js逆向解密之网络爬虫
1 引言
数月前写过某网站(请原谅我的掩耳盗铃)的爬虫,这两天需要重新采集一次,用的是scrapy-redis框架,本以为二次爬取可以轻松完成的,可没想到爬虫启动没几秒,出现了大堆的重试提示,心里顿时就咯噔一下,悠闲时光估计要结束了。
仔细分析后,发现是获取店铺列表的请求出现问题,通过浏览器抓包,发现请求头参数中相比之前多了一个X-Shard和x-uab参数,如下图所示:
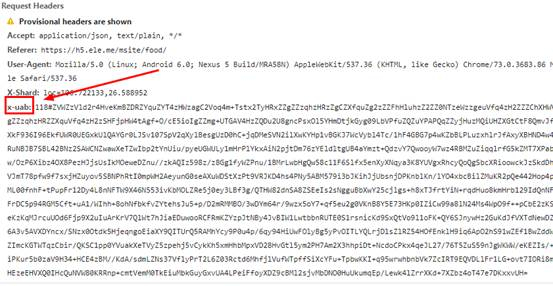
X-Shard倒是没什么问题,一看就是兴趣点的经纬度,但x-uab看过之后就让人心里苦了,js加密啊,只能去逆向解密了。
2 js逆向求解
最直接的思路是根据“x-uab”关键字在所有关键中查找(chrome浏览器-source中按ctrl + shift + F快捷键),结果如下所示:

接下来,打个断点调试一下:在数字那里点一下,数字位置出现蓝点,表示添加断点成功,然后刷新获取店铺列表的页面,程序会在断点处停下。如下所示:
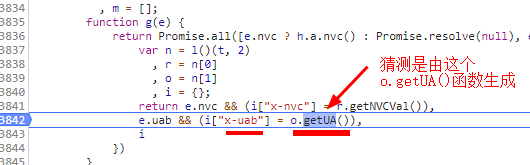
在控制台调试o.getUA()函数,看一下输出:
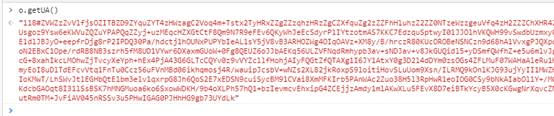
果然是,证明猜测没错,就是这个o.getUA()函数负责生成请求头中的x-uab参数。
继续向下查看这个getUA()函数的引用(把光标放在要查看的函数上,就可以查看这个函数的引用),就是下图这个函数:

图中的s就是我们要的x-uab参数,下图在控制台输出可以证明:
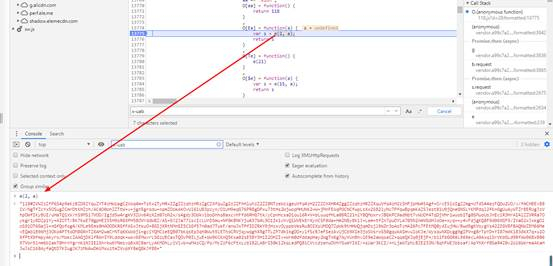
所以,u-xab是这里的e生成的,而函数e传入的参数中,第一个是常量2,第二个参数a是undefined,呵,看起来没有传其它参数。继续向下找这个e(2,a)函数:
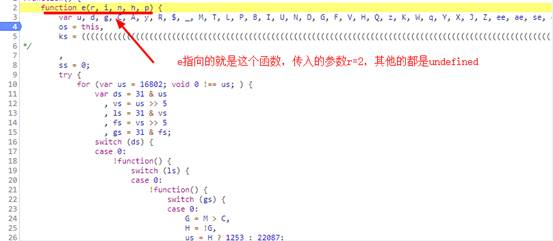
就是这个function e(r, i, n, h, p) 方法,直接运行可以获取加密后的参数。把这个function e(r, i, n, h, p) 方法全部代码取出来,另存为一个js文件。
回到顶部
3 撸代码
3.1 方案一
你以为上面找出生成x-uab的js代码,就大功告成了吗?少年,you are too young too simple!
