pytorch中LN(LayerNorm)及Relu和其变相的输出操作
主要就是了解一下pytorch中的使用layernorm这种归一化之后的数据变化,以及数据使用relu,prelu,leakyrelu之后的变化。
import torch
import torch.nn as nn
import torch.nn.functional as F
class model(nn.Module):
def __init__(self):
super(model, self).__init__()
self.LN=nn.LayerNorm(10,eps=0,elementwise_affine=True)
self.PRelu=nn.PReLU(init=0.25)
self.Relu=nn.ReLU()
self.LeakyReLU=nn.LeakyReLU(negative_slope=0.01,inplace=False)
def forward(self,input ):
out=self.LN(input)
print("LN:",out)
out1=self.PRelu(out)
print("PRelu:",out1)
out2=self.Relu(out)
print("Relu:",out2)
out3=self.LeakyReLU(out)
print("LeakyRelu:",out3)
return out
tensor=torch.tensor([-0.9,0.1,0,-0.1,0.9,-0.4,0.9,-0.5,0.8,0.1])
net=model()
print(tensor)
net(tensor)
输出:
tensor([-0.9000, 0.1000, 0.0000, -0.1000, 0.9000, -0.4000, 0.9000, -0.5000,
0.8000, 0.1000])
LN: tensor([-1.6906, 0.0171, -0.1537, -0.3245, 1.3833, -0.8368, 1.3833, -1.0076,
1.2125, 0.0171], grad_fn=<NativeLayerNormBackward>)
Relu: tensor([0.0000, 0.0171, 0.0000, 0.0000, 1.3833, 0.0000, 1.3833, 0.0000, 1.2125,
0.0171], grad_fn=<ReluBackward0>)
PRelu: tensor([-0.4227, 0.0171, -0.0384, -0.0811, 1.3833, -0.2092, 1.3833, -0.2519,
1.2125, 0.0171], grad_fn=<PreluBackward>)
LeakyRelu: tensor([-0.0169, 0.0171, -0.0015, -0.0032, 1.3833, -0.0084, 1.3833, -0.0101,
1.2125, 0.0171], grad_fn=<LeakyReluBackward0>)
从上面可以看出,这个LayerNorm的归一化,并不是将数据限定在0-1之间,也没有进行一个类似于高斯分布一样的分数,只是将其进行了一个处理,对应的数值得到了一些变化,相同数值的变化也是相同的。
Relu的则是单纯将小于0的数变成了0,减少了梯度消失的可能性
PRelu是一定程度上的保留了负值,根据init给的值。
LeakyRelu也是一定程度上保留负值,不过比较小,应该是根据negative_slope给的值。
补充:PyTorch学习之归一化层(BatchNorm、LayerNorm、InstanceNorm、GroupNorm)
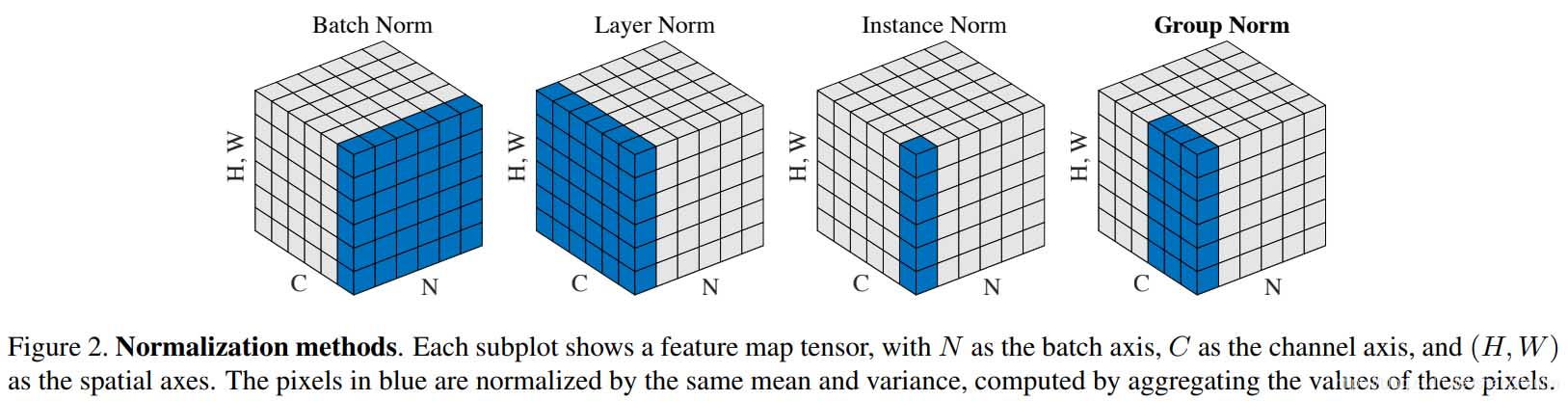
BN,LN,IN,GN从学术化上解释差异:
BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
1 BatchNorm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为'batch_size x num_features [x width]'
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
实现公式:
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
实现公式:
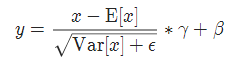
2 GroupNorm
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
参数:
num_groups:需要划分为的groups
num_features:来自期望输入的特征数,该期望输入的大小为'batch_size x num_features [x width]'
eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum:动态均值和动态方差所使用的动量。默认为0.1。
affine:布尔值,当设为true,给该层添加可学习的仿射变换参数。
实现公式:
