python实现SOM算法
算法简介
SOM网络是一种竞争学习型的无监督神经网络,将高维空间中相似的样本点映射到网络输出层中的邻近神经元。
训练过程简述:在接收到训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元。然后最佳匹配单元及其邻近的神经元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小。这个过程不断迭代,直至收敛。
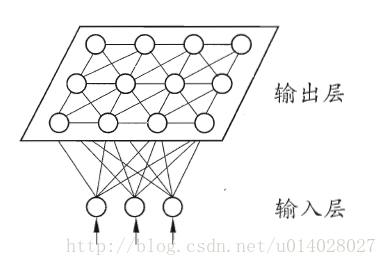
- 网络结构:输入层和输出层(或竞争层),如下图所示。
- 输入层:假设一个输入样本为X=[x1,x2,x3,…,xn],是一个n维向量,则输入层神经元个数为n个。
- 输出层(竞争层):通常输出层的神经元以矩阵方式排列在二维空间中,每个神经元都有一个权值向量。
- 假设输出层有m个神经元,则有m个权值向量,Wi = [wi1,wi2,....,win], 1<=i<=m。
算法流程:
1. 初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X' = X/||X||
ω'i= ωi/||ωi||, 1<=i<=m
||X||和||ωi||分别为输入的样本向量和权值向量的欧几里得范数。
2.将样本输入网络:样本与权值向量做点积,点积值最大的输出神经元赢得竞争,
(或者计算样本与权值向量的欧几里得距离,距离最小的神经元赢得竞争)记为获胜神经元。
3.更新权值:对获胜的神经元拓扑邻域内的神经元进行更新,并对学习后的权值重新归一化。
ω(t+1)= ω(t)+ η(t,n) * (x-ω(t))
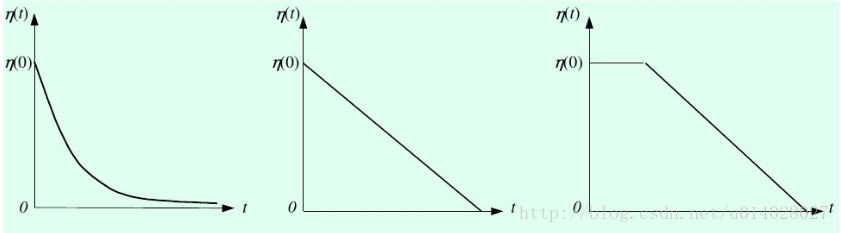
η(t,n):η为学习率是关于训练时间t和与获胜神经元的拓扑距离n的函数。
η(t,n)=η(t)e^(-n)
η(t)的几种函数图像如下图所示。
4.更新学习速率η及拓扑邻域N,N随时间增大距离变小,如下图所示。
5.判断是否收敛。如果学习率η<=ηmin或达到预设的迭代次数,结束算法。

python代码实现SOM
import numpy as np
import pylab as pl
class SOM(object):
def __init__(self, X, output, iteration, batch_size):
"""
:param X: 形状是N*D, 输入样本有N个,每个D维
:param output: (n,m)一个元组,为输出层的形状是一个n*m的二维矩阵
:param iteration:迭代次数
:param batch_size:每次迭代时的样本数量
初始化一个权值矩阵,形状为D*(n*m),即有n*m权值向量,每个D维
"""
self.X = X
self.output = output
self.iteration = iteration
self.batch_size = batch_size
self.W = np.random.rand(X.shape[1], output[0] * output[1])
print (self.W.shape)
def GetN(self, t):
"""
:param t:时间t, 这里用迭代次数来表示时间
:return: 返回一个整数,表示拓扑距离,时间越大,拓扑邻域越小
"""
a = min(self.output)
return int(a-float(a)*t/self.iteration)
def Geteta(self, t, n):
"""
:param t: 时间t, 这里用迭代次数来表示时间
:param n: 拓扑距离
:return: 返回学习率,
"""
return np.power(np.e, -n)/(t+2)
def updata_W(self, X, t, winner):
N = self.GetN(t)
for x, i in enumerate(winner):
to_update = self.getneighbor(i[0], N)
for j in range(N+1):
e = self.Geteta(t, j)
for w in to_update[j]:
self.W[:, w] = np.add(self.W[:,w], e*(X[x,:] - self.W[:,w]))
def getneighbor(self, index, N):
"""
:param index:获胜神经元的下标
:param N: 邻域半径
:return ans: 返回一个集合列表,分别是不同邻域半径内需要更新的神经元坐标
"""
a, b = self.output
length = a*b
def distence(index1, index2):
i1_a, i1_b = index1 // a, index1 % b
i2_a, i2_b = index2 // a, index2 % b
return np.abs(i1_a - i2_a), np.abs(i1_b - i2_b)
ans = [set() for i in range(N+1)]
for i in range(length):
dist_a, dist_b = distence(i, index)
