python分析作业提交情况
这次做一个比较贴近我实际的东西:python分析作业提交情况。
要求:
将服务器中交作业的学生(根据文件的名字进行提取)和统计成绩的表格中的学生的信息进行比对,输出所有没有交作业的同学的信息(学号和姓名),并输出所交的作业中命名格式有问题的文件名的信息(如1627406012_E03....)。
提示:
提示:
1、根据服务器文件可以拿到所有交了作业的同学的信息。
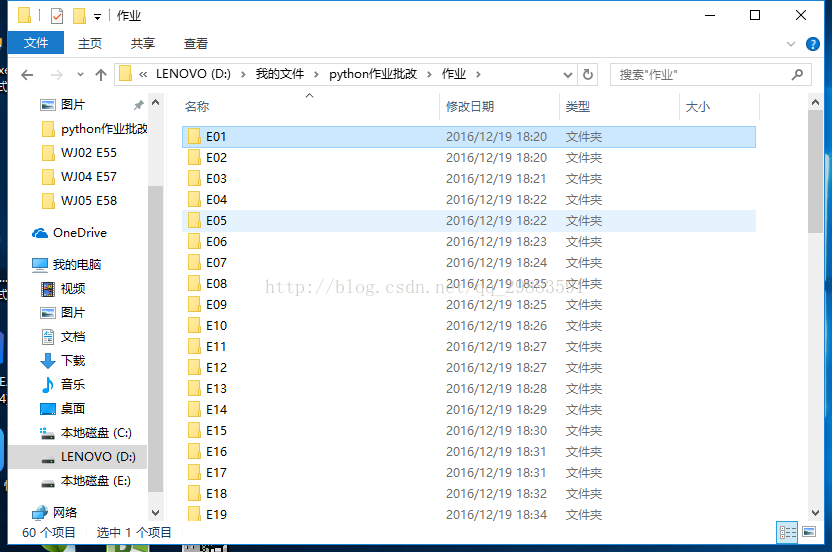

2、根据表格可以拿到所有上课学生的信息
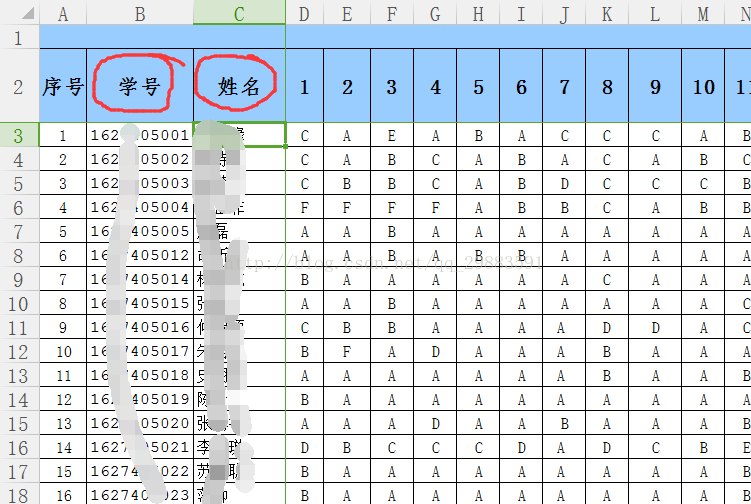
3、对1和2中的信息进行比对,找出想要得到的信息
注意:提取服务器中学生交的作业的信息的时候应该考虑到文件格式不对的情况,所以提取信息的时候要做好相关的处理,以避免异常。
下面直接上程序(python3的版本):
#coding:utf-8
import os
import xlrd
"""
此函数用于获取dir文件夹中的文件的内容,dir中不能含有中文名
"""
def getFilesInfo(dir):
fileNum=dir[len(dir)-2:len(dir)] # 取得题目的编号
trueList=[]
errorList=[]
t=os.walk(dir)
for item in t:
for name in item[2]:
if len(name)!=18:
errorList.append(name)
else:
if name[13:15]==fileNum:
trueList.append(name[0:10])
else:
errorList.append(name)
return [trueList,errorList]
# 此函数用于读取xml表格文件中的内容
def readTableContent(fileName):
date=xlrd.open_workbook(fileName)
# sheet_name = date.sheet_names()[0]
stuList=[] # 存放学号和姓名
try: # 获取你要处理的XLS的第一张表
sh = date.sheet_by_index(0)
except:
print("出现问题")
for i in range(2,sh.nrows):
id=sh.row_values(i)[1]
name=sh.row_values(i)[2]
student=(id,name); # 存放学生的学号和姓名的元组
stuList.append(student)
return stuList
address="D://我的文件/python作业批改/2016级老姜班级作业成绩 2016-10-25.xls"
submitStuList=getFilesInfo("D:\E01")
stuList=readTableContent(address) # 存放学生的信息的列表
notSubmitStudent=[] # 存放没有提交作业的学生的信息
for student in stuList:
if student[0] not in submitStuList [0]:
notSubmitStudent.append(student)
print("===================没有交作业的人为=============")
for student in notSubmitStudent:
print(student[0],student[1])
print("===================格式错误的文件为=============")
for error in submitStuList[1]:
print(error)
对于上面的程序中,用到了一个读取表格的包xlrd,这个包需要自己进行下载,在pycharm中,直接进行如下步骤的下载:
1、首先进行如下操作:
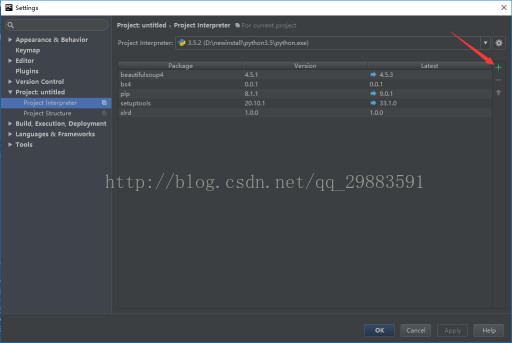
2、然后点击“+”号(由于我是提前下载好了的,所以下面的图中有xlrd的包):
3、在输入框中输入包名并搜索
4、完成安装:

关于程序中使用到的os和xlrd的相关知识可以自行查阅相关的文档,这里不再进行详细说明。
下面是py2.7版本的程序:
#coding:utf-8
import os
import xlrd
import xlwt
"""
此函数用于获取dir文件夹中的文件的内容,dir中不能含有中文名
"""
def getFilesInfo(dir):
fileNum=dir[len(dir)-2:len(dir)] # 取得题目的编号
trueList=[]
errorList=[]
t=os.walk(dir)
for item in t:
for name in item[2]:
if len(name)!=18:
errorList.append(name)
else:
if name[13:15]==fileNum:
trueList.append(name[0:10])
else:
errorList.append(name)
return [trueList,errorList]
# 此函数用于读取xml表格文件中的内容
def readTableContent(fileName):
date=xlrd.open_workbook(fileName)
# sheet_name = date.sheet_names()[0]
stuList=[] # 存放学号和姓名
try: # 获取你要处理的XLS的第一张表
sh = date.sheet_by_index(0)
except:
print "出现问题"
for i in range(2,sh.nrows):
id=sh.row_values(i)[1].encode('utf-8')
name=sh.row_values(i)[2]
student=(id,name); # 存放学生的学号和姓名的元组
stuList.append(student)
return stuList
address=unicode("D://我的文件/python作业批改/2016级老姜班级作业成绩 2016-10-25.xls",'utf-8') # 对于中文名的路径要进行转换
submitStuList=getFilesInfo("D:\E01")
stuList=readTableContent(address) # 存放学生的信息的列表
notSubmitStudent=[] # 存放没有提交作业的学生的信息
for student in stuList:
if student[0] not in submitStuList [0]:
notSubmitStudent.append(student)
print "===============没有交作业的人为============="
for student in notSubmitStudent:
print student[0],student[1]
print "===============格式错误的文件为============="
for error in submitStuList[1]:
print error
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python正则表达式之作业计算器
作业:计算器开发 实现加减乘除及拓号优先级解析 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式,运算后得出结果,结果必须与真实的计算器所得出的结果一致 一.说明: 有一点bug就是不能计算幂次方,如:'6**6'会报错 该计算器思路: 1.没用使用递归,先找出并计算所有括号里的公式,再计算乘除
-
Python使用Redis实现作业调度系统(超简单)
概述 Redis是一个开源,先进的key-value存储,并用于构建高性能,可扩展的Web应用程序的完美解决方案. Redis从它的许多竞争继承来的三个主要特点: Redis数据库完全在内存中,使用磁盘仅用于持久性. 相比许多键值数据存储,Redis拥有一套较为丰富的数据类型. Redis可以将数据复制到任意数量的从服务器. Redis 优势 异常快速:Redis的速度非常快,每秒能执行约11万集合,每秒约81000+条记录. 支持丰富的数据类型:Redis支持最大多数开发人员已经知道像列表,集
-
Python基于回溯法子集树模板解决最佳作业调度问题示例
本文实例讲述了Python基于回溯法子集树模板解决最佳作业调度问题.分享给大家供大家参考,具体如下: 问题 给定 n 个作业,每一个作业都有两项子任务需要分别在两台机器上完成.每一个作业必须先由机器1 处理,然后由机器2处理. 试设计一个算法找出完成这n个任务的最佳调度,使其机器2完成各作业时间之和达到最小. 分析: 看一个具体的例子: tji 机器1 机器2 作业1 2 1 作业2 3 1 作业3 2 3 最优调度顺序:1 3 2 处理时间:18 这3个作业的6种可能的调度方案是1,2,3:1
-
Python利用multiprocessing实现最简单的分布式作业调度系统实例
介绍 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上.一个服务进程可以作为调度者,将任务分布到其他多个机器的多个进程中,依靠网络通信.想到这,就在想是不是可以使用此模块来实现一个简单的作业调度系统.在这之前,我们先来详细了解下python中的多进程管理包multiprocessing. multiprocessing.Process multiprocessing包是Python中的多进程管理包.它与 threading.
