使用pandas模块读取csv文件和excel表格,并用matplotlib画图的方法
如下所示:
# coding=utf-8
import pandas as pd
# 读取csv文件 3列取名为 name,sex,births,后面参数格式为names=
names1880 = pd.read_csv("names_1880.txt", names=['name', 'sex', 'births'])
print names1880
print names1880.groupby('sex').births.sum()
输出如下
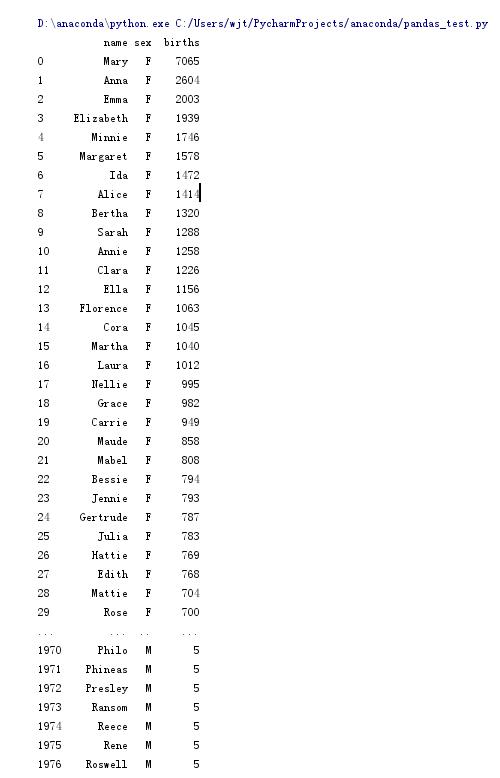
最后一行是说按sex分组并计算births的和
import pandas as pd
import matplotlib as mb
import matplotlib.pyplot as plt
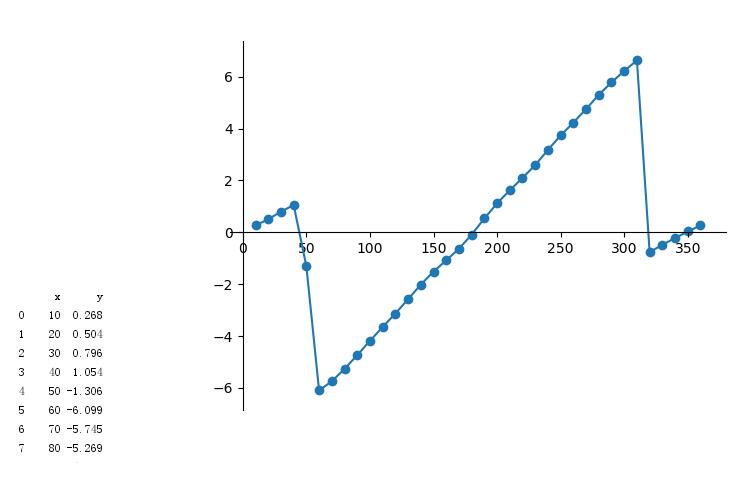
xls = pd.read_excel('phase_detector.xlsx',names=['x','y'])
print xls
# 原点相交
ax = plt.gca()
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
# 去掉边框
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
plt.plot(xls.x, xls.y)
plt.scatter(xls.x, xls.y)
plt.savefig('aa.png')
plt.show()
以上这篇使用pandas模块读取csv文件和excel表格,并用matplotlib画图的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python使用pandas处理excel文件转为csv文件的方法示例
由于客户提供的是excel文件,在使用时期望使用csv文件格式,且对某些字段内容需要做一些处理,如从某个字段中固定的几位抽取出来,独立作为一个字段等,下面记录下使用acaconda处理的过程: import pandas df = pandas.read_excel("/***/***.xlsx") df.columns = [内部为你给你的excel每一列自定义的名称](比如我给我的excel自定义列表为: ["url","productName&quo
-
使用pandas实现csv/excel sheet互相转换的方法
1. xlsx to csv: import pandas as pd def xlsx_to_csv_pd(): data_xls = pd.read_excel('1.xlsx', index_col=0) data_xls.to_csv('1.csv', encoding='utf-8') if __name__ == '__main__': xlsx_to_csv_pd() 2. csv to xlsx: import pandas as pd def csv_to_xlsx_pd():
-
使用pandas模块读取csv文件和excel表格,并用matplotlib画图的方法
如下所示: # coding=utf-8 import pandas as pd # 读取csv文件 3列取名为 name,sex,births,后面参数格式为names= names1880 = pd.read_csv("names_1880.txt", names=['name', 'sex', 'births']) print names1880 print names1880.groupby('sex').births.sum() 输出如下 最后一行是说按sex分组并计算bir
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-

使用pandas生成/读取csv文件的方法实例
前言 csv是我接触的比较早的一种文件,比较好的是这种文件既能够以电子表格的形式查看又能够以文本的形式查看. 先引入pandas库 import pandas as pd 方法一: 1.我构造了一个cont_list,结构为列表嵌套字典,字典是每一个样本,类似于我们爬虫爬下来的数据的结构 2.利用pd.DataFrame方法先将数据转换成一个二维结构数据,如下方打印的内容所示,cloumns指定列表,列表必须是列表 3.to_csv方法可以直接保存csv文件,index=False表示csv文件
-
使用pandas read_table读取csv文件的方法
read_csv是pandas中专门用于csv文件读取的功能,不过这并不是唯一的处理方式.pandas中还有读取表格的通用函数read_table. 接下来使用read_table功能作一下csv文件的读取尝试,使用此功能的时候需要指定文件中的内容分隔符. 查看csv文件的内容如下: In [10]: cat data.csv index,name,comment,,,, 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,come
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-
Jupyter Notebook读取csv文件出现的问题及解决
目录 Jupyter Notebook读取csv文件失败 Excel跨表使用注意事项(包含jupyter读取csv) (1)问题 (2)问题 (3)问题 总结 Jupyter Notebook读取csv文件失败 1.IndentationError: expected an indented block 缩进错误,在报错代码块前加一个空格. 在data前加一个空格. 2.No such file or directory: ‘weatherdata.csv’ 找不到文件,我的weatherdat
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
pandas读取CSV文件时查看修改各列的数据类型格式
下面给大家介绍下pandas读取CSV文件时查看修改各列的数据类型格式,具体内容如下所述: 我们在调bug的时候会经常查看.修改pandas列数据的数据类型,今天就总结一下: 1.查看: Numpy和Pandas的查看方式略有不同,一个是dtype,一个是dtypes print(Array.dtype) #输出int64 print(df.dtypes) #输出Df下所有列的数据格式 a:int64,b:int64 2.修改 import pandas as pd import numpy a
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs