python数据分析之公交IC卡刷卡分析
一、背景
交通大数据是由交通运行管理直接产生的数据(包括各类道路交通、公共交通、对外交通的刷卡、线圈、卡口、GPS、视频、图片等数据)、交通相关行业和领域导入的数据(气象、环境、人口、规划、移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博、微信、论坛、广播电台等提供的文字、图片、音视频等数据)构成的。
现在给出了一个公交刷卡样例数据集,包含有交易类型、交易时间、交易卡号、刷卡类型、线路号、车辆编号、上车站点、下车站点、驾驶员编号、运营公司编号等。试导入该数据集并做分析。
二、任务要求
1.分别计算早上7点前和晚上10点之后的公共交通上车刷卡量;
2.绘制并输出当天各小时公交刷卡量变化的折线图;
3.构造一个乘客搭乘时间分析函数,计算各小时区间乘客的平均公交搭乘时间及其标准差;
4.绘制并输出不同类型的一卡通交易数量及其占比的饼图;
5.分别构造线路类、司机类和车辆类,将线路编号1101–1120的线路及其所对应的司机和车辆信息输出为20个txt文档,并保存到一个文件夹中;
6.分析搭载乘客情况,确定服务乘客人次最多的10个司机、10条线路和10台车辆。
三、使用步骤
1.引入库
代码如下:
from numpy import * import pandas as pd import matplotlib.pyplot as plt from collections import Counter
2.导入数据
代码如下:
# 导入csv文件
ICdata = pd.read_csv('D:/人工智能编程语言/Python - 作业4/ICData.csv', sep=',', encoding='utf-8')
3.任务一
代码如下:
# 1.分别计算早上7点前和晚上10点之后的公共交通上车刷卡量;
ICdata['交易时间'] = pd.to_datetime(ICdata['交易时间'], format='%Y/%m/%d %H:%M:%S') # 将字符串类型转换为datetime类型
paytime1 = ICdata[ICdata.交易时间 < '2018/4/1 07:00:00']
paytime2 = ICdata[ICdata.交易时间 > '2018/4/1 22:00:00']
print('早上七点前的刷卡量为:', paytime1.交易时间.count()) # 输出在早上七点前的刷卡量
print('晚上十点后的刷卡量为:', paytime2.交易时间.count()) # 输出在晚上十点后的刷卡量
print('\n')
输出:

4.任务二
代码如下:
# 2.绘制并输出当天各小时公交刷卡量变化的折线图
timetable = []
ICdata['hour'] = ICdata['交易时间'].dt.hour # 加多一列hour,并赋值为标准数据里的小时
time = ICdata.groupby(['hour']).count() # 通过data.groupby(‘hour').count()按小时进行分组,并统计数目
timetable = time.iloc[:, 2] # 取出一列数据
timetable.plot() # 画出折线图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 防止中文输出出现乱码
plt.title('当天内各小时刷卡量') # 设置总标题
plt.xlabel('Hour') # 设置x坐标标题
plt.ylabel('Amount') # 设置y坐标标题
plt.show() # 展示折线图
del ICdata['hour'] # 将hour列删除
输出:

5.任务三
代码如下:
# 3.定义一个计算乘客搭乘时间平均数和标准差的函数
def fun_time(x):
time_list = []
ICdata['hour'] = ICdata['交易时间'].dt.hour # 加多一列hour,并赋值为标准数据里的小时
t = list(ICdata['hour']) # 将hour列取出并转换为列表
for i in range(200000):
if t[i] == x: # 记录该小时内乘客的搭乘时间
time_list.append(abs(ICdata['上车站点'][i]-ICdata['下车站点'][i]))
aver = mean(time_list) # 计算平均数
std_t = std(time_list) # 计算标准差
print(x, '时内乘客搭乘的平均时间为:%.3f站 ' % aver, '标准差为:%.3f站' % std_t)
print('\n')
# 函数实现:
a = int(input("请输入一个整数代表该小时:"))
fun_time(a) # 调用fun_time函数,传入参数a
输出:

6.任务四
代码如下:
# 4.绘制并输出不同类型的一卡通交易数量及其占比的饼图
count = Counter(ICdata.iloc[:, 0]) # 统计各刷卡类型总数
list_key = [] # 创建列表存储刷卡类型
list_value = [] # 创建列表存储刷卡总数量
print('不同类型的一卡通交易数量:')
for key, value in count.items(): # 将counter类型元素分别提取到两个列表内
list_key.append(key)
list_value.append(value)
print('%5d' % key, ':', value) # 输出刷卡类型及对应数量
print('\n')
plt.figure(figsize=(6, 6), dpi=100) # 创建画布
colors = ['b', 'r', 'g', 'y'] # 设置颜色
plt.pie(list_value, labels=list_key, autopct='%1.2f%%',
colors=colors, shadow=True, startangle=150)
# autopct='%1.2f%%' 保留2位小数
# shadow=True,startangle=150 设置阴影,角度为150度
plt.legend() # 显示图例
plt.axis('equal') # 为了让显示的饼图保持圆形,需要添加axis保证长宽一样
plt.title('不同类型的一卡通交易数占比的饼图') # 添加标题
plt.show()
输出:

7.任务五
代码如下:
# 5.分别构造线路类、司机类和车辆类,将线路编号1101–1120的线路及其所对应的司机和
# 车辆信息输出为20个txt文档,并保存到一个文件夹中;
list_line=[]
for i in range(1101,1121): # 将20条线路的名称存进列表里
list_line.append(i)
class Driver: # 构造司机类
def __init__(self,driver):
self.driver = driver
class Bus: # 构造公交类
def __init__(self,bus):
self.bus = bus
class Line: # 构造线路类
def __init__(self): # 因为要根据线路得知司机和公交的信息,因此在线路类
self.driver=[] # 里添加两个列表分别存入司机和公交的信息
self.bus=[]
def add_driver(self,x):
self.driver.append(x)
def add_bus(self,y):
self.bus.append(y)
line_class=[] # 列表存20条线路对应的对象
for i in range(1101,1121):
l=Line() # 一条线路创建一个对象
for j in range(200000):
if ICdata['线路号'][j]==i: # 将对应线路的司机和公交信息存入该线路对象内
l.add_driver(ICdata['车辆编号'][j])
l.add_bus(int(ICdata['驾驶员编号'][j]))
line_class.append(l)
basepath='D:/人工智能编程语言/task4/road_line/Line' # 确定txt文件存入的路径
for i in range(20):
full_path=basepath+str(list_line[i])+'.txt' # 加上文件名和后缀
file=open(full_path,'w',encoding='UTF-8') # 创建txt文件,只写
file.write('车辆编号')
file.write(' ')
file.write('驾驶员编号\n')
for j in range(len(line_class[i].driver)): # 将对应线路的信息写入txt文件内
file.write(str(line_class[i].driver[j]))
file.write(' ')
file.write(str(line_class[i].bus[j]))
file.write('\n')
file.close()
输出:


8.任务六
代码如下:
# 6.分析搭载乘客情况,确定服务乘客人次最多的10个司机、10条线路和10台车辆。
drivers = Counter(ICdata.iloc[:, 8]) # 取出对应列并统计每个元素出现的次数
a=(drivers.most_common(10)) # 将前十个元素及出现的次数存入列表a内
print('服务人次最多的前十名司机及服务人数:')
for i in range(10):
print('%-8d'% int(a[i][0]),':','%-10d'% a[i][1])
lines = Counter(ICdata.iloc[:, 4])
b=(lines.most_common(10))
print('服务人次最多的前十条线路及服务人数:')
for i in range(10):
print('%-8d'% int(b[i][0]),':','%-10d'% b[i][1])
buses = Counter(ICdata.iloc[:, 5])
c=(buses.most_common(10))
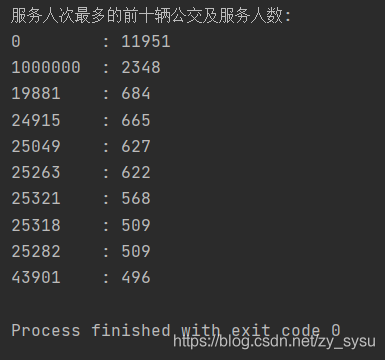
print('服务人次最多的前十辆公交及服务人数:')
for i in range(10):
print('%-8d'% int(c[i][0]),':','%-10d'% c[i][1])
输出:

四、总结
加深了对numpy,pandas和matplotlib等第三方应用库的使用。
到此这篇关于python数据分析之公交IC卡的文章就介绍到这了,更多相关python公交IC卡内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python数据分析工具之 matplotlib详解
不论是数据挖掘还是数学建模,都免不了数据可视化的问题.对于 Python 来说,matplotlib 是最著名的绘图库,它主要用于二维绘图,当然也可以进行简单的三维绘图.它不但提供了一整套和 Matlab 相似但更为丰富的命令,让我们可以非常快捷地用 python 可视化数据. matplotlib基础 # 安装 pip install matplotlib 两种绘图风格: MATLAB风格: 基本函数是 plot,分别取 x,y 的值,然后取到坐标(x,y)后,对不同的连续点进行连线. 面向对
-
Python数据分析之pandas函数详解
一.apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df)) 运行结果: 0 1 2 3 0 -0.062413 0.844813 -1.853721 -1.980717 1 -0.539628 -1.975173 -0.856597 -2.612406
-

python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat.dt.str三种属性接口(accessors),分别对应分类数据.日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷. 今天翻阅pandas官方文档总结了以下几个常用的api. 1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日.但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的. 这里先简单
-
python数据分析:关键字提取方式
TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴.使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性. TF-IDF的概念 TF-IDF有两部分,词频和逆文档频率.首先介绍词频,这个词很直观,词频表示每个词在文档或数据集中出现的频率.等式如下: TF(t)=词t在一篇文档中出现的次数/这篇文档的总词数 第二部分--逆文档频率实际上告诉了我们一个单词对文档的重要性.这是因为当计
-
Python 数据分析之逐块读取文本的实现
背景 <利用Python进行数据分析>,第 6 章的数据加载操作 read_xxx,有 chunksize 参数可以进行逐块加载. 经测试,它的本质就是将文本分成若干块,每次处理 chunksize 行的数据,最终返回一个TextParser 对象,对该对象进行迭代遍历,可以完成逐块统计的合并处理. 示例代码 文中的示例代码分析如下: from pandas import DataFrame,Series import pandas as pd path='D:/AStudy2018/pyda
-
Python实现的北京积分落户数据分析示例
本文实例讲述了Python实现的北京积分落户数据分析.分享给大家供大家参考,具体如下: 北京积分落户状况 获取数据(爬虫/文件下载)-> 分析 (维度-指标) 从公司维度分析不同公司对落户人数指标的影响 , 即什么公司落户人数最多也更容易落户 从年龄维度分析不同年龄段对落户人数指标影响 , 即什么年龄段落户人数最多也更容易落户 从百家姓维度分析不同姓对落户人数的指标影响 , 即什么姓的落户人数最多即也更容易落户 不同分数段的占比情况 # 导入库 import numpy as np import
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
大数据分析用java还是Python
大数据学java还是Python? 大数据开发既要学习Python,也要学习java. 学习大数据开发,java语言是基础,主流的大数据软件基本都是java实现的,所以java是必学的, python也是重要的爬取数据的工具,也是大数据后续提高部分需要学习的. Python简介: python是一种面向对象的,解释型的计算机语言,它的特点是语法简介,优雅,简单易学.1989年诞生,Guido(龟叔)开发. 编译型语言:代码在编译之后,编译成2进制的文件,然后计算机就可用运行了.(C,C++,C#
-
python数据分析之公交IC卡刷卡分析
一.背景 交通大数据是由交通运行管理直接产生的数据(包括各类道路交通.公共交通.对外交通的刷卡.线圈.卡口.GPS.视频.图片等数据).交通相关行业和领域导入的数据(气象.环境.人口.规划.移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博.微信.论坛.广播电台等提供的文字.图片.音视频等数据)构成的. 现在给出了一个公交刷卡样例数据集,包含有交易类型.交易时间.交易卡号.刷卡类型.线路号.车辆编号.上车站点.下车站点.驾驶员编号.运营公司编号等.试导入该数据集并做分析. 二
-
ThinkPHP框架整合微信支付之刷卡模式图文详解
