Python使用Numpy实现Kmeans算法的步骤详解
目录
- Kmeans聚类算法介绍:
- 1.聚类概念:
- 2.Kmeans算法:
- 定义:
- 大概步骤:
- Kmeans距离测定方式:
- 3.如何确定最佳的k值(类别数):
- 手肘法:
- python实现Kmeans算法:
- 1.代码如下:
- 2.代码结果展示:
- 聚类可视化图:
- 手肘图:
- 运行结果:
- 文章参考:
Kmeans聚类算法介绍:
1.聚类概念:
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。
2.Kmeans算法:
定义:
kmeans算法又名k均值算法,K-means算法中的k表示的是聚类为k个簇,means代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心,即用每一个的类的质心对该簇进行描述。
大概步骤:
- 设置初始类别中心和类别数
- 根据类别中心对全部数据进行类别划分:每个点分到离自己距离最小的那个类
- 重新计算当前类别划分下每个类的中心:例如可以取每个类别里所有的点的平均值作为新的中心。如何求多个点的平均值? 分别计算X坐标的平均值,y坐标的平均值,从而得到新的点。注意:类的中心可以不是真实的点,虚拟的点也不影响。
- 在新的类别中心下继续进行类别划分;
- 如果连续两次的类别划分结果不变则停止算法; 否则循环2~5。例如当类的中心不再变化时,跳出循环。
Kmeans距离测定方式:
欧式距离:

曼哈顿距离:

余弦相似度:
A与B表示向量(x1,y1),(x2,y2)
分子为A与B的点乘,分母为二者各自的L2相乘,即将所有维度值的平方相加后开方。

3.如何确定最佳的k值(类别数):
本文选取手肘法
手肘法:
对于每一个k值,计算它的误差平方和(SSE):

其中N是点的个数,Xi 是第i 个点,ci 是Xi 对应的中心。
- 随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。
- 当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数
python实现Kmeans算法:
1.代码如下:
import numpy as np
import matplotlib.pyplot as plt
import math
k = eval(input("请输入想要划分的类别个数")) #规定类别数
n = eval(input("请输入要循环的次数"))#规定循环次数
sw = eval(input("请输入想要查询的元素在数据中的位置"))
def readdata():#获取data数据中坐标值
data = np.loadtxt("E:\\Python\\Lab4\\Lab4.dat")#读取dat数据
x_data = data[:,0]#横坐标
y_data = data[:,1]#纵坐标
return data,x_data,y_data
def init(k):#初始化生成k个随机类别中心
data,x_data,y_data = readdata()
class_center = []
for i in range(k):
#在数据的最大值与最小值间给出随机值
x = np.random.randint(np.min(x_data),np.max(x_data))
y = np.random.randint(np.min(y_data),np.max(y_data))
class_center.append(np.array([x,y]))#以数组方式添加,方便后面计算距离
return class_center
def dist(a,b):#计算两个坐标间的欧氏距离
dist = math.sqrt(math.pow((a[0] - b[0]),2) + math.pow((a[1] - b[1]),2))
return dist
def dist_rank(center,data):#得到与类中心最小距离的类别位置索引
tem = []
for m in range(k):
d = dist(data, center[m])
tem.append(d)
loc = tem.index(min(tem))
return loc
def means(arr):#计算类的平均值当作类的新中心
sum_x,sum_y =0,0
for n in arr:
sum_x += n[0]
sum_y += n[1]
mean_x = sum_x / len(arr)
mean_y = sum_y / len(arr)
return [mean_x,mean_y]
def divide(center,data):#将每一个二维坐标分到与之欧式距离最近的类里
