一就快到了,各种砍价.盖楼.挖现金的口令将在未来一个月内充斥朋友圈.微信群中.玩过多次双十一活动的小编表示一顿操作猛如虎,一看结果2毛5.浪费时间不说而且未必得到真正的优惠,双十一电商的"明降暗升"已经是默认的潜规则了.打破这种规则很简单,可以用 Python 写一个定时监控商品价格的小工具. 思路第一步抓取商品的价格存入 Python 自带的 SQLite 数据库每天定时抓取商品价格使用 pyecharts 模块绘制价格折线图,让低价一目了然 抓取京东价格 从商品详情的
-
基于Python+Appium实现京东双十一自动领金币功能
背景:做任务领金币的过程很无聊,而且每天都是重复同样的工作,非常符合自动化的定义: 工具:python,appium,Android 手机(我使用的是安卓6.0的),数据线一根: 开搞前先让手机和电脑连上同一个无线网: 1.抓取京东APP的包名和Activity 先连接手机 windows+r输入cmd进入命令行页面 输入:adb devices查看设备是否链接: 输入:adb shell pm list package -3查看手机里面的第三方安装包: 很明显可以看出来京东的package是:
-

自制Python淘宝秒杀抢购脚本双十一百分百中
大家好,我是不学前端的前端程序员, 事情是这个样子的,前几天不是双十一预购秒杀嘛 由于我女朋友比较笨,手速比较慢,就一直抢不到,她没抢到特价商品就不开心, 她不开心,我也就不能跟着开心,就别提看6号的全球总决赛了 为了解决这个问题,就决定写一个自动定时抢购的脚本. 第一步: 首先我的思路很简单,就是让"程序"帮我们自动打开浏览器,进入淘宝,然后到购物车等待抢购时间,自动购买并支付. 第二步: 导入模块,我们需要一个时间模块,抢购的时间,还有一个Python的自动化操作. 代码如下: i
-
据Python爬虫不靠谱预测可知今年双十一销售额将超过6000亿元
不知不觉,双十一到今年已经是13个年头,每年大家都在满心期待看着屏幕上的数字跳动,年年打破记录.而 2019 年的天猫双11的销售额却被一位微博网友提前7个月用数据拟合的方法预测出来了.他的预测值是2675.37或者2689.00亿元,而实际成交额是2684亿元.只差了5亿元,误差率只有千分之一. 但如果你用同样的方法去做预测2020年的时候,发现预测是3282亿,实际却到了 4982亿.原来2020改了规则,实际上统计的是11月1到11日的销量,理论上已经不能和历史数据合并预测,但咱们就为了图
-
python爬虫之遍历单个域名
即使你没听说过"维基百科六度分隔理论",也很可能听过"凯文 • 贝肯 (Kevin Bacon)的六度分隔值游戏".在这两个游戏中,目标都是把两 个不相干的主题(在前一种情况中是相互链接的维基百科词条,而在后 一种情况中是出现在同一部电影中的演员)用一个链条(至多包含 6 个 主题,包括原来的两个主题)连接起来. 比如,埃里克 • 艾德尔和布兰登 • 弗雷泽都出现在电影<骑警杜德雷> 里,布兰登 • 弗雷泽又和凯文 • 贝肯都出现在电影<我呼吸的空
-
一个月入门Python爬虫学习,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单.容易上手. 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容. 淘宝.京东:抓取商品.评论及销量数据,对各种商品及用户的消费场景进行分析. 安居客.链家:抓取房产买卖及租售信息,分析房价变化趋势.做不同区域的房价分
-
深入理解Python爬虫代理池服务
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来.不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务. 1.问题 代理IP从何而来? 刚自学爬虫的时候没有代理IP就去西刺.快代理之类有免费代理的网站去爬,还是有个别代理能用.当然,如果你有更好的代理接口也可以自己接入. 免费代理的采集也很简单,无非就是:访问页面页面 -> 正则/xpath提取
-
基于python 爬虫爬到含空格的url的处理方法
道友问我的一个问题,之前确实没遇见过,在此记录一下. 问题描述 在某网站主页提取url进行迭代,爬虫请求主页时没有问题,返回正常,但是在访问在主页提取到的url时出现了400状态码(400 Bad Request). 结论 先贴出结论来,如果url里有空格的话,要把空格替换成%20,也就是url编码,否则就会出现400. 解决过程 首先百度了一下400状态码什么意思: 400页面是当用户在打开网页时,返回给用户界面带有400提示符的页面.其含义是你访问的页面域名不存在或者请求错误. 主要有两种形
-
python爬虫可以爬什么
Python爬虫可以爬取的东西有很多,Python爬虫怎么学?简单的分析下: 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单.容易上手. 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容. 淘宝.京东:抓取商品.评论及销量数据,对各种商品及用户的消费场景进行分析. 安居客.链家:抓取房产买卖
-
Python爬虫逆向分析某云音乐加密参数的实例分析
本文转自:https://blog.csdn.net/qq_42730750/article/details/108415551 前言 各大音乐平台是从何时开始收费的这个问题没有追溯过,印象中酷狗在16年就已经开始收费了,貌似当时的收费标准是付费音乐下载一首2元,会员一月8元,可以下载300首.虽然下载收费,但是还可以正常听歌.陆陆续续,各平台不仅收费,而且还更在乎版权问题,因为缺少版权,酷狗上以前收藏的音乐也不能听了,更过分的是,有些歌非VIP会员只能试听60秒(•́へ•́╬). 版权
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
Python爬虫教程使用Scrapy框架爬取小说代码示例
目录 Scrapy框架简单介绍 创建Scrapy项目 创建Spider爬虫 Spider爬虫提取数据 items.py代码定义字段 fiction.py代码提取数据 pipelines.py代码保存数据 settings.py代码启动爬虫 结果展示 Scrapy框架简单介绍 Scrapy框架是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,我们只需要少量的代码就能够快速抓取数据. 其框架如下图