Python selenium模拟网页点击爬虫交管12123违章数据
在上一篇文章《Python教程—模拟网页点击爬虫定位系统》讲解怎么通过模拟点击方式爬取车辆定位数据,本次介绍怎么以模拟点击方式进入交管12123爬取车辆违章数据,本文直接讲解过程,使用的命令解释见上一篇文章。本文同《Python教程—模拟网页点击爬虫定位系统》同样为企业中实际的爬虫案例,如果之后想进入车企行业可以做个了解。
准备工具:spyder、selenium库、google浏览器及对应版本的chromedriver.exe
效果
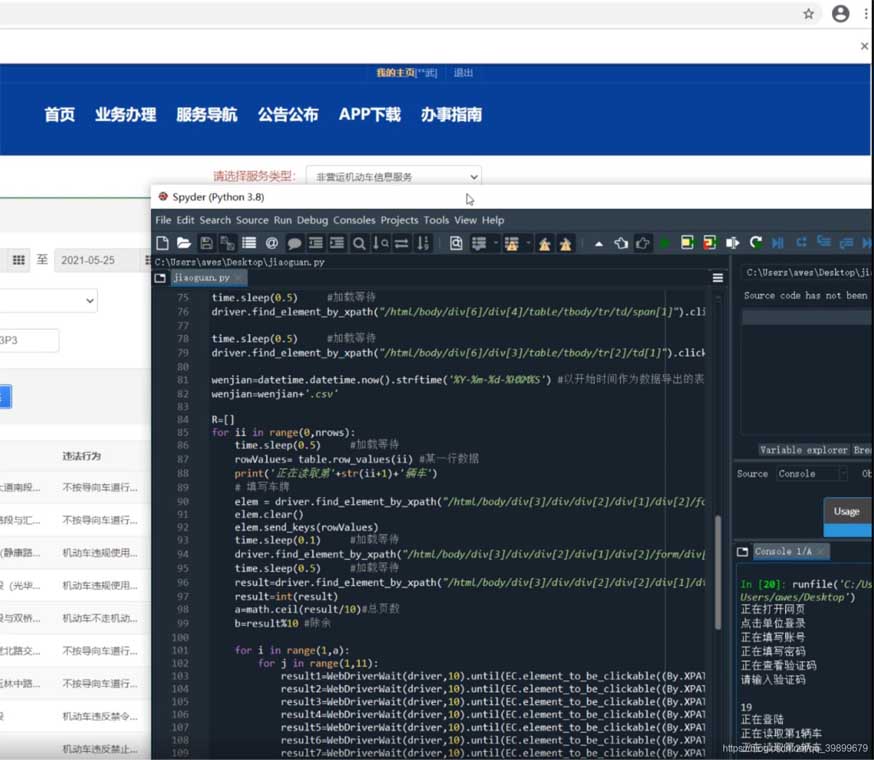
注:分享此案例目的是为了帮助同行解放双手,更好管理企业资产,本文程序以删除网址、账号密码,该网址比较麻烦的一点是开始点击登录的时候网页可能会有其他弹窗出现,使得原有路径改变,程序会因为找不到对应路径而报错,重新执行程序即可。除了模拟点击登录,还可以直接通过Cookie直接登录网页,这种方式就可以绕过登录的繁琐步骤。
调用库
from selenium import webdriver import time import csv import datetime from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait import math import xlrd
读取需要查询的车牌号

data = xlrd.open_workbook('cheliang.xlsx')
创建浏览,打开网页
opt = webdriver.ChromeOptions() #创建浏览
#opt.set_headless() #无窗口模式
driver = webdriver.Chrome(options=opt) #创建浏览器对象
driver.maximize_window() #最大化窗口
print("正在打开网页")
driver.get('') #打开网页
依次点击单位登录、输入账号、密码、点击验证码填写区域触发图片、勾选、输入验证码、点击登录

time.sleep(3) #加载等待
print("点击单位登录")
time.sleep(3) #加载等待
driver.find_element_by_xpath("/html/body/div[1]/div[2]/div/div[2]/div[2]/button").click()#点击单位登录
time.sleep(3) #加载等待
print("正在填写账号")
elem = driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[1]/div/input")
# 清空原有内容
elem.clear()
# 填入账号
elem.send_keys("")
time.sleep(1) #加载等待
print("正在填写密码")
elem = driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[2]/div/input")
# 清空原有内容
elem.clear()
# 填入密码
elem.send_keys("")
time.sleep(1) #加载等待
print("正在查看验证码")
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[3]/div/input").click()#查看验证码
print("请输入验证码")
yanzhengma=input()
time.sleep(1) #加载等待
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[4]/div/label/input").click()#勾选
time.sleep(1) #加载等待
# 填入验证码
elem = driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[3]/div/input")
elem.clear()
elem.send_keys(str(yanzhengma))
time.sleep(1) #加载等待
print("正在登陆")
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[5]/button").click()#点击
点击违法查询,设置查询时间
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[5]/button").click()#点击
time.sleep(3) #加载等待
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/ul/li[5]/a").click()#点击违法查询
time.sleep(1) #加载等待
driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[1]/div[2]/form/div[1]/div/div[1]/span/i").click()#点击选择日期
for i in range(3):
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("/html/body/div[6]/div[4]/table/thead/tr/th[1]/i").click()#点击
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("/html/body/div[6]/div[4]/table/tbody/tr/td/span[1]").click()#点击
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("/html/body/div[6]/div[3]/table/tbody/tr[2]/td[1]").click()#点击
循环依次查询每个车牌违章信息,每次都需要清空上次输入,填写本次查询车牌,识别有多少条数据,共多少页,每页最多展示10条,最后一页有多少条数据

for ii in range(0,nrows):
rowValues= table.row_values(ii) #某一行数据
print('正在读取第'+str(ii+1)+'辆车')
# 填写车牌
time.sleep(0.5) #加载等待
elem = driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[1]/div[2]/form/div[3]/div/input")
elem.clear()
elem.send_keys(rowValues)#输入车牌
time.sleep(0.1) #加载等待
driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[1]/div[2]/form/div[4]/button").click()#点击查询
time.sleep(0.5) #加载等待
result=driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[2]/div[1]/div/p/span").text#总违章条数
result=int(result)
a=math.ceil(result/10)#总页数
b=result%10 #除余
读取列表中的数据,其中扣分和罚款需要点击"查看详情",从弹窗中读取数据