if dist_a <= N and dist_b <= N: ans[max(dist_a, dist_b)].add(i)
return ans
def train(self):
"""
train_Y:训练样本与形状为batch_size*(n*m)
winner:一个一维向量,batch_size个获胜神经元的下标
:return:返回值是调整后的W
"""
count = 0
while self.iteration > count:
train_X = self.X[np.random.choice(self.X.shape[0], self.batch_size)]
normal_W(self.W)
normal_X(train_X)
train_Y = train_X.dot(self.W)
winner = np.argmax(train_Y, axis=1).tolist()
self.updata_W(train_X, count, winner)
count += 1
return self.W
def train_result(self):
normal_X(self.X)
train_Y = self.X.dot(self.W)
winner = np.argmax(train_Y, axis=1).tolist()
print (winner)
return winner
def normal_X(X):
"""
:param X:二维矩阵,N*D,N个D维的数据
:return: 将X归一化的结果
"""
N, D = X.shape
for i in range(N):
temp = np.sum(np.multiply(X[i], X[i]))
X[i] /= np.sqrt(temp)
return X
def normal_W(W):
"""
:param W:二维矩阵,D*(n*m),D个n*m维的数据
:return: 将W归一化的结果
"""
for i in range(W.shape[1]):
temp = np.sum(np.multiply(W[:,i], W[:,i]))
W[:, i] /= np.sqrt(temp)
return W
#画图
def draw(C):
colValue = ['r', 'y', 'g', 'b', 'c', 'k', 'm']
for i in range(len(C)):
coo_X = [] #x坐标列表
coo_Y = [] #y坐标列表
for j in range(len(C[i])):
coo_X.append(C[i][j][0])
coo_Y.append(C[i][j][1])
pl.scatter(coo_X, coo_Y, marker='x', color=colValue[i%len(colValue)], label=i)
pl.legend(loc='upper right')
pl.show()
#数据集:每三个是一组分别是西瓜的编号,密度,含糖量
data = """
1,0.697,0.46,2,0.774,0.376,3,0.634,0.264,4,0.608,0.318,5,0.556,0.215,
6,0.403,0.237,7,0.481,0.149,8,0.437,0.211,9,0.666,0.091,10,0.243,0.267,
11,0.245,0.057,12,0.343,0.099,13,0.639,0.161,14,0.657,0.198,15,0.36,0.37,
16,0.593,0.042,17,0.719,0.103,18,0.359,0.188,19,0.339,0.241,20,0.282,0.257,
21,0.748,0.232,22,0.714,0.346,23,0.483,0.312,24,0.478,0.437,25,0.525,0.369,
26,0.751,0.489,27,0.532,0.472,28,0.473,0.376,29,0.725,0.445,30,0.446,0.459"""
a = data.split(',')
dataset = np.mat([[float(a[i]), float(a[i+1])] for i in range(1, len(a)-1, 3)])
dataset_old = dataset.copy()
som = SOM(dataset, (5, 5), 1, 30)
som.train()
res = som.train_result()
classify = {}
for i, win in enumerate(res):
if not classify.get(win[0]):
classify.setdefault(win[0], [i])
else:
classify[win[0]].append(i)
C = []#未归一化的数据分类结果
D = []#归一化的数据分类结果
for i in classify.values():
C.append(dataset_old[i].tolist())
D.append(dataset[i].tolist())
draw(C)
draw(D)
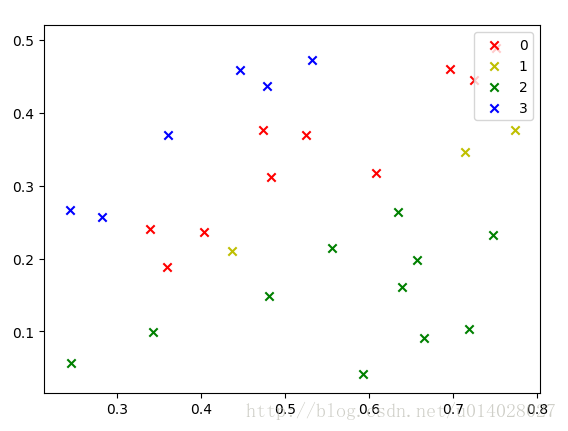
