python决策树之C4.5算法详解
本文为大家分享了决策树之C4.5算法,供大家参考,具体内容如下
1. C4.5算法简介
C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸和优化。C4.5算法对ID3算法主要做了一下几点改进:
(1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足;
(2)能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理;
(3)构造决策树之后进行剪枝操作;
(4)能够处理具有缺失属性值的训练数据。
2. 分裂属性的选择——信息增益率
分裂属性选择的评判标准是决策树算法之间的根本区别。区别于ID3算法通过信息增益选择分裂属性,C4.5算法通过信息增益率选择分裂属性。
属性A的“分裂信息”(split information):
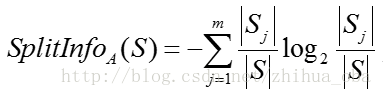
其中,训练数据集S通过属性A的属性值划分为m个子数据集,|Sj|表示第j个子数据集中样本数量,|S|表示划分之前数据集中样本总数量。
通过属性A分裂之后样本集的信息增益:

信息增益的详细计算方法,可以参考博客“决策树之ID3算法及其Python实现”中信息增益的计算。
通过属性A分裂之后样本集的信息增益率:

通过C4.5算法构造决策树时,信息增益率最大的属性即为当前节点的分裂属性,随着递归计算,被计算的属性的信息增益率会变得越来越小,到后期则选择相对比较大的信息增益率的属性作为分裂属性。
3. 连续型属性的离散化处理
当属性类型为离散型,无须对数据进行离散化处理;当属性类型为连续型,则需要对数据进行离散化处理。C4.5算法针对连续属性的离散化处理,核心思想:将属性A的N个属性值按照升序排列;通过二分法将属性A的所有属性值分成两部分(共有N-1种划分方法,二分的阈值为相邻两个属性值的中间值);计算每种划分方法对应的信息增益,选取信息增益最大的划分方法的阈值作为属性A二分的阈值。详细流程如下:
(1)将节点Node上的所有数据样本按照连续型属性A的具体取值,由小到大进行排列,得到属性A的属性值取值序列(xA1,...,xAN)。
(2)在序列(xA1,...,xAN)中共有N-1种二分方法,即共产生N-1个分隔阈值。对于第i种二分方法,其二分阈值θi=xAi+xAi+12。它将该节点上的数据集划分为2个子数据集(xA1,...,xAi)(xAi+1,...,xAN)。计算此种二分结果下的信息增益。
(3)分别计算N-1种二分结果下的信息增益,选取信息增益最大的二分结果作为对属性A的划分结果,并记录此时的二分阈值。
4. 剪枝——PEP(Pessimistic Error Pruning)剪枝法
由于决策树的建立完全是依赖于训练样本,因此该决策树对训练样本能够产生完美的拟合效果。但这样的决策树对于测试样本来说过于庞大而复杂,可能产生较高的分类错误率。这种现象就称为过拟合。因此需要将复杂的决策树进行简化,即去掉一些节点解决过拟合问题,这个过程称为剪枝。
剪枝方法分为预剪枝和后剪枝两大类。预剪枝是在构建决策树的过程中,提前终止决策树的生长,从而避免过多的节点产生。预剪枝方法虽然简单但实用性不强,因为很难精确的判断何时终止树的生长。后剪枝是在决策树构建完成之后,对那些置信度不达标的节点子树用叶子结点代替,该叶子结点的类标号用该节点子树中频率最高的类标记。后剪枝方法又分为两种,一类是把训练数据集分成树的生长集和剪枝集;另一类算法则是使用同一数据集进行决策树生长和剪枝。常见的后剪枝方法有CCP(Cost Complexity Pruning)、REP(Reduced Error Pruning)、PEP(Pessimistic Error Pruning)、MEP(Minimum Error Pruning)。
C4.5算法采用PEP(Pessimistic Error Pruning)剪枝法。PEP剪枝法由Quinlan提出,是一种自上而下的剪枝法,根据剪枝前后的错误率来判定是否进行子树的修剪,因此不需要单独的剪枝数据集。接下来详细介绍PEP(Pessimistic Error Pruning)剪枝法。
对于一个叶子节点,它覆盖了n个样本,其中有e个错误,那么该叶子节点的错误率为(e+0.5)/n,其中0.5为惩罚因子(惩罚因子一般取值为0.5)。
对于一棵子树,它有L个叶子节点,那么该子树的误判率为:
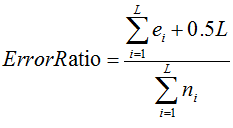
其中,ei表示子树第i个叶子节点错误分类的样本数量,ni表示表示子树第i个叶子节点中样本的总数量。
假设一棵子树错误分类一个样本取值为1,正确分类一个样本取值为0,那么子树的误判次数可以认为是一个伯努利分布,因此可以得到该子树误判次数的均值和标准差:
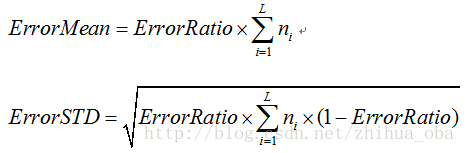
把子树替换成叶子节点后,该叶子节点的误判率为:
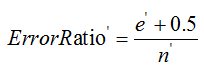
其中,e′=∑Li=1ei,n′=∑Li=1ni。
同时,该叶子结点的误判次数也是一个伯努利分布,因此该叶子节点误判次数的均值为:

剪枝的条件为:
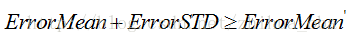
满足剪枝条件时,则将所得叶子节点替换该子树,即为剪枝操作。
5. 缺失属性值的处理
训练样本集中有可能会出现一些样本缺失了一些属性值,待分类样本中也会出现这样的情况。当遇到这样的样本集时该如何处理呢?含有缺失属性的样本集会一般会导致三个问题:
(1)在构建决策树时,每一个分裂属性的选取是由训练样本集中所有属性的信息増益率来决定的。而在此阶段,如果训练样本集中有些样本缺少一部分属性,此时该如何计算该属性的信息増益率;
(2)当已经选择某属性作为分裂属性时,样本集应该根据该属性的值来进行分支,但对于那些该属性的值为未知的样本,应该将它分支到哪一棵子树上;
(3)在决策树已经构建完成后,如果待分类样本中有些属性值缺失,则该样本的分类过程如何进行。
针对上述因缺失属性值引起的三个问题,C4.5算法有多种解决方案。
面对问题一,在计算各属性的信息増益率时,若某些样本的属性值未知,那么可以这样处理:计算某属性的信息増益率时忽略掉缺失了此属性的样本;或者通过此属性的样本中出现频率最高的属性值,賦值给缺失了此属性的样本。
面对问题二,假设属性A已被选择作为决策树中的一个分支节点,在对样本集进行分支的时候,对于那些属性A的值未知的样本,可以送样处理:不处理那些属性A未知的样本,即简单的忽略它们;或者根据属性A的其他样本的取值,来对未知样本进行赋值;或者为缺失属性A的样本单独创建一个分支,不过这种方式得到的决策树模型结点数显然要増加,使模型更加复杂了。
面对问题三,根据己经生成的决策树模型,对一个待分类的样本进行分类时,若此样本的属性A的值未知,可以这样处理:待分类样本在到达属性A的分支结点时即可结束分类过程,此样本所属类别为属性A的子树中概率最大的类别;或者把待分类样本的属性A赋予一个最常见的值,然后继续分类过程。
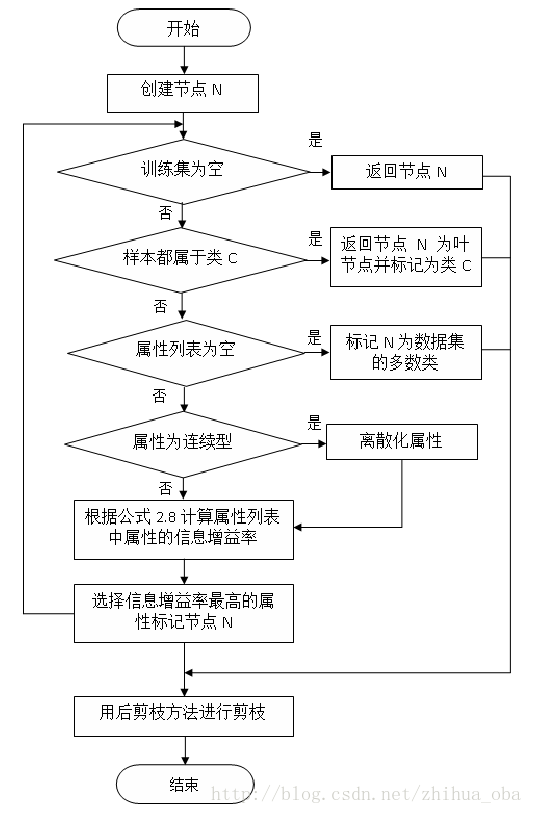
6. C4.5算法流程
7. C4.5算法优缺点分析
优点:
(1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足;
(2)能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理;
(3)构造决策树之后进行剪枝操作;
(4)能够处理具有缺失属性值的训练数据。
缺点:
(1)算法的计算效率较低,特别是针对含有连续属性值的训练样本时表现的尤为突出。
(2)算法在选择分裂属性时没有考虑到条件属性间的相关性,只计算数据集中每一个条件属性与决策属性之间的期望信息,有可能影响到属性选择的正确性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python决策树之CART分类回归树详解
决策树之CART(分类回归树)详解,具体内容如下 1.CART分类回归树简介 CART分类回归树是一种典型的二叉决策树,可以处理连续型变量和离散型变量.如果待预测分类是离散型数据,则CART生成分类决策树:如果待预测分类是连续型数据,则CART生成回归决策树.数据对象的条件属性为离散型或连续型,并不是区别分类树与回归树的标准,例如表1中,数据对象xi的属性A.B为离散型或连续型,并是不区别分类树与回归树的标准. 表1 2.CART分类回归树分裂属性的选择 2.1 CART分类树--待预测
-
python机器学习之决策树分类详解
