python提取包含关键字的整行数据方法
问题描述:
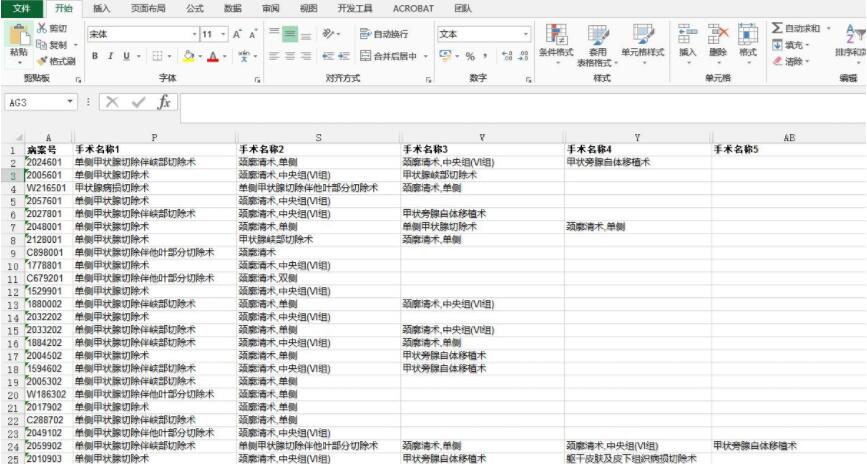
如下图所示,有一个近2000行的数据表,需要把其中含有关键字‘颈廓清术,中央组(VI组)'的数据所在行都都给抽取出来,且提取后的表格不能改变原先的顺序。
问题分析:
一开始想用excel的筛选功能,但是发现只提供单列筛选,由于关键词在P,S,V,Y,AB列都有,故需要筛选5次。但是筛选完后再整合再一起的表格顺序就乱了,而原先的表格排序规律不可知,无法通过简单的排序实现。于是决定用Python写个代码来解决这个问题~
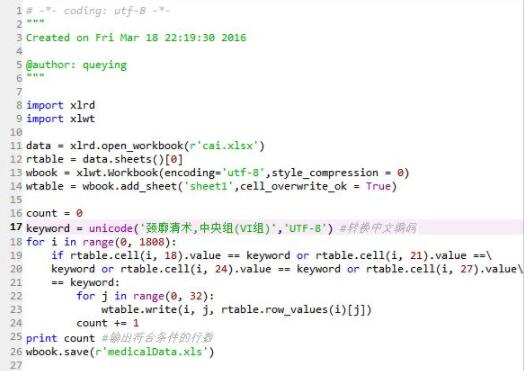
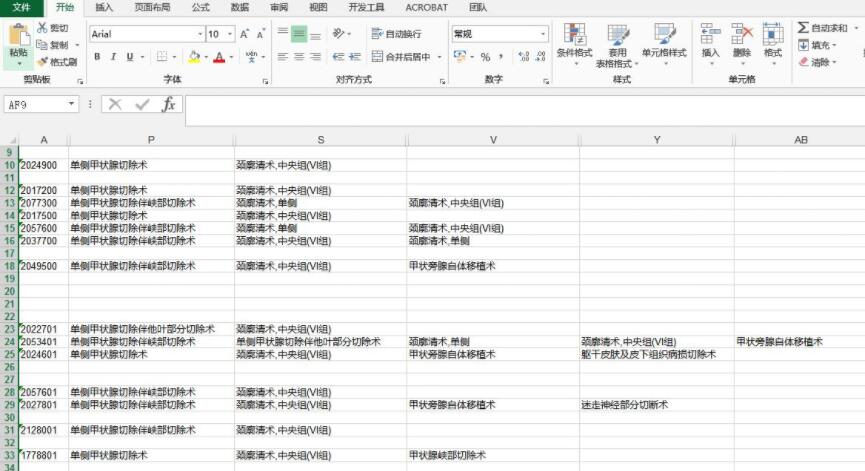
python生成的表格是这个样子滴^_^那些空白的行就是不符合要求的,我们还需要把这些空白的行给删掉~
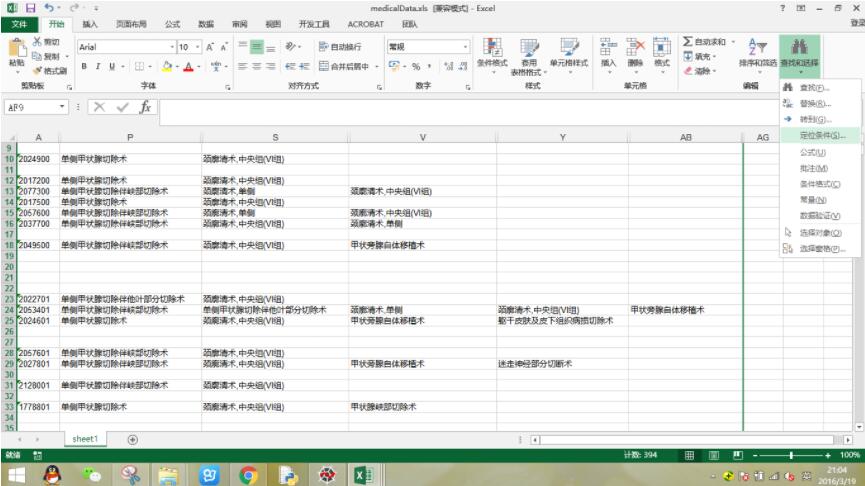
方法很简单,使用excel的定位条件->空值->将所选行删除掉:
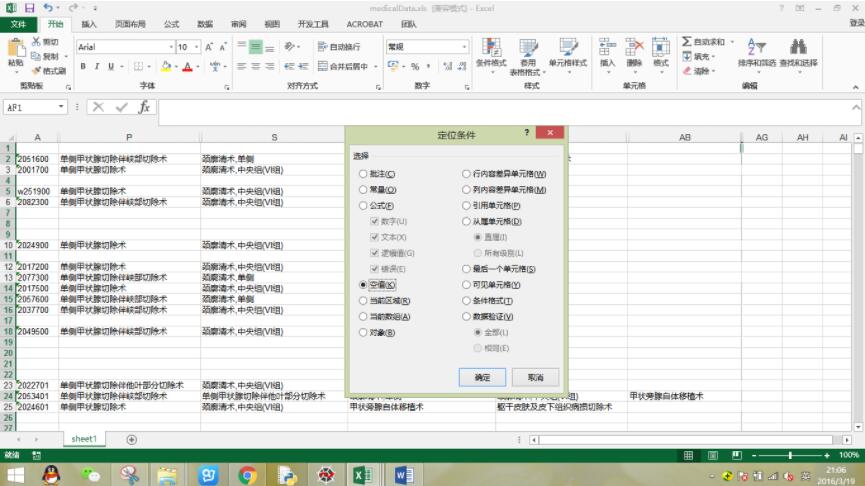
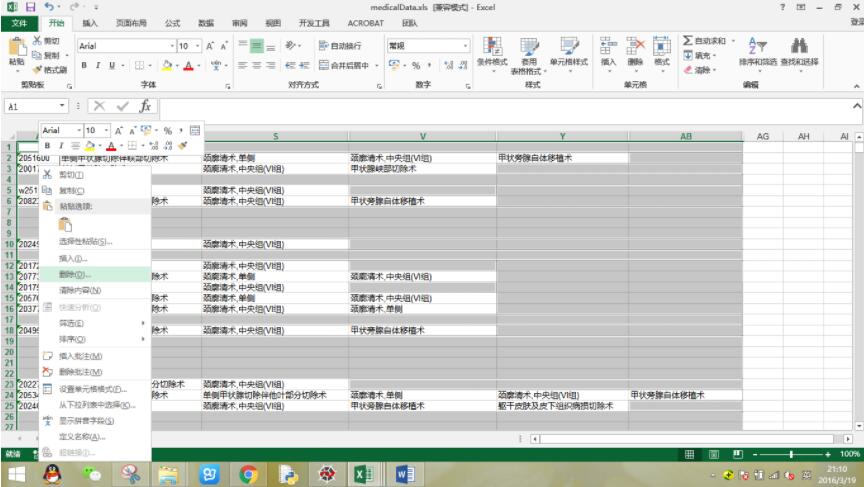
以上这篇python提取包含关键字的整行数据方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python进行数据提取的方法总结
准备工作 首先是准备工作,导入需要使用的库,读取并创建数据表取名为loandata. import numpy as np import pandas as pd loandata=pd.DataFrame(pd.read_excel('loan_data.xlsx')) 设置索引字段 在开始提取数据前,先将member_id列设置为索引字段.然后开始提取数据. Loandata = loandata.set_index('member_id') 按行提取信息 第一步是按行提取数据,例如提取某个
-
python实现关键词提取的示例讲解
新人小菜鸟又来写博客啦!!!没人表示不开心~~(>_<)~~ 今天我来弄一个简单的关键词提取的代码 文章内容关键词的提取分为三大步: (1) 分词 (2) 去停用词 (3) 关键词提取 分词方法有很多,我这里就选择常用的结巴jieba分词:去停用词,我用了一个停用词表. 具体代码如下: import jieba import jieba.analyse #第一步:分词,这里使用结巴分词全模式 text = '''新闻,也叫消息,是指报纸.电台.电视台.互联网经常使用的记录社会.传播信息.反映时