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[1]"))).text result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[2]"))).text result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[3]"))).text result4=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[4]"))).text result5=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[5]"))).text result6=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[6]"))).text result7=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[7]"))).text WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[8]/a"))).click()#查看详情,打开弹窗 time.sleep(1) #加载等待 result8=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[7]/span[2]"))).text result9=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[8]/span[2]"))).text result=[result1,result2,result3,result4,result5,result6,result7,result8,result9] R.append(result) WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='modal-footer ui_modal']/button"))).click()#关闭弹窗 time.sleep(0.5) #加载等待
每读取一辆车的数据就写入表格中
with open(wenjian,'w',encoding='utf-8',newline='') as fp:
writer = csv.writer(fp)
writer.writerows(R) #写入数据
完整代码
from selenium import webdriver
import time
import csv
import datetime
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import math
import xlrd
data = xlrd.open_workbook('cheliang.xlsx')
table = data.sheets()[0]
nrows = table.nrows #行数
ncols = table.ncols #列数
opt = webdriver.ChromeOptions() #创建浏览
#opt.set_headless() #无窗口模式
driver = webdriver.Chrome(options=opt) #创建浏览器对象
driver.maximize_window() #最大化窗口
print("正在打开网页")
driver.get('') #打开网页
time.sleep(3) #加载等待
print("点击单位登录")
time.sleep(3) #加载等待
driver.find_element_by_xpath("/html/body/div[1]/div[2]/div/div[2]/div[2]/button").click()#点击单位登录
time.sleep(3) #加载等待
print("正在填写账号")
elem = driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[1]/div/input")
# 清空原有内容
elem.clear()
# 填入账号
elem.send_keys("")
time.sleep(1) #加载等待
print("正在填写密码")
elem = driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[2]/div/input")
# 清空原有内容
elem.clear()
# 填入密码
elem.send_keys("")
time.sleep(1) #加载等待
print("正在查看验证码")
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[3]/div/input").click()#查看验证码
print("请输入验证码")
yanzhengma=input()
time.sleep(1) #加载等待
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[4]/div/label/input").click()#勾选
time.sleep(1) #加载等待
# 填入验证码
elem = driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[3]/div/input")
elem.clear()
elem.send_keys(str(yanzhengma))
time.sleep(1) #加载等待
print("正在登陆")
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/div/div[2]/form[1]/div[5]/button").click()#点击
time.sleep(3) #加载等待
driver.find_element_by_xpath("/html/body/div[4]/div/div[1]/ul/li[5]/a").click()#点击违法查询
time.sleep(1) #加载等待
driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[1]/div[2]/form/div[1]/div/div[1]/span/i").click()#点击选择日期
for i in range(3):
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("/html/body/div[6]/div[4]/table/thead/tr/th[1]/i").click()#点击
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("/html/body/div[6]/div[4]/table/tbody/tr/td/span[1]").click()#点击
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("/html/body/div[6]/div[3]/table/tbody/tr[2]/td[1]").click()#点击
wenjian=datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S') #以开始时间作为数据导出的表格文件名
wenjian=wenjian+'.csv'