怎么把这段js脚本运行起来,才是关(nan)键(dian)。
这个function e(r, i, n, h, p) 函数有近4万行代码,重新用Python实现难(jiu)度(shi)有(bu)点(ke)大(neng)。所以,我选择直接用Python来执行这段js脚本。
怎么用python执行js脚本,度娘会给你一堆资料,自己查吧。我这里选择的是execjs。
因为在上面复制出来的脚本中,只单单定义了一个e(r, i, n, h, p)方法,并没有调用这个方法,所以,我要要在js文件的末尾添加一些代码来调用:
function getParam() {
var a;
var param = e(2,a);
return param
};
然后,开始撸Python代码吧:
import execjs node = execjs.get() file = 'eleme.js' ctx = node.compile(open(file).read()) js_encode = 'getParam()' params = ctx.eval(js_encode) print(params)
尝试执行,心凉,代码异常:
execjs._exceptions.ProgramError: TypeError: 'window' 未定义
window对象估计是浏览器打开是创建的,蕴含浏览器的信息,所以用Python来执行这段代码时,没有这个对西乡。本来想尝试伪造window对象,但查找之后发现js脚本中上百个地方用到window,这还没完,代码经过混淆,在下水平不够,没法追根溯源(这地方困扰了我许久,哪位前辈如果知道方法,请告知)。
后来,从一个前辈那里(感谢前辈)获知一个方法绕过去。这个前辈的方法是将execjs的引擎换成PhantomJS这个无头浏览器(之前用的引擎是node.js),换句话说就是用PhantomJS来执行js脚本,PhantomJS是一个浏览器,自然就会创建window对象。
使用PhantomJS之前,需要下载它的驱动,然后放下Python代码统一目录下。对之前的Python代码也进行修改:
import execjs import os os.environ["EXECJS_RUNTIME"] = "PhantomJS" node = execjs.get() file = 'eleme.js' ctx = node.compile(open(file).read()) js_encode = 'getParam()' params = ctx.eval(js_encode) print(params)
果然,按照这个方法,成功获取加密字符串。
3.2 方案二
事实上,这个方案二才是我在出现未定义window对象异常后首先尝试的方法,不过因为往js代码中添加的js脚本有问题,以为行不通,所以请教前辈,得到了方案一。
方案二的思路和方案一类似,不过更加粗暴一些。不是因为没在浏览器执行,造成没有window对象吗?那我就模拟浏览器来执行。
在执行之前,同样要修改js脚本,在js文件末尾调用e方法,添加如下代码:
var a; var param = e(2,a); return param;
切记:不要放在任何函数里面,我之前就是因为将这段代码放在函数里头强制执行,导致的结果就是在浏览器里可以获取加密字符串,但是在Python中获取到的却是None。
模拟浏览器用的selenium和chrome的webDriver,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
with open('eleme.js', 'r') as f:
js = f.read()
print(browser.execute_script(js))
这个方法也是可以获得加密之后的字符串。
最后,有必要说一下的是,如果需要获取大量的x-uab,采用方案二效率会高一下,因为采用方案二的话,可以自打开一个浏览器(都调用一个webdriver对象),然后快速执行js,返回加密字符串。
4 总结
一次js逆向解密,算是完成了吧。但是也留下了一些问题:
(1)使用chrome断点调试时,js脚本都是压缩混淆之后的,通过chrome的pretty print功能(也就是说那对花括号)可以格式美化,但是,有的时候却会失败,就像下图,格式化后,还是一团糟:
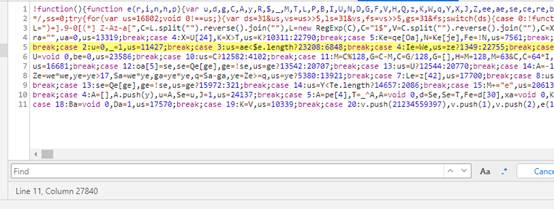
这个问题耽搁了我很长时间,没法调试啊!
(2)在下js基础不行,很困惑为什么运行时,先通过o.getUA()调用e函数内的嵌套函数,然后e函数内部嵌套函数中调用e方法本身,这是什么操作?函数调用不都应该先外层函数,然后再调用嵌套函数吗?
(3)如果不适用浏览器执行js的方法,就只能替换window对象,这该如何操作?
(4)这个e函数有近4万行,一个加密函数这么多代码,我可不信,里面肯定很多事混淆视听用的,但我尝试调试追踪过,只能说混淆之后让我无从追踪,头晕。怎么才能简化这段脚本呢?
如果哪位前辈可以解惑,请一定告知,不胜感激!拜谢!
