使用Python爬虫爬取小红书完完整整的全过程
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于Python进击者 ,作者kuls
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
小红书
首先,我们打开之前大家配置好的charles
我们来简单抓包一下小红书小程序(注意这里是小程序,不是app)
不选择app的原因是,小红书的App有点难度,参照网上的一些思路,还是选择了小程序
1、通过charles抓包对小程序进行分析

我们打开小红书小程序,随意搜索一个关键词

按照我的路径,你可以发现列表中的数据已经被我们抓到了。
但是你以为这就结束了?
不不不

通过这次抓包,我们知道了可以通过这个api接口获取到数据
但是当我们把爬虫都写好时,我们会发现headers里面有两个很难处理的参数
"authorization"和"x-sign"
这两个玩意,一直在变化,而且不知道从何获取。
所以
2、使用mitmproxy来进行抓包
其实通过charles抓包,整体的抓取思路我们已经清晰
就是获取到"authorization"和"x-sign"两个参数,然后对url进行get请求
这里用到的mitmproxy,其实和charles差不多,都是抓包工具
但是mitmproxy能够跟Python一起执行
这就舒服很多啊
简单给大家举例子
def request(flow): print(flow.request.headers)
在mitmproxy中提供这样的方法给我们,我们可以通过request对象截取到request headers中的url、cookies、host、method、port、scheme等属性
这不正是我们想要的吗?
我们直接截取"authorization"和"x-sign" 这两个参数
然后往headers里填入
整个就完成了。
以上是我们整个的爬取思路,下面给大家讲解一下代码怎么写
其实代码写起来并不难
首先,我们必须截取到搜索api的流,这样我们才能够对其进行获取信息
if 'https://www.xiaohongshu.com/fe_api/burdock/weixin/v2/search/notes' in flow.request.url:
我们通过判断flow的request里面是否存在搜索api的url
来确定我们需要抓取的请求
authorization=re.findall("authorization',.*?'(.*?)'\)",str(flow.request.headers))[0]
x_sign=re.findall("x-sign',.*?'(.*?)'\)",str(flow.request.headers))[0]
url=flow.request.url
通过上述代码,我们就能够把最关键的三个参数拿到手了,接下来就是一些普通的解析json了。
最终,我们可以拿到自己想要的数据了
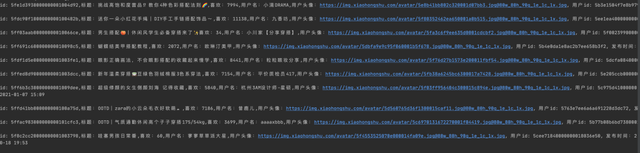
如果你想要获取到单篇数据,可以拿到文章id后抓取
"https://www.xiaohongshu.com/discovery/item/" + str(id)
这个页面headers里需要带有cookie,你随意访问一个网站都可以拿到cookie,目前看来好像是固定的
最后,可以把数据放入csv

总结
其实小红书爬虫的抓取并不是特别的难,关键在于思路以及使用的方法是什么。
到此这篇关于使用Python爬虫爬取小红书完完整整的全过程的文章就介绍到这了,更多相关Python爬取小红书内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
如何基于Python爬虫爬取美团酒店信息
一.分析网页 网站的页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码.抓取这种类型网站的页面数据,解决方案如下: 分析 Ajax,很多数据可能是经过 Ajax 请求时候获取的,所以可以分析其接口. 在XHR里可以找到,Request URL有几个关键参数,uuid和cityId是城市标识,offset偏移量可以控制翻页,分析
-
使用Python爬虫爬取小红书完完整整的全过程
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于Python进击者 ,作者kuls Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space.bilibili.com/523606542 小红书 首先,我们打开之前大家配置好的charles 我们来简单抓包一下小红书小程序(注意这里是小程序,不是app) 不选择app的原因是,小红书的App有点难度,参照网上的一些思路,还是选择了小程序 1
-
Python爬虫爬取糗事百科段子实例分享
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 1.抓取糗事百科热门段子: 2.过滤带有图片的段子: 3.实现每按一次回车显示一个段子的发布时间,发布人,段子内容,点赞数. 糗事百科是不需要登录的,所以也没必要用到Cookie,另外糗事百科有的段子是附图的,我们把图抓下来图片不便于显示,那么我们
-
python爬虫爬取淘宝商品比价(附淘宝反爬虫机制解决小办法)
因为评论有很多人说爬取不到,我强调几点 kv的格式应该是这样的: kv = {'cookie':'你复制的一长串cookie','user-agent':'Mozilla/5.0'} 注意都应该用 '' ,然后还有个英文的 逗号, kv写完要在后面的代码中添加 r = requests.get(url, headers=kv,timeout=30) 自己得先登录自己的淘宝账号才有自己登陆的cookie呀,没登录cookie当然没用 以下原博 本人是python新手,目前在看中国大学MOOC的嵩天
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
Python爬虫爬取网站图片
此次python3主要用requests,解析图片网址主要用beautiful soup,可以基本完成爬取图片功能, 爬虫这个当然大多数人入门都是爬美女图片,我当然也不落俗套,首先也是随便找了个网址爬美女图片 from bs4 import BeautifulSoup import requests if __name__=='__main__': url='http://www.27270.com/tag/649.html' headers = { "U
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()