C++超详细实现堆和堆排序过像
目录
- 有关堆
- C++实现堆
- 堆的应用
- 堆排序
有关二叉树的性质:
1. 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有 个结点.
2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 .
3. 对任何一棵二叉树, 如果度为0其叶结点个数为 , 度为2的分支结点个数为 ,则有 = +1
4. 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2 为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对 于序号为i的结点有:
1. 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
2. 若2i+1<n,左孩子序号:2i+1 若2i+1>=n则无左孩子
3. 若2i+2<n,右孩子序号:2i+2 若2i+2>=n则无右孩子
有关堆
存储结构:
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。现实中我们通常把堆(一种完全二叉树)使用顺序结构的数组来存储
堆的概念和结构:

堆的性质:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
上面这些都是复制粘贴的, 想看了随便看看。下面给出自己的一些总结:
C++实现堆
Heap.h
#pragma once
#include<iostream>
#include<assert.h>
#include<algorithm>
#include<Windows.h>
using namespace std;
typedef int DataType;
class Heap
{
public:
Heap() :a(new DataType[1]), size(0), capacity(1) {}
~Heap()
{
delete[]a;
a = nullptr;
size = capacity = 0;
}
public:
void Push(const DataType& x);
void Pop(); // 删除堆顶的数据
DataType Top()const;
bool Empty()const;
int Size()const;
void Swap(DataType& a, DataType& b);
void print();
public:
void AdjustUp(int child);
void AdjustDown(int size, int parent);
private:
DataType* a;
int size;
int capacity;
};
Heap.cpp
#include"Heap.h"
void Heap::Swap(DataType& a, DataType& b)
{
DataType tmp = a;
a = b;
b = tmp;
}
void Heap::Push(const DataType& x)
{
if (size == capacity)
{
int newcapacity = capacity == 0 ? 1 : capacity * 2;
DataType* tmp = new DataType[newcapacity];
assert(tmp);
std::copy(a, a + size, tmp);
delete a;
a = tmp;
capacity = newcapacity;
}
a[size] = x;
AdjustUp(size);
++size;
}
void Heap::Pop() // 删除堆顶的数据
{
assert(size > 0);
Swap(a[0], a[size - 1]);
size--;
AdjustDown(size, 0);
}
DataType Heap::Top()const
{
assert(size > 0);
return a[0];
}
bool Heap::Empty()const
{
return size == 0;
}
int Heap::Size()const
{
return size;
}
void Heap::AdjustUp(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
Swap(a[parent], a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
//int parent = (child - 1) / 2;
//if(child > 0)
//{
// if (a[parent] > a[child])
// {
// Swap(a[parent], a[child]);
// child = parent;
// AdjustUp(child);
// }
// else
// {
// return;
// }
//}
}
void Heap::AdjustDown(int size,int parent) // size 是总大小,parent是从哪里开始向下调整
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
child++;
if (a[child] < a[parent])
{
Swap(a[child], a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void Heap::print()
{
for (int i = 0; i < size; ++i)
{
cout << a[i] << ' ';
}
cout << endl;
}
其实Heap这个类 物理结构就是一个一维数组,只是逻辑结构是一个堆,我们将其想象成一个具有特定规律的完全二叉树:特定规律就是任意一个二叉树的根节点都>=或<=其子节点。
这个Heap类的关键是push和pop函数,与之相关的是向上调整和向下调整函数,这也是堆的精髓所在。
push是在数组尾部也就是堆的最下面插入一个元素,此时应该调用向上调整算法,因为此结点的插入可能破坏了原来的堆的结构,因此,向上调整即可,但是有个前提,即插入此结点之前这个完全二叉树本身符合堆的特性。并且调整只会影响此插入结点的祖宗,不会对其他节点产生影响。

pop是删除堆顶的元素,且只能删除堆顶的元素,因为堆这个数据结构的一个主要功能就是选数:即选出当前堆中最大或者最小的数,并且选数的效率很高。pop删除堆顶元素之后,再进行一下调整即可选出次大或者次小的元素。
那么,怎么删除呢?即将堆顶和末尾的数字交换,然后删除交换后的末尾数字,此时堆顶元素很可能破坏了堆的结构,因此采用向下调整的算法。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
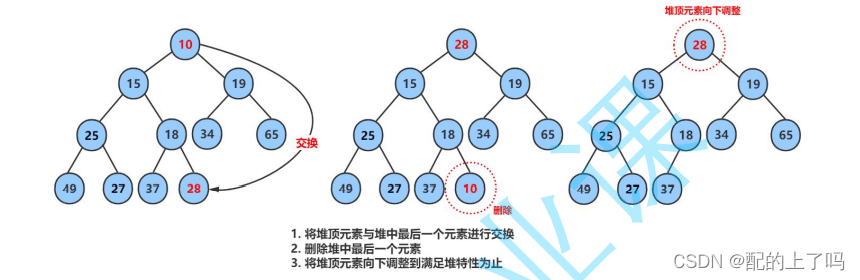
堆的应用
向上调整算法和向下调整算法不仅仅用于Heap的插入和删除操作,在堆排序等堆的应用中也要使用。
堆排序
传入一个数组,对数组进行排序,且是一个O(N*LogN)的算法,效率很高。
void AdjustUp(int* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
swap(a[parent], a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int* a,int size, int parent) // size 是总大小,parent是从哪里开始向下调整
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
child++;
if (a[child] < a[parent])
{
swap(a[child], a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
HeapSort
void HeapSort(int* a, int n)
{
// 将传入的数组看作一个完全二叉树,然后调整为堆。
// 升序调整为大根堆,降序小根堆。
// 建堆方式1: O(N*LogN)
// 利用向上调整算法,其实就是堆的插入函数
//for (int i = 1; i < n; ++i)
//{
// AdjustUp(a, i);