R=[]
for ii in range(0,nrows):
rowValues= table.row_values(ii) #某一行数据
print('正在读取第'+str(ii+1)+'辆车')
# 填写车牌
time.sleep(0.5) #加载等待
elem = driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[1]/div[2]/form/div[3]/div/input")
elem.clear()
elem.send_keys(rowValues)#输入车牌
time.sleep(0.1) #加载等待
driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[1]/div[2]/form/div[4]/button").click()#点击查询
time.sleep(0.5) #加载等待
result=driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div[2]/div[1]/div/p/span").text#总违章条数
result=int(result)
a=math.ceil(result/10)#总页数
b=result%10 #除余
for i in range(1,a):
for j in range(1,11):
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[1]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[3]"))).text
result4=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[4]"))).text
result5=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[5]"))).text
result6=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[6]"))).text
result7=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[7]"))).text
#result1=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[1]").text
#result2=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[2]").text
#result3=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[3]").text
#result4=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[4]").text
#result5=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[5]").text
#result6=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[6]").text
#result7=driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[7]").text
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[8]/a"))).click()#查看详情,打开弹窗
time.sleep(1) #加载等待
#driver.find_element_by_xpath("//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[8]/a").click()#点击列表中的元素
#time.sleep(0.5) #加载等待
result8=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[7]/span[2]"))).text
result9=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[8]/span[2]"))).text
#result8=driver.find_element_by_xpath("//form[@class='form-horizontal']/div[7]/span[2]").text
#result9=driver.find_element_by_xpath("//form[@class='form-horizontal']/div[8]/span[2]").text
result=[result1,result2,result3,result4,result5,result6,result7,result8,result9]
R.append(result)
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='modal-footer ui_modal']/button"))).click()#关闭弹窗
time.sleep(0.5) #加载等待
#driver.find_element_by_xpath("//div[@class='modal-footer ui_modal']/button").click()#点击列表中的元素
#time.sleep(0.5) #加载等待
driver.find_element_by_link_text("下一页").click()#翻页
time.sleep(0.5) #加载等待
if b>0:
for j in range(1,b+1):
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[1]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[3]"))).text
result4=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[4]"))).text
result5=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[5]"))).text
result6=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[6]"))).text
result7=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[7]"))).text
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[8]/a"))).click()#查看详情,打开弹窗
time.sleep(1) #加载等待
result8=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[7]/span[2]"))).text
result9=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[8]/span[2]"))).text