决策树分类与上一篇博客k近邻分类的最大的区别就在于,k近邻是没有训练过程的,而决策树是通过对训练数据进行分析,从而构造决策树,通过决策树来对测试数据进行分类,同样是属于监督学习的范畴.决策树的结果类似如下图: 图中方形方框代表叶节点,带圆边的方框代表决策节点,决策节点与叶节点的不同之处就是决策节点还需要通过判断该节点的状态来进一步分类. 那么如何通过训练数据来得到这样的决策树呢? 这里涉及要信息论中一个很重要的信息度量方式,香农熵.通过香农熵可以计算信息增益. 香农熵的计算公式如下: p(xi)
-
决策树的python实现方法
本文实例讲述了决策树的python实现方法.分享给大家供大家参考.具体实现方法如下: 决策树算法优缺点: 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关的特征数据 缺点:可能会产生过度匹配的问题 适用数据类型:数值型和标称型 算法思想: 1.决策树构造的整体思想: 决策树说白了就好像是if-else结构一样,它的结果就是你要生成这个一个可以从根开始不断判断选择到叶子节点的树,但是呢这里的if-else必然不会是让我们认为去设置的,我们要做的是提供一种方法,计算机可以根
-
机器学习python实战之决策树
决策树原理:从数据集中找出决定性的特征对数据集进行迭代划分,直到某个分支下的数据都属于同一类型,或者已经遍历了所有划分数据集的特征,停止决策树算法. 每次划分数据集的特征都有很多,那么我们怎么来选择到底根据哪一个特征划分数据集呢?这里我们需要引入信息增益和信息熵的概念. 一.信息增益 划分数据集的原则是:将无序的数据变的有序.在划分数据集之前之后信息发生的变化称为信息增益.知道如何计算信息增益,我们就可以计算根据每个特征划分数据集获得的信息增益,选择信息增益最高的特征就是最好的选择.首先我们先来
-
python代码实现ID3决策树算法
本文实例为大家分享了python实现ID3决策树算法的具体代码,供大家参考,具体内容如下 ''''' Created on Jan 30, 2015 @author: 史帅 ''' from math import log import operator import re def fileToDataSet(fileName): ''''' 此方法功能是:从文件中读取样本集数据,样本数据的格式为:数据以空白字符分割,最后一列为类标签 参数: fileName:存放样本集数据的文件路径 返回值:
-
Python机器学习之决策树算法实例详解
本文实例讲述了Python机器学习之决策树算法.分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树.决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则.决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据.缺点为:可能产生过度匹配的问题.决策树适于处理离散型和连续型的数据. 在决策树中最重要的就是如何选取
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
基于ID3决策树算法的实现(Python版)
实例如下: # -*- coding:utf-8 -*- from numpy import * import numpy as np import pandas as pd from math import log import operator #计算数据集的香农熵 def calcShannonEnt(dataSet): numEntries=len(dataSet) labelCounts={} #给所有可能分类创建字典 for featVec in dataSet: currentLa
-
python编写分类决策树的代码
决策树通常在机器学习中用于分类. 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关特征数据. 缺点:可能会产生过度匹配问题. 适用数据类型:数值型和标称型. 1.信息增益 划分数据集的目的是:将无序的数据变得更加有序.组织杂乱无章数据的一种方法就是使用信息论度量信息.通常采用信息增益,信息增益是指数据划分前后信息熵的减少值.信息越无序信息熵越大,获得信息增益最高的特征就是最好的选择. 熵定义为信息的期望,符号xi的信息定义为: 其中p(xi)为该分类的概率. 熵,即信息
-
python决策树之C4.5算法详解
