python处理两种分隔符的数据集方法
在做机器学习的时候,遇到这样一个数据集...
一共399行10列,
1-9列是用不定长度的空格分割,
第9-10列之间用'\t'分割,
前九列都是数值类型,其中第三列有若干个'?'填充的缺失值...
第十列是字符串类型,..
部分数据截图:

之前我是用python强写的...很麻烦,代码如下:
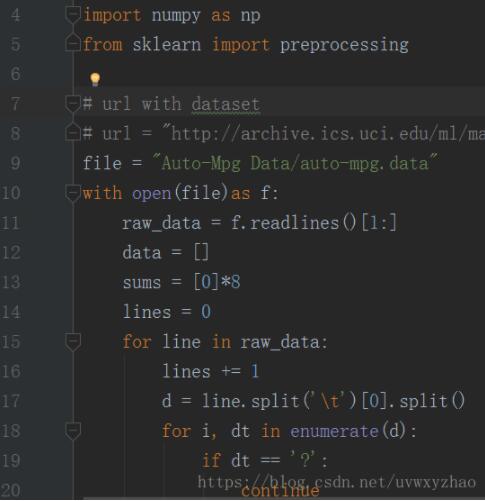
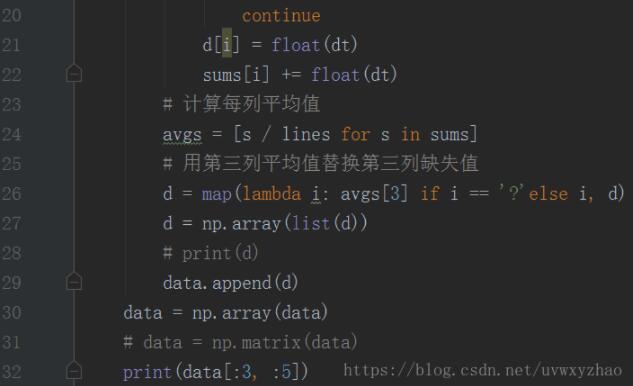
至此,可以已平均值,填充缺失值...
今天再回顾此数据库;决定用pandas库来试试;
1,导包,用pandas.read_table导入数据集,
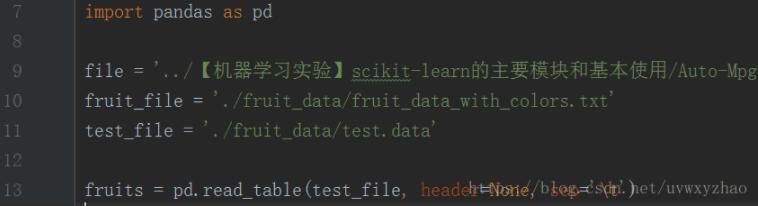
2,数据处理
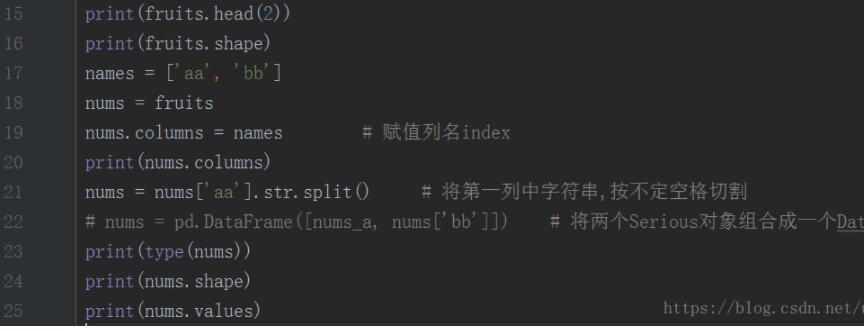
最后输出如下:
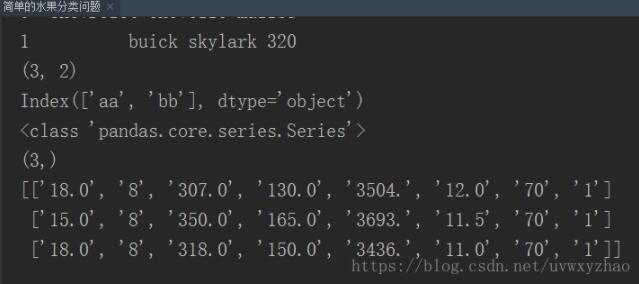
以上这篇python处理两种分隔符的数据集方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python数据集切分实例
在处理数据过程中经常要把数据集切分为训练集和测试集,因此记录一下切分代码. ''' data:数据集 test_ratio:测试机占比 如果data为numpy.numpy.ndarray直接使用此代码 如果data为pandas.DatFrame类型则 return data[train_indices],data[test_indices] 修改为 return data.iloc[train_indices],data.iloc[test_indices] ''' def split_tr
-
python merge、concat合并数据集的实例讲解
数据规整化:合并.清理.过滤 pandas和python标准库提供了一整套高级.灵活的.高效的核心函数和算法将数据规整化为你想要的形式! 本篇博客主要介绍: 合并数据集:.merge()..concat()等方法,类似于SQL或其他关系型数据库的连接操作. 合并数据集 1) merge 函数参数 参数 说明 left 参与合并的左侧DataFrame right 参与合并的右侧DataFrame how 连接方式:'inner'(默认):还有,'outer'.'left'.'right' on
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
python 实现对数据集的归一化的方法(0-1之间)
多数情况下,需要对数据集进行归一化处理,再对数据进行分析 #首先,引入两个库 ,numpy,sklearn from sklearn.preprocessing import MinMaxScaler import numpy as np #将csv文件导入矩阵当中 my_matrix = np.loadtxt(open("xxxx.csv"),delimiter=",",skiprows=0) #将数据集进行归一化处理 scaler = MinMaxScaler(
-
对python制作自己的数据集实例讲解
一.数据集介绍 点击打开链接17_Category_Flower 是一个不同种类鲜花的图像数据,包含 17 不同种类的鲜花,每类 80 张该类鲜花的图片,鲜花种类是英国地区常见鲜花.下载数据后解压文件,然后将不同的花剪切到对应的文件夹,如下图所示: 每个文件夹下面有80个图片文件. 二.使用的工具 首先是在tensorflow框架下,然后介绍一下用到的两个库,一个是os,一个是PIL.PIL(Python Imaging Library)是 Python 中最常用的图像处理库,而Image类又是
-
python 划分数据集为训练集和测试集的方法
sklearn的cross_validation包中含有将数据集按照一定的比例,随机划分为训练集和测试集的函数train_test_split from sklearn.cross_validation import train_test_split #x为数据集的feature熟悉,y为label. x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3) 得到的x_train,y_train(x_te
-
Python读取数据集并消除数据中的空行方法