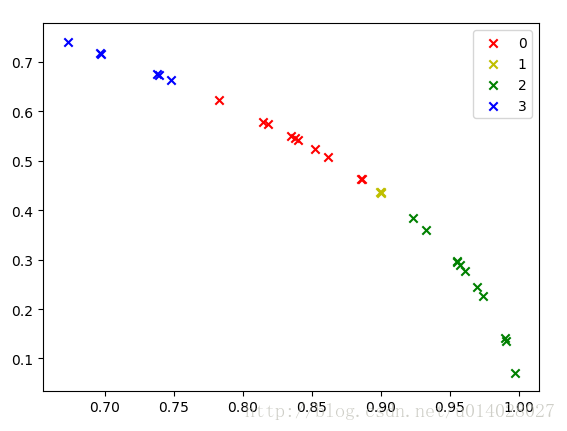
由于数据比较少,就直接用的训练集做测试了,运行结果图如下,分别是对未归一化的数据和归一化的数据进行的展示。
参考内容:
1.《机器学习》周志华
2.自组织竞争神经网络SOM
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python实现k-means聚类算法
- Python实现Kmeans聚类算法
- python实现聚类算法原理
- K-means聚类算法介绍与利用python实现的代码示例
- python中实现k-means聚类算法详解
- Python聚类算法之DBSACN实例分析
- Python聚类算法之凝聚层次聚类实例分析
- Python聚类算法之基本K均值实例详解
- python实现k均值算法示例(k均值聚类算法)
相关推荐
-

python实现聚类算法原理
本文主要内容: 聚类算法的特点 聚类算法样本间的属性(包括,有序属性.无序属性)度量标准 聚类的常见算法,原型聚类(主要论述K均值聚类),层次聚类.密度聚类 K均值聚类算法的python实现,以及聚类算法与EM最大算法的关系 参考引用 先上一张gif的k均值聚类算法动态图片,让大家对算法有个感性认识: 其中:N=200代表有200个样本,不同的颜色代表不同的簇(其中 3种颜色为3个簇),星星代表每个簇的簇心.算法通过25次迭代找到收敛的簇心,以及对应的簇. 每次迭代的过程中,簇心和对应的簇都在变
-
Python聚类算法之DBSACN实例分析
本文实例讲述了Python聚类算法之DBSACN.分享给大家供大家参考,具体如下: DBSCAN:是一种简单的,基于密度的聚类算法.本次实现中,DBSCAN使用了基于中心的方法.在基于中心的方法中,每个数据点的密度通过对以该点为中心以边长为2*EPs的网格(邻域)内的其他数据点的个数来度量.根据数据点的密度分为三类点: 核心点:该点在邻域内的密度超过给定的阀值MinPs. 边界点:该点不是核心点,但是其邻域内包含至少一个核心点. 噪音点:不是核心点,也不是边界点. 有了以上对数据点的划分,聚合可
-
K-means聚类算法介绍与利用python实现的代码示例
聚类 今天说K-means聚类算法,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别. 分类其实是从特定的数据中挖掘模式,作出判断的过程.比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选"垃圾"或"不是垃圾",过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了.这是因为在点选的过程中,其实是给每一条邮件打了一个"标签&qu
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
python实现k均值算法示例(k均值聚类算法)
简单实现平面的点K均值分析,使用欧几里得距离,并用pylab展示. 复制代码 代码如下: import pylab as pl #calc Euclid squiredef calc_e_squire(a, b): return (a[0]- b[0]) ** 2 + (a[1] - b[1]) **2 #init the 20 pointa = [2,4,3,6,7,8,2,3,5,6,12,10,15,16,11,10,19,17,16,13]b = [5,6,1,4,2,4,3,1,
-
Python聚类算法之基本K均值实例详解
本文实例讲述了Python聚类算法之基本K均值运算技巧.分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所期望的簇的个数.每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个.然后,根据指派到簇的点,更新每个簇的质心.重复指派和更新操作,直到质心不发生明显的变化. # scoding=utf-8 import pylab as pl points = [[int(eachpoint.split("#")[0]), in
-
python实现k-means聚类算法
k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法. 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重新计算已经得到的各个类的质心 4)迭代步骤(2).(3)直至新的质心与原质心相等或迭代次数大于指定阈值,算法结束 算法实现 随机初始化k个质心,用dict保存质心的值以及被聚类到该簇中的所有data. def initCent(dataSe
-
python实现SOM算法
算法简介 SOM网络是一种竞争学习型的无监督神经网络,将高维空间中相似的样本点映射到网络输出层中的邻近神经元. 训练过程简述:在接收到训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元.然后最佳匹配单元及其邻近的神经元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小.这个过程不断迭代,直至收敛. 网络结构:输入层和输出层(或竞争层),如下图所示. 输入层:假设一个输入样本为X=[x1,x2,x3,-,xn],是一个n维