cla_arr = [[]]
for i in range(k-1):#创建与k值相同维度的空数组存取坐标
cla_arr.append([])
for j in range(len(data)):
loc = dist_rank(center,data[j])
cla_arr[loc].append(list(data[j]))
return cla_arr
def new_center(cla):#计算每类平均值更新类中心
new_cen = []
for g in range(k):
new = means(cla[g])
new_cen.append(new)
return new_cen
def index_element(arr,data,sw):#索引第sw个元素对应的类别
index = []
for i in range(len(data)):#遍历每一个数据
for j in range(k):#遍历每一个类别
tem = arr[j]
for d in range(len(tem)):#遍历类别内的每一个数据
if data[i][0] == tem[d][0] and data[i][1] == tem[d][1]:#如果横纵坐标数值都相等
index.append((j + 1))#归为j+1类
else:
continue
return index[sw]
def Kmeans(n,sw):#获取n次更新后类别中心以及第sw个元素对应的类别
data, x_data, y_data = readdata()#读取数据
center = init(k) # 获取初始类别中心
while n > 0:
cla_arr = divide(center,data)# 将数据分到随机选取的类中心的里
center = new_center(cla_arr)#更新类别中心
n -= 1
sse1 = 0
for j in range(k):
for i in range(len(cla_arr[j])): # 计算每个类里的误差平方
# 计算每个类里每个元素与元素中心的误差平方
dist1 = math.pow(dist(cla_arr[j][i], center[j]), 2)
sse1 += dist1
sse1 = sse1 / len(data)
index = index_element(cla_arr,data,sw)
return center,index,sse1,cla_arr
center_l, index,sse1, cla_arr = Kmeans(n,sw)
print("类别中心为:",center_l)
print("所查元素属于类别:",index)
print('k值为{0}时的误差平方和为{1}'.format(k,sse1))#format格式化占位输出误差平方和
def visualization(cla):#聚类可视化展现
cla_x = [[]]
cla_y = [[]]
for m in range(k-1):#创建与k值相同维度的空数组存取x坐标和y坐标
cla_x.append([])
cla_y.append([])
for i in range(k):#遍历k次读取k个类别
for j in cla[i]:#遍历每一类存取横纵坐标
cla_x[i].append(j[0])
cla_y[i].append(j[1])
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif']=['SimHei']#解决中文不能显示的问题
plt.figure()
plt.xlabel("x")
plt.ylabel("y")
plt.title("聚类图")
plt.scatter(cla_x[0],cla_y[0],c = 'r',marker = 'h')
plt.scatter(cla_x[1], cla_y[1], c='y', marker='.')
plt.scatter(cla_x[2], cla_y[2], c='g', marker='o')
plt.scatter(cla_x[3], cla_y[3], c='b', marker=',')
plt.scatter(cla_x[4], cla_y[4], c='k', marker='p')
plt.show()
visualization(cla_arr)
def hand():#画出手肘图
#sse列表是循环次数为3,改变k从2到8一个一个人工测得存入
sse = [17.840272113687078,12.116153021227769,8.563862232332205,4.092534331364449,3.573312882789776,3.42794767600246,3.2880646083752185]