-
Python使用multiprocessing实现一个最简单的分布式作业调度系统
mutilprocess像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多. 介绍 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上.一个服务进程可以作为调度者,将任务分布到其他多个机器的多个进程中,依靠网络通信. 想到这,就在想是不是可以使用此模块来实现一个简单的作业调度系统. 实现 Job 首先创建一个Job类,为了测试简单,只包含一
-
python分析作业提交情况
这次做一个比较贴近我实际的东西:python分析作业提交情况. 要求: 将服务器中交作业的学生(根据文件的名字进行提取)和统计成绩的表格中的学生的信息进行比对,输出所有没有交作业的同学的信息(学号和姓名),并输出所交的作业中命名格式有问题的文件名的信息(如1627406012_E03....). 提示: 提示: 1.根据服务器文件可以拿到所有交了作业的同学的信息. 2.根据表格可以拿到所有上课学生的信息 3.对1和2中的信息进行比对,找出想要得到的信息 注意:提取服务器中学生交的作业的信息的时候
-
Python分析学校四六级过关情况
这段时间看了数据分析方面的内容,对Python中的numpy和pandas有了最基础的了解.我知道如果我不用这些技能做些什么的话,很快我就会忘记.想起之前群里发过一个学校的四六级成绩表,正好可以用来熟悉一下pandas中的一些用法. 1.数据介绍. 成绩表中包含的字段十分详细,里面有年级.性别.姓名.分数等等的一系列内容,我只想简单的分析一下我们学校的四六级过关率而已,所以去除了一些不必要的字段.留下的有如下几个字段: 第一列是自增的序号,没有什么实际意义. 第二列就是代表着该学生参加的是四级还
-
python通过post提交数据的方法
本文实例讲述了python通过post提交数据的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: cp936 -*- import urllib2 import urllib def postHttp(name=None,tel=None,address=None, price=None,num=None,paytype=None, posttype=None,other=None): url="http://www.xxx.com/dog.php" #定义要
-
python使用urllib2提交http post请求的方法
本文实例讲述了python使用urllib2提交http post请求的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/python #coding=utf-8 import urllib import urllib2 def post(url, data): req = urllib2.Request(url) data = urllib.urlencode(data) #enable cookie opener = urllib2.build_opener(urllib
-
python分析网页上所有超链接的方法
本文实例讲述了python分析网页上所有超链接的方法.分享给大家供大家参考.具体实现方法如下: import urllib, htmllib, formatter website = urllib.urlopen("http://yourweb.com") data = website.read() website.close() format = formatter.AbstractFormatter(formatter.NullWriter()) ptext = htmllib.H
-
python使用post提交数据到远程url的方法
本文实例讲述了python使用post提交数据到远程url的方法.分享给大家供大家参考.具体如下: import sys, urllib2, urllib zipcode = "S2S 1R8" url = 'http://www.yoursiteweb.com/getForecast' data = urllib.urlencode([('query', zipcode)]) req = urllib2.Request(url) fd = urllib2.urlopen(req, d
-
Python 分析Nginx访问日志并保存到MySQL数据库实例
使用Python 分析Nginx access 日志,根据Nginx日志格式进行分割并存入MySQL数据库.一.Nginx access日志格式如下: 复制代码 代码如下: $remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_f
-
python执行get提交的方法
本文实例讲述了python执行get提交的方法.分享给大家供大家参考.具体如下: import sys, urllib2, urllib def addGETdata(url, data): """Adds data to url. Data should be a list or tuple consisting of 2-item lists or tuples of the form: (key, value). Items that have no key shoul
-
使用python分析统计自己微信朋友的信息
首先,你得安装itchat,命令为pip install itchat,其余的较为简单,我不再说明,直接看注释吧. 以下的代码我在Win7+Python3.7里面调试通过 __author__ = 'Yue Qingxuan' # -*- coding: utf-8 -*- import itchat # hotReload=True可不用每次都去扫描二维码,只需要手机上确认下 itchat.auto_login(hotReload=True) # 获取好友列表 friends = itchat
-
Python使用requests提交HTTP表单的方法
Python的requests库, 其口号是HTTP for humans,堪称最好用的HTTP库. 使用requests库,可以使用数行代码实现自动化的http操作.以http post,即浏览器提交一个表格数据到web服务器,为例,来说明requests的使用. 无cookie import requests url = 'www.test.org' data = {'username': 'user', 'password': '123456'} response = requests.p