//}
// 建堆方式2: O(N)
// 利用向下调整算法
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// 建好堆之后排序 目前是一个小堆,小堆用来排降序
// 5 13 17 19 22 27 32 35 38 42 45
// O(N * LogN);
int end = n - 1;
while (end > 0)
{
swap(a[0], a[end]);
AdjustDown(a, end, 0);
end--;
}
}
前面说过,堆的一个主要或者说唯一作用就是选数,大根堆选出最大数,小根堆选出最小数,先将给定数组调整为堆,若排升序则调整为大根堆,此时a[0]即最大值,将其与数组末尾数组交换,然后进行向下调整即可选出次大值,再进行交换即可。整个逻辑十分像Heap类的删除操作,只是将删除了的堆顶元素放置在数组末尾而已,然后不断进行这个操作,直到整个数组有序。
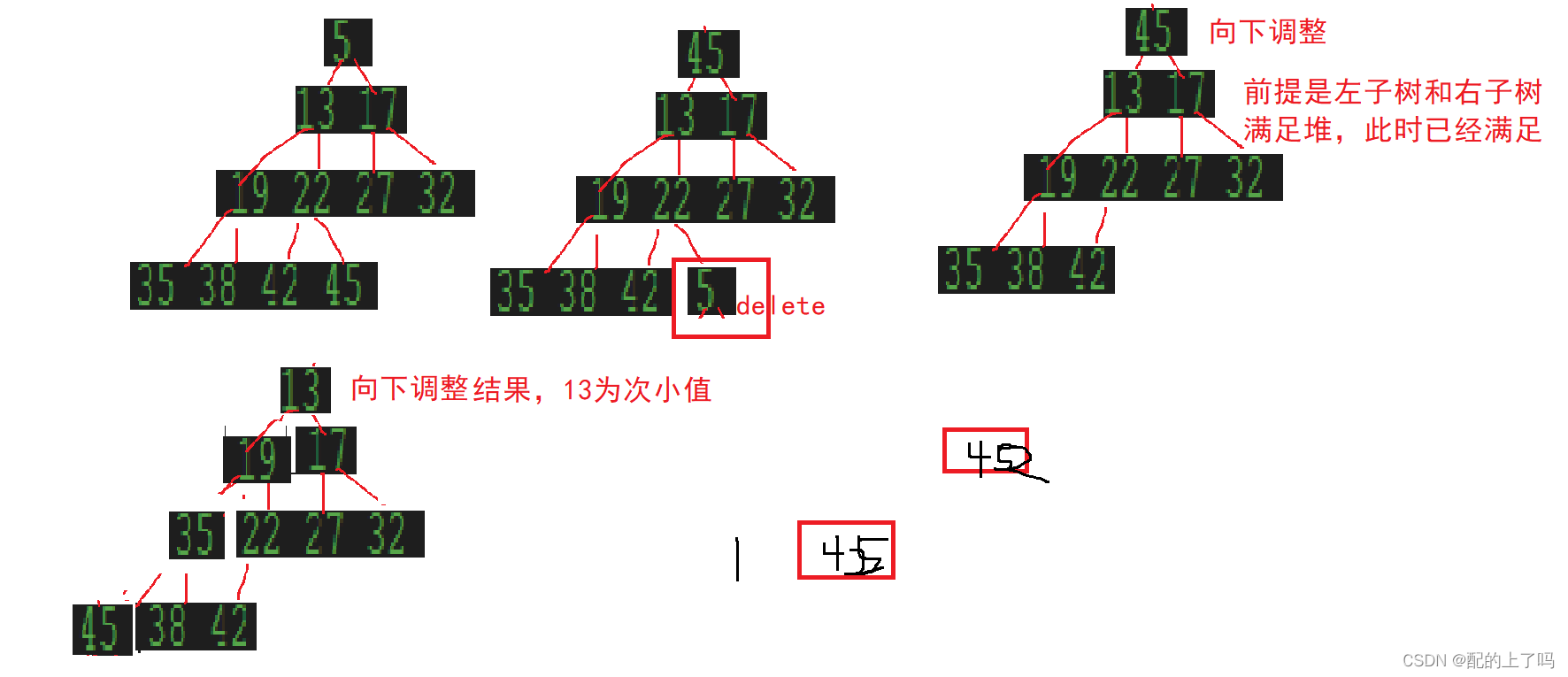
将数组调整为堆的思路有两个,一种是模拟插入的操作,从头遍历逐个将元素进行向上调整操作,主要是因为向上调整算法必须基于此完全二叉树本身就是一个堆,才可以进行向上调整操作。所以从尾开始向上调整肯定是不行的。
思路二与思路一有相同之处,即利用向下调整算法,向下调整基于此结点的左子树和右子树都是堆,所以直接从头开始向下调整不可以,所以从尾向前遍历进行向下调整,且末尾的叶子结点没有必要调整,所以从第一个结点数>=2的二叉树开始进行向下调整。
HeapSort的逻辑不会受升序和降序的影响,只需要将AdjustUp和AdjustDown的调整逻辑改变即可。
为什么排升序要建大根堆,不建小根堆呢?
首先,如果建小根堆,确实建好之后的数组比较像升序,且此时最小值也已经在数组的a[0]处,但是,选次大的元素时,对于后面a[1] 至 a[n-1]个元素,此时之前堆的兄弟父子关系全都乱了,向上调整和向下调整都不可以,只能重建堆,而重建堆的时间复杂度为O(N)。如此下去,每次挑出最大值都需要O(N),最终的就是O(N)+O(N-1)+...+O(2)... 总的就是O(N^2)了。
而如果建大根堆,a[0]就是最大值,将其与数组末尾进行交换,这个交换操作只是O(1)的操作,最重要的是交换之后,把末尾元素忽视之后的这个完全二叉树,只有堆顶元素不符合堆,只需向下调整一次即可,为O(logN),即可选出次大值,相比于前面的O(N)就快了很多。
到此这篇关于C++超详细实现堆和堆排序过像的文章就介绍到这了,更多相关C++堆和堆排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++堆排序算法的实现方法
本文实例讲述了C++实现堆排序算法的方法,相信对于大家学习数据结构与算法会起到一定的帮助作用.具体内容如下: 首先,由于堆排序算法说起来比较长,所以在这里单独讲一下.堆排序是一种树形选择排序方法,它的特点是:在排序过程中,将L[n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素. 一.堆的定义 堆的定义如下:n个关键字序列L[n]成为堆,当且仅当该序列满足: ①L(i) <= L(2i)且L(i) <= L(2
-
c++深入浅出讲解堆排序和堆
目录 堆是什么 最大堆 最小堆 堆排序 最终代码 关于堆 堆是什么 堆是一种特殊的完全二叉树 如果你是初学者,你的表情一定是这样的
-
C++实现堆排序示例
目录 堆的实现 Heap.h 堆的管理及接口 Heap.c 堆各个接口功能的实现 test.c测试 堆的实现 Heap.h 堆的管理及接口 #include<stdio.h> #include<stdlib.h> #include<assert.h> typedef int HPDataType; typedef struct Heap { HPDataType* a; int size; int capacity; }Heap; //堆的向下调整算法 void Adj
-
C++实现堆排序实例介绍
