python机器学习之神经网络实现
神经网络在机器学习中有很大的应用,甚至涉及到方方面面。本文主要是简单介绍一下神经网络的基本理论概念和推算。同时也会介绍一下神经网络在数据分类方面的应用。
首先,当我们建立一个回归和分类模型的时候,无论是用最小二乘法(OLS)还是最大似然值(MLE)都用来使得残差达到最小。因此我们在建立模型的时候,都会有一个loss function。
而在神经网络里也不例外,也有个类似的loss function。
对回归而言:
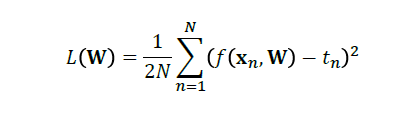
对分类而言:
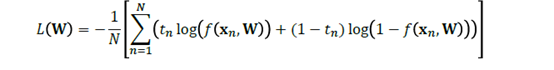
然后同样方法,对于W开始求导,求导为零就可以求出极值来。
关于式子中的W。我们在这里以三层的神经网络为例。先介绍一下神经网络的相关参数。
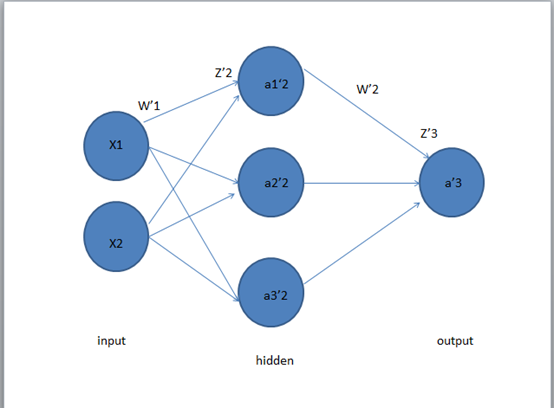
第一层是输入层,第二层是隐藏层,第三层是输出层。
在X1,X2经过W1的加权后,达到隐藏层,然后经过W2的加权,到达输出层
其中,
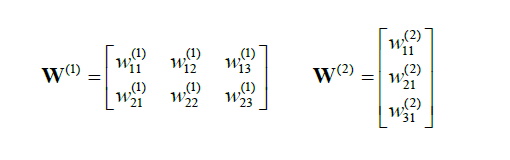
我们有:

至此,我们建立了一个初级的三层神经网络。
当我们要求其的loss function最小时,我们需要逆向来求,也就是所谓的backpropagation。
我们要分别对W1和W2进行求导,然后求出其极值。
从右手边开始逆推,首先对W2进行求导。
代入损失函数公式:
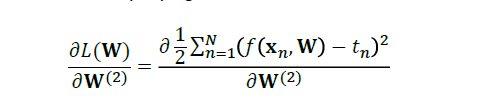

然后,我们进行化简:

化简到这里,我们同理再对W1进行求导。

我们可以发现当我们在做bp网络时候,有一个逆推回去的误差项,其决定了loss function 的最终大小。
在实际的运算当中,我们会用到梯度求解,来求出极值点。
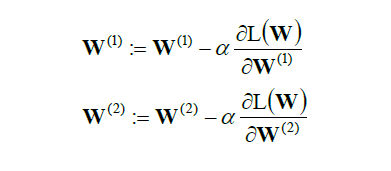
总结一下来说,我们使用向前推进来理顺神经网络做到回归分类等模型。而向后推进来计算他的损失函数,使得参数W有一个最优解。
当然,和线性回归等模型相类似的是,我们也可以加上正则化的项来对W参数进行约束,以免使得模型的偏差太小,而导致在测试集的表现不佳。