-
python 读取文本文件的行数据,文件.splitlines()的方法
一般跟踪训练的ground_truth的数据保存在文本文文件中,故每一行的数据为一张图片的标签数据,这个时候读取每一张图片的标签,具体实现如下: test_txt = '/home/zcm/tensorf/siamfc-tf-master/data/Biker/groundtruth.txt' def load_label_set(label_dir): label_folder = open(label_dir, "r") trainlines = label_folder.read
-
python提取内容关键词的方法
本文实例讲述了python提取内容关键词的方法.分享给大家供大家参考.具体分析如下: 一个非常高效的提取内容关键词的python代码,这段代码只能用于英文文章内容,中文因为要分词,这段代码就无能为力了,不过要加上分词功能,效果和英文是一样的. 复制代码 代码如下: # coding=UTF-8 import nltk from nltk.corpus import brown # This is a fast and simple noun phrase extractor (based on
-
python多进程提取处理大量文本的关键词方法
经常需要通过python代码来提取文本的关键词,用于文本分析.而实际应用中文本量又是大量的数据,如果使用单进程的话,效率会比较低,因此可以考虑使用多进程. python的多进程只需要使用multiprocessing的模块就行,如果使用大量的进程就可以使用multiprocessing的进程池--Pool,然后不同进程处理时使用apply_async函数进行异步处理即可. 实验测试语料:message.txt中存放的581行文本,一共7M的数据,每行提取100个关键词. 代码如下: #codin
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-
python提取包含关键字的整行数据方法
问题描述: 如下图所示,有一个近2000行的数据表,需要把其中含有关键字'颈廓清术,中央组(VI组)'的数据所在行都都给抽取出来,且提取后的表格不能改变原先的顺序. 问题分析: 一开始想用excel的筛选功能,但是发现只提供单列筛选,由于关键词在P,S,V,Y,AB列都有,故需要筛选5次.但是筛选完后再整合再一起的表格顺序就乱了,而原先的表格排序规律不可知,无法通过简单的排序实现.于是决定用Python写个代码来解决这个问题~ python生成的表格是这个样子滴^_^那些空白的行就是不符合要求的
