python爬虫之代理ip正确使用方法实例
目录
- 代理ip原理
- 输入网址后发生了什么呢?
- 代理ip做了什么呢?
- 为什么要用代理呢?
- 爬虫代码中使用代理ip
- 检验代理ip是否生效
- 未生效问题排查
- 1.请求协议不匹配
- 2.代理失效
- 总结
主要内容:代理ip使用原理,怎么在自己的爬虫里设置代理ip,怎么知道代理ip是否生效,没生效的话哪里出了问题,个人使用的代理ip(付费)。
代理ip原理
输入网址后发生了什么呢?
1.浏览器获取域名
2.通过DNS协议获取域名对应服务器的ip地址
3.浏览器和对应的服务器通过三次握手建立TCP连接
4.浏览器通过HTTP协议向服务器发送数据请求
5.服务器将查询结果返回给浏览器
6.四次挥手释放TCP连接
7.浏览器渲染结果
其中涉及到了:
应用层:HTTP和DNS
传输层:TCP UDP
网络层:IP ICMP ARP
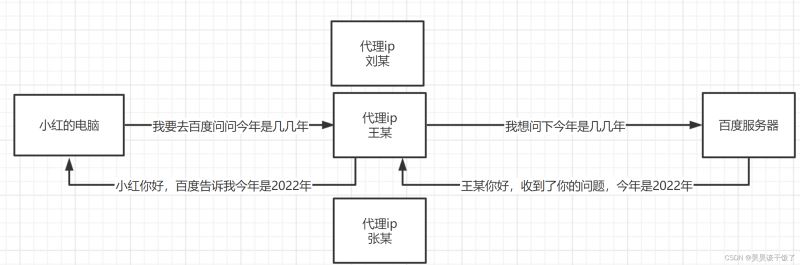
代理ip做了什么呢?
简单来说,就是:
原本你的访问

使用代理后你的访问

为什么要用代理呢?
因为我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么美好,然而一杯茶的功夫可能就会出现错误,比如403 Forbidden,这时候打开网页一看,可能会看到“您的IP访问频率太高”这样的提示。出现这种现象的原因是网站采取了一些反爬虫措施。比如,服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封IP。而代理ip就避免了这个问题:
爬虫代码中使用代理ip
就像是请求时伪装头一样,伪装ip,注意是 { }
proxies = {
'https':'117.29.228.43:64257',
'http':'117.29.228.43:64257'
}
requests.get(url, headers=head, proxies=proxies, timeout=3) #proxies
检验代理ip是否生效
我们访问一个网站,这个网站会返回我们的ip地址:
print(requests.get('http://httpbin.org/ip', proxies=proxies, timeout=3).text)
我们看一下我使用了四个不同的代理ip,全部生效了,

未生效问题排查
如果你返回的还是本机地址,99%试一下两种情况之一:
1.请求协议不匹配
简单来说就是,如果你请求的是http,就要用http的协议,如果是https,就要用https的协议。