如下所示: # -*- coding: utf-8 -*- # @ author hulei 2016-5-3 from numpy import * import operator from os import listdir import sys reload(sys) sys.setdefaultencoding('utf8') # x,y=getDataSet_dz('iris.data.txt',4) def getDataSet(filename,numberOfFeature):
-
对python中数据集划分函数StratifiedShuffleSplit的使用详解
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数 1.交叉验证(Cross-validation) 交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和.这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型. 下图所示 2.StratifiedShuffleSplit函数的使用 官方文档 用法: from sklearn.
-
python 筛选数据集中列中value长度大于20的数据集方法
如果我有一个数据集,他的某个列名下面的value很长,我们需要筛选出,所有列名中value值字符串大于20的数据集. 其实比较简单啦,一句代码就可以搞定 #对该列进行强制的字符类型转换 df["token"] = df["token"].astype(str) #筛选df这个数据集下,token这个字段下面的value字符串长度大于20的 df= df[df['token'].str.len() >20] 以上这篇python 筛选数据集中列中value长度大
-
python处理两种分隔符的数据集方法
在做机器学习的时候,遇到这样一个数据集... 一共399行10列, 1-9列是用不定长度的空格分割, 第9-10列之间用'\t'分割, 前九列都是数值类型,其中第三列有若干个'?'填充的缺失值... 第十列是字符串类型,.. 部分数据截图: 之前我是用python强写的...很麻烦,代码如下: 至此,可以已平均值,填充缺失值... 今天再回顾此数据库;决定用pandas库来试试; 1,导包,用pandas.read_table导入数据集, 2,数据处理 最后输出如下: 以上这篇python处理两
-
Python sklearn KFold 生成交叉验证数据集的方法
源起: 1.我要做交叉验证,需要每个训练集和测试集都保持相同的样本分布比例,直接用sklearn提供的KFold并不能满足这个需求. 2.将生成的交叉验证数据集保存成CSV文件,而不是直接用sklearn训练分类模型. 3.在编码过程中有一的误区需要注意: 这个sklearn官方给出的文档 >>> import numpy as np >>> from sklearn.model_selection import KFold >>> X = [&quo
随机推荐
- AngularJS国际化详解及示例代码
- AngularJS基础 ng-cloak 指令简单示例
- swift实现自动轮播图效果(UIScrollView+UIPageControl+Timer)
- Linux/Unix下安装Perl模块的两种方法分享
- vbscript和javascript版的15位, 18位的身份证号码的验证函数.以及根据身份证取省份,生日,性别
- 详解Java的Struts框架中栈值和OGNL的使用
- js实现楼层导航功能
- Bootstrap风格的zTree右键菜单
- ES6使用Set数据结构实现数组的交集、并集、差集功能示例
- yii2.0实现验证用户名与邮箱功能
- PHP 程序员也要学会使用“异常”
- Jquery简单分页实现方法
- apache ab工具页面压力测试返回结果含义解释
- CentOS 7.3上SQL Server vNext CTP 1.2安装教程
- jQuery实现宽屏图片轮播实例教程
- URL编码转换,escape() encodeURI() encodeURIComponent()
- Android下修改SeekBar样式的解决办法
- iOS App引导页开发教程
- Android可自定义神奇动效的卡片切换视图实例
- Python使用os.listdir()和os.walk()获取文件路径与文件下所有目录的方法