本文实例讲述了ThinkPHP框架整合微信支付之刷卡模式.分享给大家供大家参考,具体如下: 大家好,这篇文章是继微信支付之Native 扫码支付 模式二之后的微信支付系列教程第四篇:微信刷卡支付 本教程跟前三篇教程不一样,所需要的类库也不一样,所以做刷卡支付的时候,与之前的方法没多少关系,大家注意一下. 下面开始介绍详细步骤! step1:下载微信刷卡支付demo,如下图: WxPayMicropayHelper:这个文件夹下就是刷卡支付微信提供的类库 demo:这个文件夹下是关于刷卡支付的详细
-
使用Python实现企业微信的自动打卡功能
上下班打卡是程序员最讨厌的东西,更讨厌的是设置了连上指定wifi打卡. 手机上有一些定时机器人之类的app,经过实际测试,全军覆没,没一个可以活着走到启动企业微信的这一步,所以还是靠自己吧. 下面就通过Python程序来实现自动打卡,原理很简单,用Python设置定时任务,然后通过adb操作手机,完成打卡. 1.准备工作 a.安装了Python,ADB驱动(安装方式及下载地址见之前文章)的电脑一台:常驻在公司的测试机一台:数据线一条. b.将手机通过数据线连接电脑,打开开发者选项中的允许USB调
-
python+selenium 简易地疫情信息自动打卡签到功能的实现代码
由于学校要求我们每天都要在官网打卡签到疫情信息,多多少少得花个1分钟操作,程序员的尊严告诉我们坚决不能手动打卡.正巧最近学了selenium,于是画了个5分钟写了个自动打卡签到地小程序. 测试环境:python3.7 , selenium,chrome浏览器 seleium和chromedriver的配置在这里就不讲了,这里放个连接 首先找到学校信息门户的登录页: http://my.hhu.edu.cn/login.portal #导入selenium中的webdriver from sele
-
Android开发实现NFC刷卡读取的两种方式
场景:NFC是目前Android手机一个主流的配置硬件项,本文主要讲解一下Android开发中,NFC刷卡的两种实现方式以及相关方法源码解析. ①:Manifest注册方式:这种方式主要是在Manifest文件对应的activity下,配置过滤器,以响应不同类型NFC Action.使用这种方式,在刷卡时,如果手机中有多个应用都存在该NFC实现方案,系统会弹出能响应NFC事件的应用列表供用户选择,用户需要点击目标应用来响应本次NFC刷卡事件.目前我公司这边项目中使用了该逻辑,比较简便,这里先贴
-
python实现钉钉机器人自动打卡天天早下班
目录 一,新建钉钉机器人 二,钉钉机器人发送消息 三,钉钉机器人实际的应用 一,新建钉钉机器人 1.钉钉群右上角点击群设置,选择智能群助手,点击添加机器人,选择自定义机器人: 2.给机器人起个名字,消息推送开启,复制出 webhook,后面会用到,勾选自定义关键词,填写关键词(关键词可以随便填写,但是一定要记住,后面会用): 二,钉钉机器人发送消息 url 就是创建机器人时的 webhook,data 中的 atMobiles 可填写多个手机号,发送的消息会直接 @ 这个人,text 的 con
-
Python实现自动化处理每月考勤缺卡数据
目录 一.效果展示 1.实现效果 2.原始数据模板 二.代码详解 1.导入库 2.定义时间处理函数 3.读取数据调整日期格式 4.计算工作日天数 5.获取缺卡名单 不管是上学还是上班都会统计考勤,有些学校或公司会对每月缺卡次数过多(比如三次以上)的人员进行处罚. 有些公司还规定对于基层员工要在工作日提交日志.管理人员要提交周报或月报,对于少提交的人员要进行处罚. 如果公司HR逐个对人员的日志或缺卡数据进行处理,将是一项耗时且无聊的工作. 本文提供了自动处理考勤和日志缺失的方法. 不用安装Pyth
-
Python实现城市公交网络分析与可视化
目录 一.数据查看和预处理 二.数据分析 一.数据查看和预处理 数据获取自高德地图API,包含了天津市公交线路和站点名称及其经纬度数据. import pandas as pd df = pd.read_excel('site_information.xlsx') df.head() 字段说明: 线路名称:公交线路的名称 上下行:0表示上行:1表示下行 站序号:公交线路上行或下行依次经过站的序号 站名称:站点名称 经度(分):站点的经度 纬度(分):站点的纬度 数据字段少,结构也比较简单,下面来
-
Python数据分析中Groupby用法之通过字典或Series进行分组的实例
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c','d','e'], index=['Joe','Steve','Wes','Jim','Travis'] ) mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'} by_column=people.grou
-
Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法
本文实例讲述了Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法.分享给大家供大家参考,具体如下: 统计两个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator #导入数据 df = pd.read_table('newdata.txt',h