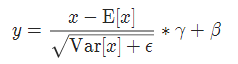
3 InstanceNorm
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
参数:
num_features:来自期望输入的特征数,该期望输入的大小为'batch_size x num_features [x width]'
eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum:动态均值和动态方差所使用的动量。默认为0.1。
affine:布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
实现公式:

4 LayerNorm
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
参数:
normalized_shape: 输入尺寸
[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
实现公式:
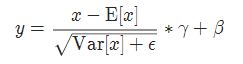
5 LocalResponseNorm
torch.nn.LocalResponseNorm(size, alpha=0.0001, beta=0.75, k=1.0)
参数:
size:用于归一化的邻居通道数
alpha:乘积因子,Default: 0.0001
beta :指数,Default: 0.75
k:附加因子,Default: 1
实现公式:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch 输出中间层特征的实例
pytorch 输出中间层特征: tensorflow输出中间特征,2种方式: 1. 保存全部模型(包括结构)时,需要之前先add_to_collection 或者 用slim模块下的end_points 2. 只保存模型参数时,可以读取网络结构,然后按照对应的中间层输出即可. but:Pytorch 论坛给出的答案并不好用,无论是hooks,还是重建网络并去掉某些层,这些方法都不好用(在我看来). 我们可以在创建网络class时,在forward时加入一个dict 或者 list,dict是将
-
PyTorch之nn.ReLU与F.ReLU的区别介绍
我就废话不多说了,大家还是直接看代码吧~ import torch.nn as nn import torch.nn.functional as F import torch.nn as nn class AlexNet_1(nn.Module): def __init__(self, num_classes=n): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_siz
-
pytorch方法测试——激活函数(ReLU)详解
测试代码: import torch import torch.nn as nn #inplace为True,将会改变输入的数据 ,否则不会改变原输入,只会产生新的输出 m = nn.ReLU(inplace=True) input = torch.randn(7) print("输入处理前图片:") print(input) output = m(input) print("ReLU输出:") print(output) print("输出的尺度:&qu
-
pytorch在fintune时将sequential中的层输出方法,以vgg为例
有时候我们在fintune时发现pytorch把许多层都集合在一个sequential里,但是我们希望能把中间层的结果引出来做下一步操作,于是我自己琢磨了一个方法,以vgg为例,有点僵硬哈! 首先pytorch自带的vgg16模型的网络结构如下: VGG( (features): Sequential( (0): Conv2d (3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace) (2): Co
-

pytorch中LN(LayerNorm)及Relu和其变相的输出操作
主要就是了解一下pytorch中的使用layernorm这种归一化之后的数据变化,以及数据使用relu,prelu,leakyrelu之后的变化. import torch import torch.nn as nn import torch.nn.functional as F class model(nn.Module): def __init__(self): super(model, self).__init__() self.LN=nn.LayerNorm(10,eps=0,eleme
-
对Pytorch中nn.ModuleList 和 nn.Sequential详解
简而言之就是,nn.Sequential类似于Keras中的贯序模型,它是Module的子类,在构建数个网络层之后会自动调用forward()方法,从而有网络模型生成.而nn.ModuleList仅仅类似于pytho中的list类型,只是将一系列层装入列表,并没有实现forward()方法,因此也不会有网络模型产生的副作用. 需要注意的是,nn.ModuleList接受的必须是subModule类型,例如: nn.ModuleList( [nn.ModuleList([Conv(inp_dim