-
Python实现提取Excel指定关键词的行数据
目录 一.需求描述 1.图片展示 2.提取方法 二.python提取第二版 1.图片展示 2.提取方法 一.需求描述 1.图片展示 从如图所示的数据中提取含有"python"."ubuntu"关键词的所有行数据,其它的不提取: 备注: 关键词和数据行列数可自定义!!! 提取前: 提取后: 2.提取方法 代码如下(示例): import xlrd import xlwt data = xlrd.open_workbook(r'shuju.xlsx') rtable =
-
python提取具有某种特定字符串的行数据方法
今天又帮女朋友处理了一下,她的实验数据,因为python是一年前经常用,最近找工作,用的是c,c++,python的有些东西忘记了,然后就一直催我,说我弄的慢,弄的慢,你自己弄啊,烦不烦啊,逼逼叨叨的,最后还不是我给弄好的?呵呵 好的,数据是这样的,我截个图 我用红括号括起来的,就是我所要提取的数据 其中lossstotal.txt是我要提取的原始数据,考虑两种方法去提取,前期以为所要提取行的数据是有一定规律的,后来发现,并不是,所以,我考虑用正则来提取,经过思考以后,完成了数据的提取,如下午所
-
JS获得选取checkbox整行数据的方法
本文实例讲述了JS获得选取checkbox整行数据的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>js</title> </head> <script language="java
-
Python argparse模块实现解析命令行参数方法详解
argparse是Python的一个标准模块,用于解析命令行参数,即解析sys.argv中定义的参数.实现在:传送门 argparse模块还会自动生成帮助和使用信息,即在最后加-h或--help.当用户输入的参数无效时,会触发error,并给出出错原因. python test_argparse.py -h python test_argparse.py --help 使用argparse的步骤: 1.创建解析器:argparse.ArgumentParser(),ArgumentParser是
-
Python实现读取文件最后n行的方法
本文实例讲述了Python实现读取文件最后n行的方法.分享给大家供大家参考,具体如下: # -*- coding:utf8-*- import os import time import datetime import math import string def get_last_line(inputfile) : filesize = os.path.getsize(inputfile) blocksize = 1024 dat_file = open(inputfile, 'r') las