相关推荐
-

JavaScript实现的简单加密解密操作示例
本文实例讲述了JavaScript实现的简单加密解密操作.分享给大家供大家参考,具体如下: JavaScript实现对内容的加密和解密.加密,转成编码.解密则是编码转字符串. <html> <head> <meta charset="utf-8" /> <title>www.jb51.net JS加密解密</title> </head> <body> <h1> 加密解密 </h1>
-
JS实现的3des+base64加密解密算法完整示例
本文实例讲述了JS实现的3des+base64加密解密算法.分享给大家供大家参考,具体如下: 1. index.html: <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>www.jb51.net BASE64编码</title> <meta http-equiv="Content-Type" content="text/html; c
-
JS实现的base64加密解密操作示例
本文实例讲述了JS实现的base64加密解密操作.分享给大家供大家参考,具体如下: <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>js base64加密解密</title> </head> <body> <script> // 创建Base64对象 var Base64 = { _keyStr: &qu
-
JS通过位运算实现权限加解密
首先介绍一下js中的位运算: 1. "&" :与运算,转化为二进制数,如果相同位数都为1则得结果为1,否则为0: 2. "|" :或运算,转化为二进制数,如果相同位数只要有一个为1则得结果为1,否则为0: 3. "^" :异或运算,转化为二进制数,如果相同位数不同则得结果为1,否则为0: 4."<<" 异位运算符,1<<1,表示将1左移一位,也就是010,在二进制中代表2: 顺便说一下,十进制数
-
js逆向解密之网络爬虫
1 引言 数月前写过某网站(请原谅我的掩耳盗铃)的爬虫,这两天需要重新采集一次,用的是scrapy-redis框架,本以为二次爬取可以轻松完成的,可没想到爬虫启动没几秒,出现了大堆的重试提示,心里顿时就咯噔一下,悠闲时光估计要结束了. 仔细分析后,发现是获取店铺列表的请求出现问题,通过浏览器抓包,发现请求头参数中相比之前多了一个X-Shard和x-uab参数,如下图所示: X-Shard倒是没什么问题,一看就是兴趣点的经纬度,但x-uab看过之后就让人心里苦了,js加密啊,只能去逆向解密了. 2
-
从零学习node.js之简易的网络爬虫(四)
前言 之前已经介绍了node.js的一些基本知识,下面这篇文章我们的目标是学习完本节课程后,能进行网页简单的分析与抓取,对抓取到的信息进行输出和文本保存. 爬虫的思路很简单: 确定要抓取的URL: 对URL进行抓取,获取网页内容: 对内容进行分析并存储: 重复第1步 在这节里做爬虫,我们使用到了两个重要的模块: request : 对http进行封装,提供更多.更方便的接口供我们使用,request进行的是异步请求.更多信息可以去这篇文章上进行查看 cheerio : 类似于jQuery,可以使
-
Python爬虫实战JS逆向AES逆向加密爬取
目录 爬取目标 工具使用 项目思路解析 简易源码分享 爬取目标 网址:监管平台 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,AES,json 涉及AES对称加密问题 需要 安装node.js环境 使用npm install 安装 crypto-js 项目思路解析 确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的? 突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第
-
Java实现爬虫给App提供数据(Jsoup 网络爬虫)
一.需求 最近基于 Material Design 重构了自己的新闻 App,数据来源是个问题. 有前人分析了知乎日报.凤凰新闻等 API,根据相应的 URL 可以获取新闻的 JSON 数据.为了锻炼写代码能力,笔者打算爬虫新闻页面,自己获取数据构建 API. 二.效果图 下图是原网站的页面 爬虫获取了数据,展示到 APP 手机端 三.爬虫思路 关于App 的实现过程可以参看这几篇文章,本文主要讲解一下如何爬虫数据. Android下录制App操作生成Gif动态图的全过程 :http://www
-
利用C#实现网络爬虫
网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具. 接下来就介绍一下爬虫的简单实现. 爬虫的工作流程如下 爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止. 下面开始逐步分析爬虫的实现. 1. 待下载集合与已下载集合 为了保存需要下载的URL,同时防止重复下载,我们需要分别用了两个集合来存放将要下载的URL和已经下载的URL. 因为在保存URL的同时需要保存与URL相关的一些其他信息,如深度,所以这里我采用了Dictionary来存放这些UR
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
利用Python网络爬虫爬取各大音乐评论的代码
python爬虫--爬取网易云音乐评论 方1:使用selenium模块,简单粗暴.但是虽然方便但是缺点也是很明显,运行慢等等等. 方2:常规思路:直接去请求服务器 1.简易看出评论是动态加载的,一定是ajax方式. 2.通过网络抓包,可以找出评论请求的的URL 得到请求的URL 3.去查看post请求所上传的数据 显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密. 4.首先去查看请求是经过那些js到达服务器的 5.设置断点:依次对所发送的内容进行观察,找到评论对应的UR
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
JS逆向之爱奇艺滑块加密的实现
目录 前言 一.页面分析 二.分析 1.分裂图片还原 2.动态AESKey,HMacKey 3.cryptSrcData加密 4.返回数据解密 总结 文章仅供参考,禁止用于非法途径 前言 目标网站:aHR0cHM6Ly93d3cuaXFpeWkuY29tL2lmcmFtZS9sb2dpbnJlZz92ZXI9MQ== 一.页面分析 切换账密登入,抓包,登入接口有个passsword,rsa加密的 然后多点几次就会出现验证码 二.分析 1.分裂图片还原 下个canvas断点即可知道如何还原 2.动
-
Python网络爬虫出现乱码问题的解决方法
关于爬虫乱码有很多各式各样的问题,这里不仅是中文乱码,编码转换.还包括一些如日文.韩文 .俄文.藏文之类的乱码处理,因为解决方式是一致的,故在此统一说明. 网络爬虫出现乱码的原因 源网页编码和爬取下来后的编码格式不一致. 如源网页为gbk编码的字节流,而我们抓取下后程序直接使用utf-8进行编码并输出到存储文件中,这必然会引起乱码 即当源网页编码和抓取下来后程序直接使用处理编码一致时,则不会出现乱码; 此时再进行统一的字符编码也就不会出现乱码了 注意区分 源网编码A. 程序直接使用的编码B. 统