目录 概述: 思路: 代码: 概述: 堆排序是利用构建"堆"的方法确定具有最大值的数据元素,并把该元素与最后位置上的元素交换.可将任意一个由n个数据元素构成的序列按照(a1,a2,...,an),按照从左到右的顺序按层排列构成一棵与该序列对应的完全二叉树. 一棵完全二叉树是一个堆,当且仅当完全二叉树的每棵子树的根值ai≥其左子树的根值a2i,同时ai≥其右子树的根值a 2i+1 (1<i<n/2). 实现堆排序需要实现两个问题: 如何由无序序列建成一个堆?如何在输出堆顶元素
-
C++ 数据结构 堆排序的实现
堆排序(heapsort)是一种比较快速的排序方式,它的时间复杂度为O(nlgn),并且堆排序具有空间原址性,任何时候只需要有限的空间来存储临时数据.我将用c++实现一个堆来简单分析一下. 堆排序的基本思想为: 1.升序排列,保持大堆:降序排列,保持小堆: 2.建立堆之后,将堆顶数据与堆中最后一个数据交换,堆大小减一,然后向下调整:直到堆中只剩下一个有效值: 下面我将简单分析一下: 第一步建立堆: 1.我用vector顺序表表示数组: 2.用仿函数实现大小堆随时切换,实现代码复用: 3.实现向下
-
C++堆排序算法实例详解
本文实例讲述了C++堆排序算法.分享给大家供大家参考,具体如下: 堆中元素的排列方式分为两种:max-heap或min-heap,前者每个节点的key都大于等于孩子节点的key,后者每个节点的key都小于等于孩子节点的key. 由于堆可以看成一个完全二叉树,可以使用连续空间的array来模拟完全二叉树,简单原始的实现如下: #include<iostream> int heapsize=0;//全局变量记录堆的大小 void heapSort(int array[],int n){ void
-
解读堆排序算法及用C++实现基于最大堆的堆排序示例
1.堆排序定义 n个关键字序列Kl,K2,-,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质): (1) ki≤K2i且ki≤K2i+1 或(2)Ki≥K2i且ki≥K2i+1(1≤i≤ ) 若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字. [例]关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1
-
C++超详细实现堆和堆排序过像
目录 有关堆 C++实现堆 堆的应用 堆排序 有关二叉树的性质: 1. 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有 个结点. 2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 . 3. 对任何一棵二叉树, 如果度为0其叶结点个数为 , 度为2的分支结点个数为 ,则有 = +1 4. 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2 为底,n+1为对数) 5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节
-
Java 超详细讲解数据结构中的堆的应用
目录 一.堆的创建 1.向下调整(以小堆为例) 2.创建堆 3.创建堆的时间复杂度 二.堆的插入和删除 1.堆的插入 2.堆的删除 三.堆的应用 1.堆排序 2.top-k问题 [求最小的K个数] 四.常用接口的介绍 1.PriorityQueue的特性 2.优先级队列的构造 一.堆的创建 1.向下调整(以小堆为例) 让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子) 如果parent的左孩子存在,即:child < size,
-
Java 超详细讲解数据结构中的堆的应用
目录 一.堆的创建 1.向下调整(以小堆为例) 2.创建堆 3.创建堆的时间复杂度 二.堆的插入和删除 1.堆的插入 2.堆的删除 三.堆的应用 1.堆排序 2.top-k问题(求最小的K个数) 四.常用接口的介绍 1.PriorityQueue的特性 2.优先级队列的构造 一.堆的创建 1.向下调整(以小堆为例) 让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子) 如果parent的左孩子存在,即:child < size, 进
-