本文为大家分享了决策树之C4.5算法,供大家参考,具体内容如下 1. C4.5算法简介 C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸和优化.C4.5算法对ID3算法主要做了一下几点改进: (1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足: (2)能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理: (3)构造决策树之后进行剪枝操作: (4)能够处理具有缺失属性值的训练数据. 2
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python编程实现蚁群算法详解
简介 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法.它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为.蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质.针对PID控制器参数优化设计问题,将蚁群算法设计的结果与遗传算法设计的结果进行了比较,数值仿真结果表明,蚁群算法具有一种新的模拟进化优化方法的有效性和应用价值. 定义 各个蚂蚁在没有事先告诉
-
Python自然语言处理之切分算法详解
一.前言 我们需要分析某句话,就必须检测该条语句中的词语. 一般来说,一句话肯定包含多个词语,它们互相重叠,具体输出哪一个由自然语言的切分算法决定.常用的切分算法有完全切分.正向最长匹配.逆向最长匹配以及双向最长匹配. 本篇博文将一一介绍这些常用的切分算法. 二.完全切分 完全切分是指,找出一段文本中的所有单词. 不考虑效率的话,完全切分算法其实非常简单.只要遍历文本中的连续序列,查询该序列是否在词典中即可.上一篇我们获取了词典的所有词语dic,这里我们直接用代码遍历某段文本,完全切分出所有的词
-
Python集成学习之Blending算法详解
一.前言 普通机器学习:从训练数据中学习一个假设. 集成方法:试图构建一组假设并将它们组合起来,集成学习是一种机器学习范式,多个学习器被训练来解决同一个问题. 集成方法分类为: Bagging(并行训练):随机森林 Boosting(串行训练):Adaboost; GBDT; XgBoost Stacking: Blending: 或者分类为串行集成方法和并行集成方法 1.串行模型:通过基础模型之间的依赖,给错误分类样本一个较大的权重来提升模型的性能. 2.并行模型的原理:利用基础模型的独立性,
-
Python机器学习之PCA降维算法详解
一.算法概述 主成分分析 (Principal ComponentAnalysis,PCA)是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题. PCA 是最常用的一种降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度. PCA 算法目标是求出样本数据协方差矩阵的特征值和特征向量,而协方差矩阵的特征向量的方向就是PCA需要投影的方向.使样本
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
python机器学习基础特征工程算法详解
目录 一.机器学习概述 二.数据集的构成 1.数据集存储 2.可用的数据集 3.常用数据集的结构 三.特征工程 1.字典数据特征抽取 2.文本特征抽取 3.文本特征抽取:tf-idf 4.特征预处理:归一化 5.特征预处理:标准化 6.特征预处理:缺失值处理 一.机器学习概述 机器学习是从数据中,自动分析获得规律(模型),并利用规律对未知数据进行预测. 二.数据集的构成 1.数据集存储 机器学习的历史数据通常使用csv文件存储. 不用mysql的原因: 1.文件大的话读取速度慢: 2.格式不符合
-
python最小生成树kruskal与prim算法详解
kruskal算法基本思路:先对边按权重从小到大排序,先选取权重最小的一条边,如果该边的两个节点均为不同的分量,则加入到最小生成树,否则计算下一条边,直到遍历完所有的边. prim算法基本思路:所有节点分成两个group,一个为已经选取的selected_node(为list类型),一个为candidate_node,首先任取一个节点加入到selected_node,然后遍历头节点在selected_node,尾节点在candidate_node的边,选取符合这个条件的边里面权重最小的边,加入到