-
pytorch中nn.Conv1d的用法详解
先粘贴一段official guide:nn.conv1d官方 我一开始被in_channels.out_channels卡住了很久,结果发现就和conv2d是一毛一样的.话不多说,先粘代码(菜鸡的自我修养) class CNN1d(nn.Module): def __init__(self): super(CNN1d,self).__init__() self.layer1 = nn.Sequential( nn.Conv1d(1,100,2), nn.BatchNorm1d(100), nn
-
PyTorch中的padding(边缘填充)操作方式
简介 我们知道,在对图像执行卷积操作时,如果不对图像边缘进行填充,卷积核将无法到达图像边缘的像素,而且卷积前后图像的尺寸也会发生变化,这会造成许多麻烦. 因此现在各大深度学习框架的卷积层实现上基本都配备了padding操作,以保证图像输入输出前后的尺寸大小不变.例如,若卷积核大小为3x3,那么就应该设定padding=1,即填充1层边缘像素:若卷积核大小为7x7,那么就应该设定padding=3,填充3层边缘像素:也就是padding大小一般设定为核大小的一半.在pytorch的卷积层定义中,默
-
关于pytorch中全连接神经网络搭建两种模式详解
pytorch搭建神经网络是很简单明了的,这里介绍两种自己常用的搭建模式: import torch import torch.nn as nn first: class NN(nn.Module): def __init__(self): super(NN,self).__init__() self.model=nn.Sequential( nn.Linear(30,40), nn.ReLU(), nn.Linear(40,60), nn.Tanh(), nn.Linear(60,10), n
-
Pytorch中的VGG实现修改最后一层FC
https://discuss.pytorch.org/t/how-to-modify-the-final-fc-layer-based-on-the-torch-model/766/12 That's because vgg19 doesn't have a fc member variable. Instead, it has a (classifier): Sequential ( (0): Dropout (p = 0.5) (1): Linear (25088 -> 4096) (2)
-
pytorch 中的重要模块化接口nn.Module的使用
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 查看源码 初始化部分: def __init__(self): self._backend = thnn_backend self._parameters = OrderedDict() self._buffers = OrderedDict() self._backward_hooks = Ordered
-
基于pytorch中的Sequential用法说明
class torch.nn.Sequential(* args) 一个时序容器.Modules 会以他们传入的顺序被添加到容器中.当然,也可以传入一个OrderedDict. 为了更容易的理解如何使用Sequential, 下面给出了一个例子: # Example of using Sequential model = nn.Sequential( nn.Conv2d(1,20,5), nn.ReLU(), nn.Conv2d(20,64,5), nn.ReLU() ) # Example o
-
pytorch中的weight-initilzation用法
pytorch中的权值初始化 官方论坛对weight-initilzation的讨论 torch.nn.Module.apply(fn) torch.nn.Module.apply(fn) # 递归的调用weights_init函数,遍历nn.Module的submodule作为参数 # 常用来对模型的参数进行初始化 # fn是对参数进行初始化的函数的句柄,fn以nn.Module或者自己定义的nn.Module的子类作为参数 # fn (Module -> None) – function t
-
浅谈PyTorch中in-place operation的含义
in-place operation在pytorch中是指改变一个tensor的值的时候,不经过复制操作,而是直接在原来的内存上改变它的值.可以把它成为原地操作符. 在pytorch中经常加后缀"_"来代表原地in-place operation,比如说.add_() 或者.scatter().python里面的+=,*=也是in-place operation. 下面是正常的加操作,执行结束加操作之后x的值没有发生变化: import torch x=torch.rand(2) #t