x = np.linspace(2,8,7)#创建等间距大小为7的数组
plt.xlabel("k值")#横坐标名称
plt.ylabel("误差平方和")#纵坐标名称
plt.title("手肘图")#曲线名
plt.plot(x,sse)#画出曲线
plt.show()
hand()
2.代码结果展示:
聚类可视化图:
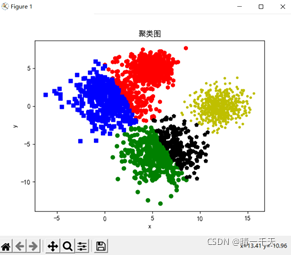
手肘图:

运行结果:

文章参考:
手肘法:K-means聚类最优k值的选取_qq_15738501的博客-CSDN博客_kmeans聚类k的选取
matplotpb.pyplot.scatter散点图的画法:
PYthon——plt.scatter各参数详解_yuanCruise-CSDN博客_plt.scatter
到此这篇关于Python使用Numpy实现Kmeans算法的文章就介绍到这了,更多相关Python Kmeans算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现的KMeans聚类算法实例分析
本文实例讲述了Python实现的KMeans聚类算法.分享给大家供大家参考,具体如下: 菜鸟一枚,编程初学者,最近想使用Python3实现几个简单的机器学习分析方法,记录一下自己的学习过程. 关于KMeans算法本身就不做介绍了,下面记录一下自己遇到的问题. 一 .关于初始聚类中心的选取 初始聚类中心的选择一般有: (1)随机选取 (2)随机选取样本中一个点作为中心点,在通过这个点选取距离其较大的点作为第二个中心点,以此类推. (3)使用层次聚类等算法更新出初始聚类中心 我一开始是使用numpy
-
python实现kMeans算法
聚类是一种无监督的学习,将相似的对象放到同一簇中,有点像是全自动分类,簇内的对象越相似,簇间的对象差别越大,则聚类效果越好. 1.k均值聚类算法 k均值聚类将数据分为k个簇,每个簇通过其质心,即簇中所有点的中心来描述.首先随机确定k个初始点作为质心,然后将数据集分配到距离最近的簇中.然后将每个簇的质心更新为所有数据集的平均值.然后再进行第二次划分数据集,直到聚类结果不再变化为止. 伪代码为 随机创建k个簇质心 当任意一个点的簇分配发生改变时: 对数据集中的每个数据点: 对
-
Python实现的Kmeans++算法实例
1.从Kmeans说起 Kmeans是一个非常基础的聚类算法,使用了迭代的思想,关于其原理这里不说了.下面说一下如何在matlab中使用kmeans算法. 创建7个二维的数据点: 复制代码 代码如下: x=[randn(3,2)*.4;randn(4,2)*.5+ones(4,1)*[4 4]]; 使用kmeans函数: 复制代码 代码如下: class = kmeans(x, 2); x是数据点,x的每一行代表一个数据:2指定要有2个中心点,也就是聚类结果要有2个簇. class将是一个具有7
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
Kmeans均值聚类算法原理以及Python如何实现
第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两个质心分为两堆就对了.如下图所示: 第二步.根据距离进行分类 红色和蓝色的点代表了我们随机选取的质心.既然我们要让这一堆点的分为两堆,且让分好的每一堆点离其质心最近的话,我们首先先求出每一个点离质心的距离.假如说有一个点离红色的质心比例蓝色的质心更近,那么我们则将这个
-
Python机器学习之Kmeans基础算法
一.K-means基础算法简介 k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇.聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集. 二.算法过程 K-means中心思想:事先确定常数K,常数K意味着最终的聚类(或者叫簇)类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样
-
Python使用Numpy实现Kmeans算法的步骤详解
目录 Kmeans聚类算法介绍: 1.聚类概念: 2.Kmeans算法: 定义: 大概步骤: Kmeans距离测定方式: 3.如何确定最佳的k值(类别数): 手肘法: python实现Kmeans算法: 1.代码如下: 2.代码结果展示: 聚类可视化图: 手肘图: 运行结果: 文章参考: Kmeans聚类算法介绍: 1.聚类概念: 将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类.由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异.
-
用Python实现简单的人脸识别功能步骤详解
前言 让我的电脑认识我,我的电脑只有认识我,才配称之为我的电脑! 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比较高,我们也可以节约在这方面花
-
Python中八大图像特效算法的示例详解
目录 0写在前面 1毛玻璃特效 2浮雕特效 3油画特效 4马赛克特效 5素描特效 6怀旧特效 7流年特效 8卡通特效 0 写在前面 图像特效处理是基于图像像素数据特征,将原图像进行一定步骤的计算——例如像素作差.灰度变换.颜色通道融合等,从而达到期望的效果.图像特效处理是日常生活中应用非常广泛的一种计算机视觉应用,出现在各种美图软件中,这些精美滤镜背后的数学原理都是相通的,本文主要介绍八大基本图像特效算法,在这些算法基础上可以进行二次开发,生成更高级的滤镜. 本文采用面向对象设计,定义了一个图像
-
Python中numpy数组的计算与转置详解
目录 前言 1.numpy数组与数的运算 2.numpy相同尺寸的数组运算 3.numpy不同尺寸的数组计算 4.numpy数组的转置 总结: 前言 本文主要讲述numpy数组的计算与转置,讲相同尺寸数组的运算与不同尺寸数组的运算,同时介绍数组转置的三种方法. numpy数组的操作比较枯燥,但是都很实用,在很多机器学习.深度学习算法中都会使用到,对numpy数组的一些操作. 1.numpy数组与数的运算 主要包括数组与数的加减乘除运算,废话不多说,看代码: import numpy as np
-
python实现微信跳一跳辅助工具步骤详解
说明 1.windows上安装安卓模拟器,安卓版本5.1以上 2.模拟器里下载安装最新的微信6.6.1 3.最好使用python2.7,python3的pyhook包有bug,解决比较麻烦 步骤 1.windows上安装python2.7,配置好环境变量和pip 2.到这个网站下载对应版本的pyHook和pywin32 http://www.lfd.uci.edu/~gohlke/pythonlibs 2.打开cmd,安装下载好的whl文件和其他库 pip install pywin32-221
-
OpenCV实现无缝克隆算法的步骤详解
目录 一.概述 二.函数原型 三.OpenCV源码 1.源码路径 2.源码代码 四.效果图像示例 一.概述 借助无缝克隆算法,您可以从一张图像中复制一个对象,然后将其粘贴到另一张图像中,从而形成一个看起来无缝且自然的构图. 二.函数原型 给定一个原始彩色图像,可以无缝混合该图像的两个不同颜色版本. void cv::colorChange (InputArray src, InputArray mask, OutputArray dst, float red_mul=1.0f, float gr
-
OpenCV实现图像去噪算法的步骤详解
目录 一.函数参考 1.Primal-dual算法 2.非局部均值去噪算法 三.OpenCV源码 1.源码路径 2.源码代码 四.效果图像示例 一.函数参考 1.Primal-dual算法 Primal-dual algorithm是一种用于解决特殊类型的变分问题的算法(即找到一个函数来最小化一些泛函). 特别是由于图像去噪可以看作是变分问题,因此可以使用原始对偶算法进行去噪,这正是该算法所实现的. cv::denoise_TVL1 (const std::vector< Mat > &
-
Python实现的数据结构与算法之队列详解
本文实例讲述了Python实现的数据结构与算法之队列.分享给大家供大家参考.具体分析如下: 一.概述 队列(Queue)是一种先进先出(FIFO)的线性数据结构,插入操作在队尾(rear)进行,删除操作在队首(front)进行. 二.ADT 队列ADT(抽象数据类型)一般提供以下接口: ① Queue() 创建队列 ② enqueue(item) 向队尾插入项 ③ dequeue() 返回队首的项,并从队列中删除该项 ④ empty() 判断队列是否为空 ⑤ size() 返回队列中项的个数 队
-
Python实现的数据结构与算法之快速排序详解
本文实例讲述了Python实现的数据结构与算法之快速排序.分享给大家供大家参考.具体分析如下: 一.概述 快速排序(quick sort)是一种分治排序算法.该算法首先 选取 一个划分元素(partition element,有时又称为pivot):接着重排列表将其 划分 为三个部分:left(小于划分元素pivot的部分).划分元素pivot.right(大于划分元素pivot的部分),此时,划分元素pivot已经在列表的最终位置上:然后分别对left和right两个部分进行 递归排序. 其中
-
Python实现的数据结构与算法之链表详解
本文实例讲述了Python实现的数据结构与算法之链表.分享给大家供大家参考.具体分析如下: 一.概述 链表(linked list)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接. 根据结构的不同,链表可以分为单向链表.单向循环链表.双向链表.双向循环链表等.其中,单向链表和单向循环链表的结构如下图所示: 二.ADT 这里只考虑单向循环链表ADT,其他类型的链表ADT大同小异.单向循环链表ADT(抽象数据类型)一般提供以下接口: ① SinCycLin