-
python使用openpyxl库修改excel表格数据方法
1.openpyxl库可以读写xlsx格式的文件,对于xls旧格式的文件只能用xlrd读,xlwt写来完成了. 简单封装类: from openpyxl import load_workbook from openpyxl import Workbook from openpyxl.chart import BarChart, Series, Reference, BarChart3D from openpyxl.styles import Color, Font, Alignment from
-
python 提取key 为中文的json 串方法
示例: # -*- coding:utf-8 -*- import json strtest = {"中故宫":"好地方","天涯":"北京"} print strtest #####{'\xe4\xb8\xad\xe6\x95\x85\xe5\xae\xab': '\xe5\xa5\xbd\xe5\x9c\xb0\xe6\x96\xb9', '\xe5\xa4\xa9\xe6\xb6\xaf': '\xe5\x8c\x97\
-
Python编写带选项的命令行程序方法
运行python程序时,有时需要在命令行传入一些参数.常见的方式是在执行时,在脚本名后直接追加空格分隔的参数列表(例如 python test.py arg0 arg1 arg2),然后在脚本中就可以通过sys.argv获取所有的命令行参数. 这种方式的优点是传参方便,参数获取简单:缺点是执行脚本时,必须知道参数的顺序,并且不能设置默认值,所有参数每次都必须传入. 还有一种命令行传参方式是通过带选项的方式进行传参(例如python test.py -p0=arg0 -p1=arg1). 这种方式
-
python更新数据库中某个字段的数据(方法详解)
连接数据库基本操作,我把每一步的操作是为什么给大家注释一下,老手自行快进. 请注意这是连接数据库操作,还不是更新. import pymysql #导包 #连接数据库 db = pymysql.connect(host='localhost', user='用户名', password='数据库密码', port=3306, db='你的数据库名字') #定义游标 cursor = db.cursor() #sql语句 sql = 'select * from students;' cursor