Linux下搭建Spark 的 Python 编程环境的方法
Spark编程环境
Spark 可以独立安装使用,也可以和Hadoop 一起安装使用。在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本。
Spark 安装
访问 Spark 下载页面 ,并选择最新版本的 Spark 直接下载,当前的最新版本是 2.4.2 。下载好之后需要解压缩到安装文件夹中,看自己的喜好,我们是安装到了 /opt 目录下。
tar -xzf spark-2.4.2-bin-hadoop2.7.tgz mv spark-2.4.2-bin-hadoop2.7/opt/spark-2.4.2
为了能在终端中直接打开 Spark 的 shell 环境,需要配置相应的环境变量。这里我由于使用的是 zsh,所以需要配置环境到 ~/.zshrc 中。
没有安装 zsh 的可以配置到 ~/.bashrc 中
# 编辑 zshrc 文件 sudo gedit ~/.zshrc # 增加以下内容:export SPARK_HOME=/opt/spark-2.4.2export PATH=$SPARK_HOME/bin:$PATH export <a href="https://www.linuxidc.com/topicnews.aspx?tid=17" target="_blank" title="Python">Python</a>PATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
配置完成后,在 shell 中输入 spark-shell 或者 pyspark 就可以进入到 Spark 的交互式编程环境中,前者是进入 Scala 交互式环境,后者是进入 Python 交互式环境。
配置 Python 编程环境
在这里介绍两种编程环境, Jupyter 和 Visual Studio Code。前者方便进行交互式编程,后者方便最终的集成式开发。
PySpark in Jupyter
首先介绍如何在 Jupyter 中使用 Spark,注意这里 Jupyter notebook 和 Jupyter lab 是通用的方式,此处以 Jupyter lab 中的配置为例:
在 Jupyter lab 中使用 PySpark 存在两种方法:
pyspark 将自动打开一个 Jupyter lab;
findSpark 包来加载 PySpark。
第一个选项更快,但特定于Jupyter笔记本,第二个选项是一个更广泛的方法,使PySpark在你任意喜欢的IDE中都可用,强烈推荐第二种方法。
方法一:配置 PySpark 启动器
更新 PySpark 启动器的环境变量,继续在 ~/.zshrc 文件中增加以下内容:
export PYSPARK_DRIVER_PYTHON=jupyter export PYSPARK_DRIVER_PYTHON_OPTS='lab'
如果要使用 jupyter notebook,则将第二个参数的值改为 notebook
刷新环境变量或者重启机器,并执行 pyspark 命令,将直接打开一个启动了 Spark 的 Jupyter lab。
pyspark

方法二:使用 findSpark 包
在 Jupyter lab 中使用 PySpark 还有另一种更通用的方法:使用 findspark 包在代码中提供 Spark 上下文环境。
findspark 包不是特定于 Jupyter lab 的,您也可以其它的 IDE 中使用该方法,因此这种方法更通用,也更推荐该方法。
首先安装 findspark:
pip install findspark
之后打开一个 Jupyter lab,我们在进行 Spark 编程时,需要先导入 findspark 包,示例如下:
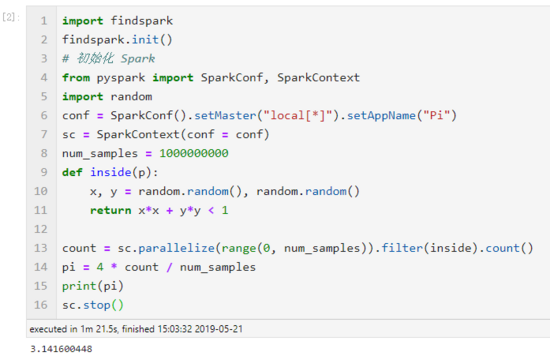
# 导入 findspark 并初始化import findspark
findspark.init()from pyspark importSparkConf,SparkContextimport random
# 配置 Spark
conf =SparkConf().setMaster("local[*]").setAppName("Pi")# 利用上下文启动 Spark
sc =SparkContext(conf=conf)
num_samples =100000000definside(p):
x, y = random.random(), random.random()return x*x + y*y <1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi =4* count / num_samples
print(pi)
sc.stop()
运行示例:
PySpark in VScode
Visual Studio Code 作为一个优秀的编辑器,对于 Python 开发十分便利。这里首先推荐个人常用的一些插件:
Python:必装的插件,提供了Python语言支持;
Code Runner:支持运行文件中的某些片段;
此外,在 VScode 上使用 Spark 就不需要使用 findspark 包了,可以直接进行编程:
from pyspark importSparkContext,SparkConf
conf =SparkConf().setMaster("local[*]").setAppName("test")
sc =SparkContext(conf=conf)
logFile ="file:///opt/spark-2.4.2/README.md"
logData = sc.textFile(logFile,2).cache()
numAs = logData.filter(lambda line:'a'in line).count()
numBs = logData.filter(lambda line:'b'in line).count()print("Lines with a: {0}, Lines with b:{1