result=[result1,result2,result3,result4,result5,result6,result7,result8,result9]
R.append(result)
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='modal-footer ui_modal']/button"))).click()#关闭弹窗
time.sleep(0.5) #加载等待
if b==0:
for j in range(1,11):
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[1]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[3]"))).text
result4=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[4]"))).text
result5=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[5]"))).text
result6=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[6]"))).text
result7=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[7]"))).text
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//table[@id='my-msg-list']/tbody/tr["+str(j)+"]/td[8]/a"))).click()#查看详情,打开弹窗
time.sleep(1) #加载等待
result8=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[7]/span[2]"))).text
result9=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//form[@class='form-horizontal']/div[8]/span[2]"))).text
result=[result1,result2,result3,result4,result5,result6,result7,result8,result9]
R.append(result)
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='modal-footer ui_modal']/button"))).click()#关闭弹窗
time.sleep(0.5) #加载等待
time.sleep(0.5) #加载等待
with open(wenjian,'w',encoding='utf-8',newline='') as fp:
writer = csv.writer(fp)
writer.writerows(R) #写入数据
到此这篇关于Python selenium模拟网页点击爬虫交管12123违章数据的文章就介绍到这了,更多相关Python selenium模拟点击爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫之Selenium实现关闭浏览器
前言:WebDriver提供了两个关闭浏览器的方法,一个是前边使用quit()方法,另一个是close()方法 close():关闭当前窗口 quit():关闭所有窗口 quit()是关闭所有窗口,就不过多说了,测试一下close() from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("h
-

Python爬虫之Selenium下拉框处理的实现
在我们浏览网页的时候经常会碰到下拉框,WebDriver提供了Select类来处理下拉框,详情请往下看: 本章中用到的关键方法如下: select_by_value():设置下拉框的值 switch_to.alert.accept():定位并接受现有警告框(详情请参考Python爬虫 - Selenium(9)警告框(弹窗)处理) click():鼠标点击事件(其他鼠标事件请参考Python爬虫 - Selenium(5)鼠标事件) move_to_element():鼠标悬停(详情请参考Pyt
-
python爬虫开发之selenium模块详细使用方法与实例全解
python爬虫模块selenium简介 selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题. 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 一.声明浏览器对象 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入 from selenium import webdriver #webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里
-
Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1.引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一部分实验了用xslt方式一次性提取静态网页内容并转换成xml格式.留下了一个问题:javascript管理的动态内容怎样提取?那么本文就回答这个问题. 2.提取动态内容的技术部件 在上一篇python使用xslt提取网页数据中,要提取的内容是直接从网页的source code里拿到的.但是一些Aja
-
浅谈python爬虫使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动态加载的图片该怎么爬取到. 分析 他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来. headers = { 'User-Agent':'Mozilla/5.0 (Win
-
python爬虫selenium和phantomJs使用方法解析
1.selenum:三方库.可以实现让浏览器完成自动化的操作. 2.环境搭建 2.1 安装: pip install selenium 2.2 获取浏览器的驱动程序 下载地址: http://chromedriver.storage.googleapis.com/index.html http://npm.taobao.org/mirrors/chromedriver/ 浏览器版本和驱动版本的对应关系表: chromedriver版本 支持的Chrome版本 v2.46 v71-73 v2.45
-
Python3爬虫中Selenium的用法详解
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击.下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬.对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效.本节中,就让我们来感受一下它的强大之处吧. 1. 准备工作 本节以Chrome为例来讲解Selenium的用法.在开始之前,请确保已经正确安装好了Chrome浏览器并配置好了ChromeDriver.另外,还需要正确安装好Python的Selenium库,详细的安装和配置过程
