python爬虫中url管理器去重操作实例
当我们需要有一批货物需要存放时,最好的方法就是有一个仓库进行保管。我们可以把URL管理器看成一个收集了数据的大仓库,而下载器就是这个仓库货物的搬运者。关于下载器的问题,我们暂且不谈。本篇主要讨论的是在url管理器中,我们遇到重复的数据应该如何识别出来,避免像仓库一样过多的囤积相同的货物。听起来是不是很有意思,下面我们一起进入今天的学习。
URL管理器到底应该具有哪些功能?
- URL下载器应该包含两个仓库,分别存放没有爬取过的链接和已经爬取过的链接。
- 应该有一些函数负责往上述两个仓库里添加链接
- 应该有一个函数负责从新url仓库中随机取出一条链接以便下载器爬取
- URL下载器应该能识别重复的链接,已经爬取过的链接就不需要放进仓库了
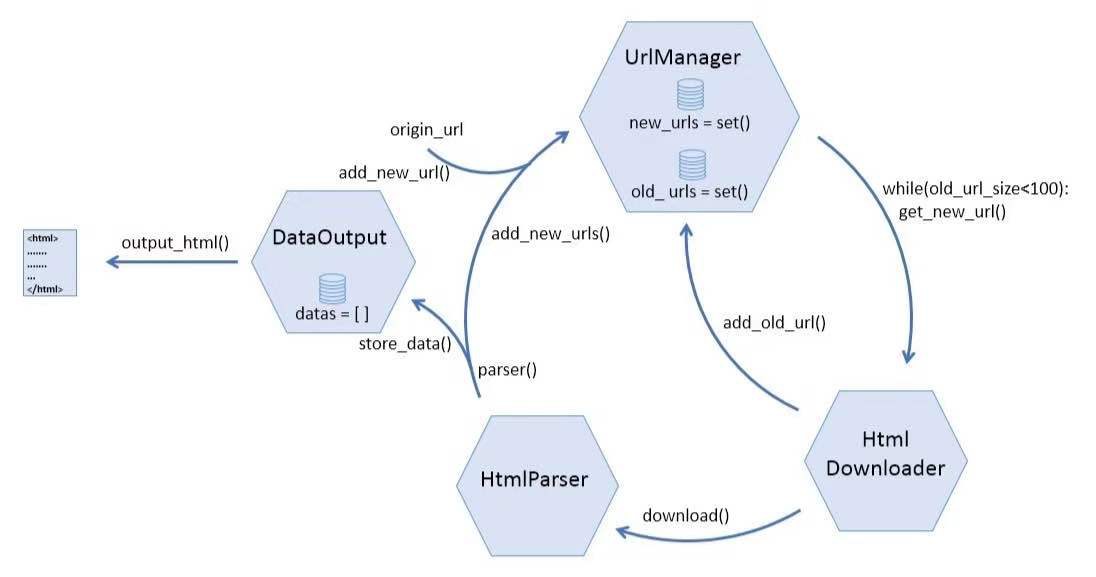
如果一个URL管理器能够具有以上4点功能,也算是“麻雀虽小,五脏俱全”了。然而,链接去重这个功能,应该怎么实现?