总结
以上所述是小编给大家介绍的Linux下搭建Spark 的 Python 编程环境的方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-

linux环境下的python安装过程图解(含setuptools)
这里我不想采用诸如ubuntu下的apt-get install方式进行python的安装,而是在linux下采用源码包的方式进行python的安装. 一.下载python源码包 打开ubuntu下的shell终端,通过wget命令下载python源码包,如下图所示: 将python-2.7.3.tgz下载至/opt目录下. 二.python的解压 三.python的编译与安装 在对python进行编译之前,必须对它进行配置.在unix/linux平台上的安装过程中,配置和编译过程全部已经自动化
-
详解linux下安装python3环境
1.linux下安装python3 a. 准备编译环境(环境如果不对的话,可能遇到各种问题,比如wget无法下载https链接的文件) yum groupinstall 'Development Tools' yum install zlib-devel bzip2-devel openssl-devel ncurses-devel 2 下载 Python3.5代码包 wget https://www.python.org/ftp/python/3.5.0/Python-3.5.0.tar.xz
-
Linux搭建python环境详解
一.下载文件 python官网:https://www.python.org/downloads/ 版本:python-2.7.3 下载地址:http://www.jb51.net/softs/2293.html setuptools官网:https://pypi.python.org/pypi/setuptools#downloads 版本:setuptools-0.6c11 pip官网:https://pypi.python.org/pypi/pip#downloads 版本:pip-1.5
-
Linux环境下python2.7.6升级python3.5.2
需求 Linux环境下有些是自带的Python2版本有时是刚安装号的Python其他版本,当新版本出来的时候,在开发的时候往往会选择新版本的软件进行安装. 原因 在开发的时候选用新版本的软件进行安装的时候,出于以下角度来考虑的. 老版本的一些第三方软件库会随着新版本软件的更新,老本版所支持的第三方库就没有人去维护和更新了,后面在使用的过程中,如果出现了bug,就会花很大的精力去解决. 步骤 基于上面的要求,我将生产虚机上的ython2.7.6升级python3.5.2,主要步骤如下所示: 去py
-
Linux安装Python虚拟环境virtualenv的方法
1.安装virtulenv.virtulenvwrapper包 pip install virtualenv virtualenvwrapper 2.virtualenvwrapper是virtualenv的扩展工具,可以方便的创建.删除.复制.切换不同的虚拟环境. 3. 设置环境变量,把下面两行添加到~/.bash_profile里 export WORKON_HOME=/software/venv source /usr/local/bin/virtualenvwrapper.sh 4.使环
-
Linux RedHat下安装Python2.7开发环境
Linux RedHat下安装Python2.7.pip.ipython环境.eclipse和PyDev环境 准备工作,源Python2.6备份: 根据which python具体目录而定,进行备份 mv /usr/local/bin/python cd /usr/local/bin/python2.6 或mv /usr/bin/python /usr/bin/python2.6 修改使用python2.6的程序配置,比如yum vim /usr/bin/yum #!/usr/bin/pytho
-
linux环境不使用hadoop安装单机版spark的方法
大数据持续升温, 不熟悉几个大数据组件, 连装逼的口头禅都没有. 最起码, 你要会说个hadoop, hdfs, mapreduce, yarn, kafka, spark, zookeeper, neo4j吧, 这些都是装逼的必备技能. 关于spark的详细介绍, 网上一大堆, 搜搜便是, 下面, 我们来说单机版的spark的安装和简要使用. 0. 安装jdk, 由于我的机器上之前已经有了jdk, 所以这一步我可以省掉. jdk已经是很俗气的老生常谈了, 不多说, 用java/scala的
-
linux环境下python中MySQLdb模块的安装方法
前言 最近开始学习python数据库编程后,在了解了基本概念,打算上手试验一下时,卡在了MYSQLdb包的安装上,折腾了半天才解决.记录一下我在linux中安装此包遇到的问题. 系统是ubuntn15.04. 1.下载 第一个问题是pycharm软件的模块安装功能Project Interpreter无法自动下载安装MYSQLdb包,显示 Error occurred when installling package 那没办法了,只好手动下载了.MYSQLdb包linux系统的下载的地址是:ht
-
Linux下搭建Spark 的 Python 编程环境的方法
Spark编程环境 Spark 可以独立安装使用,也可以和Hadoop 一起安装使用.在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本. Spark 安装 访问 Spark 下载页面 ,并选择最新版本的 Spark 直接下载,当前的最新版本是 2.4.2 .下载好之后需要解压缩到安装文件夹中,看自己的喜好,我们是安装到了 /opt 目录下. tar -xzf spark-2.4.2-bin-hadoop2.7.tgz mv spark-2.4.2-bin-ha
-
Docker下搭建一个JAVA Tomcat运行环境的方法
前言 Docker旨在提供一种应用程序的自动化部署解决方案,在 Linux 系统上迅速创建一个容器(轻量级虚拟机)并部署和运行应用程序,并通过配置文件可以轻松实现应用程序的自动化安装.部署和升级,非常方便.因为使用了容器,所以可以很方便的把生产环境和开发环境分开,互不影响,这是 docker 最普遍的一个玩法.更多的玩法还有大规模 web 应用.数据库部署.持续部署.集群.测试环境.面向服务的云计算.虚拟桌面 VDI 等等. 主观的印象:Docker 使用 Go 语言编写,用 cgroup 实现
-
Linux下安装IPython配置python开发环境教程
一.IPython简介 IPython 是一个交互式的shell,比默认终端好用,支持自动缩进,并且内置了很多有用的功能和函数.可以在任何操作系统上使用. 二.安装方法 1.pip 在线安装 pip install ipython pip install "ipython[notebook]" 2.下载安装 可以到GitHub 下载安装包,切换到目录下然后运行下面的脚本 Python setup.py install 三.简单使用 打开Linux终端,在命令行中输入 root@Linu
-
win7 下搭建sublime的python开发环境的配置方法
Step1:安装python和sublime Step2:给sublime安装package control,安装参见: 官网 Step3:配置安装路径 方式一:配置windows的Path 好处就是cmd的时候也可以运行,视为系统,用户级别的配置: 方式二:配置sublime的python的sublime_build 点击:Preference -> Browse Packages -> 在python目录下,编辑Python.sublime-build文件,添加python应用程序的路径:
-
MongoDB学习笔记—Linux下搭建MongoDB环境
1.MongoDB简单说明 a MongoDB是由C++语言编写的一个基于分布式文件存储的开源数据库系统,它的目的在于为WEB应用提供可扩展的高性能数据存储解决方案. b MongoDB是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库当中功能最丰富,最像关系型数据库的.它支持的数据结构非常松散,会将数据存储为一个文档,数据结构由键值对(key=>value)组成,是类似于json的bson格式, c MongoDB最大的特点就是它支持的查询语言非常强大,其语法有点类似于面向对象
-
linux下搭建go环境的安装配置讲解
linux下搭建go环境很简单: 1.下载go1.2.1.linux-386.tar.gz,网上到处有类似包,并放到linux目录下. taogeqq@taogeqq-virtual-machine:~/myspace$ ls a.out go1.2.1.linux-386.tar.gz test.cpp test.go taogeqq@taogeqq-virtual-machine:~/myspace$ 2. 切换到root用户,在root下解压,解压即安装,多么绿色的软件啊: root@t
-
Ubuntu Server 20.04 LTS 环境下搭建vim 编辑器Python IDE的详细步骤
目录 安装配置vim-plug 安装vim-plug 配置vim-plug 安装coc.nvim插件 更新vim 安装node 添加coc.nvim到.vimrc文件 配置服务器 设置TAB 代码补全 设置F5一键执行代码 安装配置vim-plug 安装vim-plug curl -fLo ~/.vim/autoload/plug.vim --create-dirs \ https://raw.githubusercontent.com/junegunn/vim-plug/master/plug
-
在 Windows 下搭建高效的 django 开发环境的详细教程
从初学 django 到现在(记得那时最新版本是 1.8,本文发布时已经发展到 3.1 了),开发环境一直都是使用从官方文档或者别的教程中学来的方式搭建的.但是在实际项目的开发中,越来越感觉之前的开发环境难以适应项目的发展.官方文档或一些教程中的环境搭建方式主要存在这些问题: python manage.py runserver 启动的开发服务器热重载非常慢,尤其是当项目中导入了大量模块时,有时候改一次代码要等几秒钟才能完成重载. 主力开发环境为 Windows + PyCharm,然而有时候依
-
Linux下安装或升级Python 2.7的操作方法
1.准备编译环境gcc 2.去官网下载要安装的对应版本的python的源代码 下载地址:https://www.python.org/downloads/source/ 你可以选择你要下载的版本,用wget指令来下载相应的源代码 3.解压下载的代码包 tar -zxvf Python-x.x.x.tgz cd Python-x.x.x 4.配置 1)查找configure文件 find . -name configure cd 搜索结果(一般就在Python文件根目录下) 2)进行配置 ./co
-
linux下安装配置Memcache和PHP环境的实现
亲测有效 在网上查找了好多资料,很多都安装不成功,而且都是同一个资料相互抄袭泛蓝,没一个实用的.今天配置好了,将配置过程分享一下. Linux下的Memcache运行需要libevent的支持,所以在安装memcache之前必须要安装libevent.安装过程中可能会遇到很多问题,本人都将可能遇到错误时的解决办法整理出来了. 1.先安装libevent: #yum -y install libevent libevent-devel 2.安装memcached,最新版本为:memcached-1