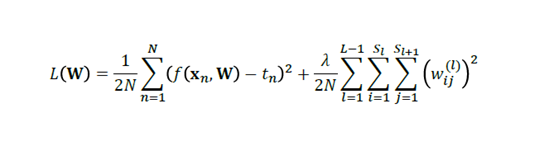
Python 的实现:
使用了KERAS的库
解决线性回归:
model.add(Dense(1, input_dim=n_features, activation='linear', use_bias=True))
# Use mean squared error for the loss metric and use the ADAM backprop algorithm
model.compile(loss='mean_squared_error', optimizer='adam')
# Train the network (learn the weights)
# We need to convert from DataFrame to NumpyArray
history = model.fit(X_train.values, y_train.values, epochs=100,
batch_size=1, verbose=2, validation_split=0)
解决多重分类问题:
# create model model = Sequential() model.add(Dense(64, activation='relu', input_dim=n_features)) model.add(Dropout(0.5)) model.add(Dense(64, activation='relu')) model.add(Dropout(0.5)) # Softmax output layer model.add(Dense(7, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X_train.values, y_train.values, epochs=20, batch_size=16) y_pred = model.predict(X_test.values) y_te = np.argmax(y_test.values, axis = 1) y_pr = np.argmax(y_pred, axis = 1) print(np.unique(y_pr)) print(classification_report(y_te, y_pr)) print(confusion_matrix(y_te, y_pr))
当我们选取最优参数时候,有很多种解决的途径。这里就介绍一种是gridsearchcv的方法,这是一种暴力检索的方法,遍历所有的设定参数来求得最优参数。
from sklearn.model_selection import GridSearchCV def create_model(optimizer='rmsprop'): model = Sequential() model.add(Dense(64, activation='relu', input_dim=n_features)) model.add(Dropout(0.5)) model.add(Dense(64, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(7, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy']) return model model = KerasClassifier(build_fn=create_model, verbose=0) optimizers = ['rmsprop'] epochs = [5, 10, 15] batches = [128] param_grid = dict(optimizer=optimizers, epochs=epochs, batch_size=batches, verbose=['2']) grid = GridSearchCV(estimator=model, param_grid=param_grid) grid.fit(X_train.values, y_train.values)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Tensorflow卷积神经网络实例进阶
在Tensorflow卷积神经网络实例这篇博客中,我们实现了一个简单的卷积神经网络,没有复杂的Trick.接下来,我们将使用CIFAR-10数据集进行训练. CIFAR-10是一个经典的数据集,包含60000张32*32的彩色图像,其中训练集50000张,测试集10000张.CIFAR-10如同其名字,一共标注为10类,每一类图片6000张. 本文实现了进阶的卷积神经网络来解决CIFAR-10分类问题,我们使用了一些新的技巧: 对weights进行了L2的正则化 对图片进行了翻转.随机剪切等数据
-
Tensorflow实现卷积神经网络的详细代码
本文实例为大家分享了Tensorflow实现卷积神经网络的具体代码,供大家参考,具体内容如下 1.概述 定义: 卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现.它包括卷积层(alternating convolutional layer)和池层(pooling layer). 卷积层(convolutional layer): 对输入数据应用若干过滤器,一个输入参数被
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
Tensorflow卷积神经网络实例
CNN最大的特点在于卷积的权值共享结构,可以大幅减少神经网络的参数量,防止过拟合的同时又降低了神经网络模型的复杂度.在CNN中,第一个卷积层会直接接受图像像素级的输入,每一个卷积操作只处理一小块图像,进行卷积变化后再传到后面的网络,每一层卷积都会提取数据中最有效的特征.这种方法可以提取到图像中最基础的特征,比如不同方向的边或者拐角,而后再进行组合和抽象形成更高阶的特征. 一般的卷积神经网络由多个卷积层构成,每个卷积层中通常会进行如下几个操作: 图像通过多个不同的卷积核的滤波,并加偏置(bias)
-
BP神经网络原理及Python实现代码
本文主要讲如何不依赖TenserFlow等高级API实现一个简单的神经网络来做分类,所有的代码都在下面:在构造的数据(通过程序构造)上做了验证,经过1个小时的训练分类的准确率可以达到97%. 完整的结构化代码见于:链接地址 先来说说原理 网络构造 上面是一个简单的三层网络:输入层包含节点X1 , X2:隐层包含H1,H2:输出层包含O1. 输入节点的数量要等于输入数据的变量数目. 隐层节点的数量通过经验来确定. 如果只是做分类,输出层一般一个节点就够了. 从输入到输出的过程 1.输入节点的输出等
-
PyTorch快速搭建神经网络及其保存提取方法详解
有时候我们训练了一个模型, 希望保存它下次直接使用,不需要下次再花时间去训练 ,本节我们来讲解一下PyTorch快速搭建神经网络及其保存提取方法详解 一.PyTorch快速搭建神经网络方法 先看实验代码: import torch import torch.nn.functional as F # 方法1,通过定义一个Net类来建立神经网络 class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output):
-
神经网络相关之基础概念的讲解
人工神经网络需要一定的数学基础,但是一般来说比较简单,简单的高数基础即可,这里整理了一些所需要的最基础的概念的理解,对于神经网络的入门,非常基础和重要,而且理解了之后,会发现介绍不需要在看,磨刀不误砍柴工,强烈建议理解清楚之后在去使用诸如tensorflow这样的利器. 自变量/因变量/函数 因为E文文档的阅读时不可避免的接触这些内容,一般将英文也列出来,尽量记住,阅读时会大大提高速度. 导数 作为高数最为基础的导数概念,这里不在赘述,简单烈一下内容能够大体理解即可, 借用一张图形来进行解释:
-
Python实现的NN神经网络算法完整示例
本文实例讲述了Python实现的NN神经网络算法.分享给大家供大家参考,具体如下: 参考自Github开源代码:https://github.com/dennybritz/nn-from-scratch 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) sklearn(人工智能包,生成数据使用) 计算过程 输入样例 none 代码实现 # -*- coding:utf-8 -*- #!python3 __author__ = 'Wsine' im
-
纯用NumPy实现神经网络的示例代码
摘要: 纯NumPy代码从头实现简单的神经网络. Keras.TensorFlow以及PyTorch都是高级别的深度学习框架,可用于快速构建复杂模型.前不久,我曾写过一篇文章,对神经网络是如何工作的进行了简单的讲解.该文章侧重于对神经网络中运用到的数学理论知识进行详解.本文将利用NumPy实现简单的神经网络,在实战中对其进行深层次剖析.最后,我们会利用分类问题对模型进行测试,并与Keras所构建的神经网络模型进行性能的比较. Note:源码可在我的GitHub中查看. 在正式开始之前,需要先对所
-
Tensorflow实现AlexNet卷积神经网络及运算时间评测
本文实例为大家分享了Tensorflow实现AlexNet卷积神经网络的具体实现代码,供大家参考,具体内容如下 之前已经介绍过了AlexNet的网络构建了,这次主要不是为了训练数据,而是为了对每个batch的前馈(Forward)和反馈(backward)的平均耗时进行计算.在设计网络的过程中,分类的结果很重要,但是运算速率也相当重要.尤其是在跟踪(Tracking)的任务中,如果使用的网络太深,那么也会导致实时性不好. from datetime import datetime import