C语言超详细讲解排序算法上篇
目录 1.直接插入排序 2.希尔排序(缩小增量排序) 3.直接选择排序 4.堆排序 进入正式内容之前,我们先了解下初阶常见的排序分类 :我们今天讲前四个! 1.直接插入排序 基本思想:当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排 序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移! 直接插入排序的特性总结: 1. 元素集
-
C语言超详细梳理排序算法的使用
目录 排序的概念及其运用 排序的概念 排序运用 插入排序 直接插入排序 希尔排序 选择排序 直接选择排序 堆排序 交换排序之冒泡排序 总结 排序的概念及其运用 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作. 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排 序算法
-
Java 超详细讲解十大排序算法面试无忧
目录 排序算法的稳定性: 一.选择排序 二.冒泡排序 三.插入排序 四.希尔排序 五.堆排序 六.归并排序 七.快速排序 八.鸽巢排序 九.计数排序 十.基数排序 排序算法的稳定性: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,如果排序以后,保证这些记录的相对次序保持不变,即在原序列中,a[i]=a[j],且 a[i] 在 a[j] 之前,排序后保证 a[i] 仍在 a[j] 之前,则称这种排序算法是稳定的:否则称为不稳定的. 一.选择排序 每次从待排序的元素中选择最小的元素,依次
-
Java超详细整理讲解各种排序
目录 稳定性 直接插入排序 希尔排序 选择排序 堆排序 冒泡排序 快速排序 归并排序 计数排序 稳定性 两个相等的数据,如果经过排序后,排序算法能保证其相对位置不发生变化,则我们称该算法是具备稳定性的排序算法. 直接插入排序 直接插入排序就是每次选择无序区间的第一个元素,在有序区间内选择合适的位置插入. 从数组下标为1开始,将下标为1上的值取出来放在tmp中,然后它和前面的下标j上的值进行比较,如果前面下标j上的值比它大,则前面下标j上的值往后走一步,直到比到j回退到了-1或者j下标上的值比tm
-
Java中关于内存泄漏出现的原因汇总及如何避免内存泄漏(超详细版)
Android 内存泄漏总结 内存管理的目的就是让我们在开发中怎么有效的避免我们的应用出现内存泄漏的问题.内存泄漏大家都不陌生了,简单粗俗的讲,就是该被释放的对象没有释放,一直被某个或某些实例所持有却不再被使用导致 GC 不能回收.最近自己阅读了大量相关的文档资料,打算做个 总结 沉淀下来跟大家一起分享和学习,也给自己一个警示,以后 coding 时怎么避免这些情况,提高应用的体验和质量. 我会从 java 内存泄漏的基础知识开始,并通过具体例子来说明 Android 引起内存泄漏的各种原因,以
-
超详细的Java 问题排查工具单
前言 平时的工作中经常碰到很多疑难问题的处理,在解决问题的同时,有一些工具起到了相当大的作用,在此书写下来,一是作为笔记,可以让自己后续忘记了可快速翻阅,二是分享,希望看到此文的同学们可以拿出自己日常觉得帮助很大的工具,大家一起进步. 闲话不多说,开搞. Linux命令类 tail 最常用的tail -f tail -300f shopbase.log #倒数300行并进入实时监听文件写入模式 grep grep forest f.txt #文件查找 grep forest f.txt cpf.
-
spring boot actuator监控超详细教程
spring boot actuator介绍 Spring Boot包含许多其他功能,可帮助您在将应用程序推送到生产环境时监视和管理应用程序. 您可以选择使用HTTP端点或JMX来管理和监视应用程序. 审核,运行状况和指标收集也可以自动应用于您的应用程序. 总之Spring Boot Actuator就是一款可以帮助你监控系统数据的框架,其可以监控很多很多的系统数据,它有对应用系统的自省和监控的集成功能,可以查看应用配置的详细信息,如: 显示应用程序员的Health健康信息 显示Info应用信息