如果我请求是http ,但只有https,就会使用本机ip。
2.代理失效
便宜没好货,好货不便宜。如果确实大规模爬虫是必须的话,还是买代理ip比较好,网上广告满天飞的某些代理实际性价比有些低了,自己常用的就不分享了,总是被当成广告,推荐一些其他的比如:
1、IPIDEA
2、Stormproxies
3、YourPrivateProxy
4、GeoSurf
当然还有大家熟知的快代理,西刺等等,都有一些免费代理可供使用。
总结
到此这篇关于python爬虫之代理ip正确使用方法的文章就介绍到这了,更多相关python爬虫代理ip内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫代理IP池实现方法
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来.不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务. 1.问题 代理IP从何而来? 刚自学爬虫的时候没有代理IP就去西刺.快代理之类有免费代理的网站去爬,还是有个别代理能用.当然,如果你有更好的代理接口也可以自己接入. 免费代理的采集也很简单,无非就是:访问页面页面 -> 正则/xpath提
-
Python爬虫设置代理IP(图文)
在爬虫的过程中,我们经常会遇见很多网站采取了防爬取技术,或者说因为自己采集网站信息的强度和采集速度太大,给对方服务器带去了太多的压力. 如果你一直用同一个代理ip爬取这个网页,很有可能ip会被禁止访问网页,所以基本上做爬虫的都躲不过去ip的问题. 1.我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常爬取数据,一切看起来都是那么美好,然而不久之后可能会出现错误,比如 403 Forbidden,这时候你打开网页一看,可能会看到"您的 IP 访问频率太高"这样的提示.出现这
-
Python代理IP爬虫的新手使用教程
前言 Python爬虫要经历爬虫.爬虫被限制.爬虫反限制的过程.当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程.爬虫的初级阶段,添加headers和ip代理可以解决很多问题. 本人自己在爬取豆瓣读书的时候,就以为爬取次数过多,直接被封了IP.后来就研究了代理IP的问题. (当时不知道什么情况,差点心态就崩了...),下面给大家介绍一下我自己代理IP爬取数据的问题,请大家指出不足之处. 问题 这是我的IP被封了,一开始好好的,我还以为是我的代码问题了 思路: 从网上查找了
-
Python爬虫使用代理IP的实现
使用爬虫时,如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作.这时候代理 IP 能够给我们带来很大的便利,不管网站怎么封,只要能找到一个新的代理 IP 就可以继续进行下一步的研究. 目前很多网站都提供了一些免费的代理 IP 供我们使用,当然付费的会更好用一点.本文除了展示怎样使用代理 IP,也正好体验一下前面文章中搭建的代理 IP 池,不知道的可以点击这里:Python搭建代理IP池(一)- 获取 IP.只要访问代理池提供的接口
-
Python爬虫常用小技巧之设置代理IP
设置代理IP的原因 我们在使用Python爬虫爬取一个网站时,通常会频繁访问该网站.假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,这样便不会出现因为频繁访问而导致禁止访问的现象. 我们在学习Python爬虫的时候,也经常会遇见所要爬取的网站采取了反爬取技术导致爬取失败.高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,所以下面这篇文
-
python 爬虫 批量获取代理ip的实例代码
实例如下所示: import urllib.request import os, re,sys,time try: from StringIO import StringIO except ImportError: from io import StringIO loca = re.compile(r"""ion":"\D+", "ti""") #伪装成浏览器 header = {'User-Agent':
-
Python爬虫设置代理IP的方法(爬虫技巧)
在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术,高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP. (一)配置环境 安装requests库 安装bs4库 安装lxml库 (二)代码展示 # IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/ # 仅仅爬取首页IP地址就足够一般使用 from bs4 import BeautifulSoup
-
python爬虫设置每个代理ip的简单方法
python爬虫设置每个代理ip的方法: 1.添加一段代码,设置代理,每隔一段时间换一个代理. urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy.假如一个网站它会检测某一段时间某个 IP 的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,网站君都不知道是谁在捣鬼了,这酸爽! 下面一段代码说明了代理的设置用法. import urllib2 enable_proxy = True proxy_h
-
python爬虫之代理ip正确使用方法实例
目录 代理ip原理 输入网址后发生了什么呢? 代理ip做了什么呢? 为什么要用代理呢? 爬虫代码中使用代理ip 检验代理ip是否生效 未生效问题排查 1.请求协议不匹配 2.代理失效 总结 主要内容:代理ip使用原理,怎么在自己的爬虫里设置代理ip,怎么知道代理ip是否生效,没生效的话哪里出了问题,个人使用的代理ip(付费). 代理ip原理 输入网址后发生了什么呢? 1.浏览器获取域名 2.通过DNS协议获取域名对应服务器的ip地址 3.浏览器和对应的服务器通过三次握手建立TCP连接 4.浏览器
-
python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检测是否可用,可用保存,通过函数get_proxies可以获得ip,如:{'HTTPS': '106.12.7.54:8118'} 下面放上源代码,并详细注释: import requests from lxml import etree from requests.packages import u
-
python爬虫模拟浏览器的两种方法实例分析
本文实例讲述了python爬虫模拟浏览器的两种方法.分享给大家供大家参考,具体如下: 爬虫爬取网站出现403,因为站点做了防爬虫的设置 一.Herders 属性 爬取CSDN博客 import urllib.request url = "http://blog.csdn.net/hurmishine/article/details/71708030"file = urllib.request.urlopen(url) 爬取结果 urllib.error.HTTPError: HTTP
-
Python实现爬虫设置代理IP和伪装成浏览器的方法分享
1.python爬虫浏览器伪装 #导入urllib.request模块 import urllib.request #设置请求头 headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") #创建一个opener opene
-
python爬虫利用代理池更换IP的方法步骤
0. 前言 周日在爬一个国外网站的时候,发现用协程并发请求,并且请求次数太快的时候,会出现对方把我的服务器IP封掉的情况.于是网上找了一下开源的python代理池,这里选择的是star数比较多的proxy_pool 1. 安装环境 # 安装python虚拟环境, python环境最好为python3.6,再往上的话,安装依赖时会报错 sudo apt update sudo apt install python3.6 pip3 install virtualenv virtualenv venv
-
Python 快速验证代理IP是否有效的方法实现
有时候,我们需要用到代理IP,比如在爬虫的时候,但是得到了IP之后,可能不知道怎么验证这些IP是不是有效的,这时候我们可以使用Python携带该IP来模拟访问某一个网站,如果多次未成功访问,则说明这个代理是无效的. 代码如下: import requests import random import time http_ip = [ '118.163.13.200:8080', '222.223.182.66:8000', '51.158.186.242:8811', '171.37.79.12