-
selenium+python设置爬虫代理IP的方法
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,一般来说,速度是很慢的.而且一般需要用到这种技术爬取的网站,反爬技术都比较厉害,对IP的访问频率应该有相当的限制.所以,如果想提升selenium抓取数据的速度,可以从两个方面出发: 第一,提高抓取频率,出现验证信息时进行破解,一般是验证码或者用户登录. 第二,使用多线程 + 代理IP, 这种方式,需要电脑有足够的内存和充足稳定的代理IP . 2. 为chrome设置代理IP from selenium import webdri
-
详解Selenium+PhantomJS+python简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver) selenium2支持通过驱动无界面浏览器(HtmlUnit,PhantomJs) 二.安装 Windows 第一种方法是:下载源码安装,下载地址(https://pypi.python.org/py
-
Python selenium模拟网页点击爬虫交管12123违章数据
在上一篇文章<Python教程-模拟网页点击爬虫定位系统>讲解怎么通过模拟点击方式爬取车辆定位数据,本次介绍怎么以模拟点击方式进入交管12123爬取车辆违章数据,本文直接讲解过程,使用的命令解释见上一篇文章.本文同<Python教程-模拟网页点击爬虫定位系统>同样为企业中实际的爬虫案例,如果之后想进入车企行业可以做个了解. 准备工具:spyder.selenium库.google浏览器及对应版本的chromedriver.exe 效果 注:分享此案例目的是为了帮助同行解放双手,更好
-
python selenium模拟点击问题解决方案
目录 1.安装谷歌浏览器 2.安装浏览器驱动 3.安装selenium 4.简单测试 5.打卡程序 6.linux设置定时任务 7.其他 1.安装谷歌浏览器 #下载包 wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb #安装包,用deb方式安装 sudo dpkg -i --force-depends google-chrome-stable_current_amd64.deb #####
-
Python selenium模拟手动操作实现无人值守刷积分功能
经常为学校的各种刷分而发愁,得知开学无望,日后还要刷课,索性自动化一次,学而不用乃愚昧 聪慧 四大模块 初始化 from selenium import webdriver if __name__ == '__main__': driver = webdriver.Chrome() url = 'https://pc.xuexi.cn/points/login.html?ref=https://pc.xuexi.cn/points/my-points.html' driver.get(url =
-
python+Selenium自动化测试——输入,点击操作
这是我的第一个真正意思上的自动化脚本. 1.练习的测试用例为: 打开百度首页,搜索"胡歌",然后检索列表,有无"胡歌的新浪微博"这个链接 2.在写脚本之前,需要明确测试的步骤,具体到每个步骤需要做什么,既拆分测试场景,考虑好之后,再去写脚本. 此测试场景拆分如下: 1)启动Chrome浏览器 2)打开百度首页,https://www.baidu.com 3)定位搜索输入框,输入框元素XPath表达式://*[@id="kw"] 4)定位搜索提交按
-
如何使用python实现模拟鼠标点击
这篇文章主要介绍了如何使用python实现模拟鼠标点击,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 不知道大家在工作中有没有一些工作需要重复的点击鼠标,因为会影响到财务统计报表的关系,我们每个月底月初都要修改ERP中的单据日期,单据多的时候光修改就能让你点鼠标点到手麻.(这里要吐槽一下浪沙软件,别的单据都可以批量修改日期,就是这个移仓单不行,你们研发怎么就这么懒?剩下这么点工作就不完成他?)之前同事有跟我提到过键盘精灵,因为当时负责别的工作,
-
学习Python selenium自动化网页抓取器
直接入正题---Python selenium自动控制浏览器对网页的数据进行抓取,其中包含按钮点击.跳转页面.搜索框的输入.页面的价值数据存储.mongodb自动id标识等等等. 1.首先介绍一下 Python selenium ---自动化测试工具,用来控制浏览器来对网页的操作,在爬虫中与BeautifulSoup结合那就是天衣无缝,除去国外的一些变态的验证网页,对于图片验证码我有自己写的破解图片验证码的源代码,成功率在85%. 详情请咨询QQ群--607021567(这不算广告,群里有好多P
-
python+selenium定时爬取丁香园的新型冠状病毒数据并制作出类似的地图(部署到云服务器)
前言 硬要说这篇文章怎么来的,那得先从那几个吃野味的人开始说起-- 前天睡醒:假期还有几天:昨天睡醒:假期还有十几天:今天睡醒:假期还有一个月-- 每天过着几乎和每个假期一样的宅男生活,唯一不同的是玩手机已不再是看剧.看电影.打游戏了,而是每天都在关注着这次新冠肺炎疫情的新闻消息,真得希望这场战"疫"快点结束,让我们过上像以前一样的生活.武汉加油!中国加油!! 本次爬取的网站是丁香园点击跳转,相信大家平时都是看这个的吧. 一.准备 python3.7 selenium:自动化测试框架,
-
python编程使用selenium模拟登陆淘宝实例代码
selenium简介 selenium 是一个web的自动化测试工具,不少学习功能自动化的同学开始首选selenium ,相因为它相比QTP有诸多有点: * 免费,也不用再为破解QTP而大伤脑筋 * 小巧,对于不同的语言它只是一个包而已,而QTP需要下载安装1个多G 的程序. * 这也是最重要的一点,不管你以前更熟悉C. java.ruby.python.或都是C# ,你都可以通过selenium完成自动化测试,而QTP只支持VBS * 支持多平台:windows.linux.MAC ,支持多浏
-
Python+selenium实现截图图片并保存截取的图片
这篇文章介绍如何利用Selenium的方法进行截图,在测试过程中,是有必要截图,特别是遇到错误的时候进行截图.在selenium for Python中主要有三个截图方法,我们挑选其中最常用的一种. 截图技能对于测试人员来说应该是较为重要的一个技能. 在自动化测试中,截图可以帮助我们直观的定位错误.记录测试步骤. 记得以前在给某跨国银行做自动化项目的时候,某银的PM要求我们自动化测试的每一步至少需要1个截图,以证明每个功能都被自动化测试给覆盖过,在这种情况下截图就成了证明自动化测试有效性的重要手
-
python selenium UI自动化解决验证码的4种方法
本文介绍了python selenium UI自动化解决验证码的4种方法,分享给大家,具体如下: 测试环境 windows7+ firefox50+ geckodriver # firefox浏览器驱动 python3 selenium3 selenium UI自动化解决验证码的4种方法:去掉验证码.设置万能码.验证码识别技术-tesseract.添加cookie登录,本次主要讲解验证码识别技术-tesseract和添加cookie登录. 1. 去掉验证码 去掉验证码,直接通过用户名和密码登陆网