-
python快速查找算法应用实例
本文实例讲述了Python快速查找算法的应用,分享给大家供大家参考. 具体实现方法如下: import random def partition(list_object,start,end): random_choice = start #random.choice(range(start,end+1)) #把这里的start改成random()效率会更高些 x = list_object[random_choice] i = start j = end while True: while li
-
Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简
-
Python基于分水岭算法解决走迷宫游戏示例
本文实例讲述了Python基于分水岭算法解决走迷宫游戏.分享给大家供大家参考,具体如下: #Solving maze with morphological transformation """ usage:Solving maze with morphological transformation needed module:cv2/numpy/sys ref: 1.http://www.mazegenerator.net/ 2.http://blog.leanote.com
-
python二分查找算法的递归实现方法
本文实例讲述了python二分查找算法的递归实现方法.分享给大家供大家参考,具体如下: 这里先提供一段二分查找的代码: def binarySearch(alist, item): first = 0 last = len(alist)-1 found = False while first<=last and not found: midpoint = (first + last)//2 if alist[midpoint] == item: found = True else: if ite
-
python通过BF算法实现关键词匹配的方法
本文实例讲述了python通过BF算法实现关键词匹配的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: #!/usr/bin/python # -*- coding: UTF-8 # filename BF import time """ t="this is a big apple,this is a big apple,this is a big apple,this is a big apple." p="apple&q
-
python选择排序算法实例总结
本文实例总结了python选择排序算法.分享给大家供大家参考.具体如下: 代码1: def ssort(V): #V is the list to be sorted j = 0 #j is the "current" ordered position, starting with the first one in the list while j != len(V): #this is the replacing that ends when it reaches the end o
-
python 换位密码算法的实例详解
python 换位密码算法的实例详解 一前言: 换位密码基本原理:先把明文按照固定长度进行分组,然后对每一组的字符进行换位操作,从而实现加密.例如,字符串"Error should never pass silently",使用秘钥1432进行加密时,首先将字符串分成若干长度为4的分组,然后对每个分组的字符进行换位,第1个和第3个字符位置不变,把第2个字符和第4个字符交换位置,得到"Eorrrs shluoden v repssa liseltny" 二 代码:
-
使用python实现rsa算法代码
RSA算法是一种非对称加密算法,是现在广泛使用的公钥加密算法,主要应用是加密信息和数字签名. 维基百科给出的RSA算法简介如下: 假设Alice想要通过一个不可靠的媒体接收Bob的一条私人讯息.她可以用以下的方式来产生一个公钥和一个私钥: 随意选择两个大的质数p和q,p不等于q,计算N=pq. 根据欧拉函数,不大于N且与N互质的整数个数为(p-1)(q-1) 选择一个整数e与(p-1)(q-1)互质,并且e小于(p-1)(q-1) 用以下这个公式计算d:d × e ≡ 1 (mod (p-1)(
-
Python基于DES算法加密解密实例
本文实例讲述了Python基于DES算法加密解密实现方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 from functools import partial import base64 class DES(object): """ DES加密算法 interface: input_key(s, base=10), encode(s), decode(s) """ __ip = [ 58,50,42,34,26,18,