链接去重是关系爬虫效率的一个比较关键的点,尤其是爬取的数据量极大的时候。在这个简单的例子里,由于数据量较少,我们不需要太过复杂的算法,直接借助于python的set()函数即可,该函数可以生成一个集合对象,其元素不可重复。
根据以上分析,URL管理器的w代码如下:
'''
UrlManager
class UrlManager(object):
def __init__(self):
#初始化的时候就生成两个url仓库
self.new_urls = set()
self.old_urls = set()
#判断新url仓库中是否还有没有爬取的url
def has_new_url(self):
return len(self.new_urls)
#从new_url仓库获取一个新的url
def get_new_url(self):
return self.new_urls.pop()
def add_new_url(self, url): #这个函数后来用不到了……
'''
将一条url添加到new_urls仓库中
parm url: str
return:
if url is None:
return
#只需要判断old_urls中没有该链接即可,new_urls在添加的时候会自动去重
if url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
将多条url添加到new_urls仓库中
parm url: 可迭代对象
print "start add_new_urls"
if urls is None or len(urls) == 0:
for url in urls:
self.add_new_url(url)
def add_old_url(self, url):
self.old_urls.add(url)
print "add old url succefully"
#获取已经爬取过的url的数目
def old_url_size(self):
return len(self.old_urls)
尝试过以上代码的小伙伴,已经成功学会用url管理器筛选重复的数据了。相信大家经过今天的学习,已经能够了解url的基本功能和简单的使用。
到此这篇关于python爬虫中url管理器去重操作实例的文章就介绍到这了,更多相关python爬虫中url管理器如何去重内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫中url管理器去重操作实例
当我们需要有一批货物需要存放时,最好的方法就是有一个仓库进行保管.我们可以把URL管理器看成一个收集了数据的大仓库,而下载器就是这个仓库货物的搬运者.关于下载器的问题,我们暂且不谈.本篇主要讨论的是在url管理器中,我们遇到重复的数据应该如何识别出来,避免像仓库一样过多的囤积相同的货物.听起来是不是很有意思,下面我们一起进入今天的学习. URL管理器到底应该具有哪些功能? URL下载器应该包含两个仓库,分别存放没有爬取过的链接和已经爬取过的链接. 应该有一些函数负责往上述两个仓库里添加链接 应该
-
python爬虫模块URL管理器模块用法解析
这篇文章主要介绍了python爬虫模块URL管理器模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 URL管理器模块 一般是用来维护爬取的url和未爬取的url已经新添加的url的,如果队列中已经存在了当前爬取的url了就不需要再重复爬取了,另外防止造成一个死循环.举个例子 我爬www.baidu.com 其中我抓取的列表中有music.baidu.om,然后我再继续抓取该页面的所有链接,但是其中含有www.baidu.com,可以想
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
celery在python爬虫中定时操作实例讲解
使用定时功能对于我们想要快速获取某个数据来说,是一个非常好的方法.这样我们就不用苦苦守在电脑屏幕前,只为蹲到某个想要的东西.在之前我们已经讲过time函数进行定时操作,这算是time函数的比较基础的一个用法了.其实定时功能同样可以用celery实现,具体的方法我们往下看: 爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能.在上述基础上,我们将`tasks.py`文件改成如下内容 from celery impor
-
Python爬虫中urllib3与urllib的区别是什么
目录 urllib库 urllib.request模块 Request对象 1 . 请求头添加 2. 操作cookie 3. 设置代理 urllib.parse模块 urllib.error模块 urllib.robotparse模块 网络库urllib3 网络请求 GET请求 POST请求 HTTP响应头 上传文件 超时处理 urllib库 urllib 是一个用来处理网络请求的python标准库,它包含4个模块. urllib.request---请求模块,用于发起网络请求 urllib.p
-
Python with语句上下文管理器两种实现方法分析
本文实例讲述了Python with语句上下文管理器.分享给大家供大家参考,具体如下: 在编程中会经常碰到这种情况:有一个特殊的语句块,在执行这个语句块之前需要先执行一些准备动作:当语句块执行完成后,需要继续执行一些收尾动作.例如,文件读写后需要关闭,数据库读写完毕需要关闭连接,资源的加锁和解锁等情况. 对于这种情况python提供了上下文管理器(Context Manager)的概念,可以通过上下文管理器来定义/控制代码块执行前的准备动作,以及执行后的收尾动作. 一.为何使用上下文管理器 1.
-
python爬虫中抓取指数的实例讲解
有一些数据我们是没法直观的查看的,需要通过抓取去获得.听到指数这个词,有的小伙伴们觉得很复杂,似乎只在股票的时候才听说的,比如一些数据的涨跌分析都是比较棘手的问题.不过指数对于我们的数据分析还是很有帮助的,今天小编就python爬虫中抓取指数得方法给大家带来讲解. 刚好这几天需要用到这个爬虫,结果发现baidu指数的请求有点变化,所以就改了改: import requests import sys import time word_url = 'http://index.baidu.com/ap
-
盘点Python 爬虫中的常见加密算法
目录 前言 1. 基础常识 2. Base64伪加密 3. MD5加密 4. AES/DES对称加密 1.密钥 2.填充 3.模式 前言 今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征.加密的方式有哪些等等,知道了这些之后对于我们逆向破解这些加密的参数会起到不少的帮助! 相信大家在数据抓取的时候,会碰到很多加密的参数,例如像是"token"."sign"等等,今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征.
-
python爬虫中多线程的使用详解
queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue.python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性. #多线程实战栗子(糗百) #用一个队列Queue对象, #先产生所有url,put进队列: #开启多线程,把q
-
python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作.分享给大家供大家参考,具体如下: 一.背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验