基于python socketserver框架全面解析
socketserver框架是一个基本的socket服务器端框架, 使用了threading来处理多个客户端的连接, 使用seletor模块来处理高并发访问, 是值得一看的python 标准库的源码之一
对于select网络框架的理解可以看 << 基于python select.select模块通信的实例讲解 >>。socketserver框架采用了selector框架来供你选择相适应的网络通信框架, 比如select, poll, epoll等。有了这些网络框架我们就能处理高并发的网络访问了.
先看看示例代码吧:
# coding: utf-8
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
"""
The request handler class for our server.
It is instantiated once per connection to the server, and must
override the handle() method to implement communication to the
client.
"""
def handle(self):
# self.request is the TCP socket connected to the client
self.data = self.request.recv(1024).strip()
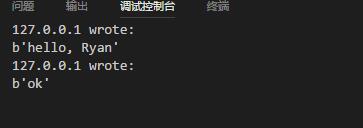
print("{} wrote:".format(self.client_address[0]))
print(self.data)
# just send back the same data, but upper-cased
self.request.sendall(self.data.upper())
if __name__ == "__main__":
HOST, PORT = "localhost", 9999
# Create the server, binding to localhost on port 9999
# 如果子类没有某个方法或是属性, 就回去父类中调用
with socketserver.ThreadingTCPServer((HOST, PORT), MyTCPHandler) as server:
# Activate the server; this will keep running until you
# interrupt the program with Ctrl-C
server.serve_forever()
客户端:
# coding: utf-8
import socket
sk = socket.socket()
sk.connect(("127.0.0.1", 9999)) # 主动初始化与服务器端的连接
while True:
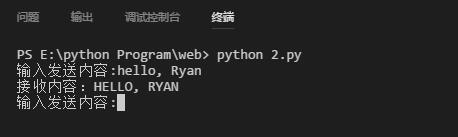
send_data = input("输入发送内容:")
sk.sendall(bytes(send_data, encoding="utf8"))
if send_data == "byebye":
break
accept_data = str(sk.recv(1024), encoding="utf8")
print("".join(("接收内容:", accept_data)))
sk.close()
我们创建一个继承自BaseRequestHandler类的TCP请求处理类, 说白了这个类就是我们自己封装的基于socket的recv()函数与send()函数的类, 而所谓的TCP请求处理类其实就是对socket服务器端的bind, listen, accept等处理的封装类, 而且这个封装的并不是简单的socket, 而是基于select或是epoll等网络框架的类, 我们调用这个类就能轻易地处理高并发的网络访问. 其实认真阅读源码, 你会发现整体的程序设计是基于事件驱动的, 事件驱动机制的三个要素: 消息(事件)队列, 消息(事件)触发, 事件循环。只不过socketserver框架的事件驱动机制就做到了socket的accept()方法那, 接下来的消息接受(recv)与发送(send)就没有在做封装成相应的事件来进行处理了。
在这里说一个要注意的地方, 我使用了ThreadingTCPServer()类响应多个客户端的连接, 但是当我阅读这个类的源码的时候, 表示很疑惑啊!
class ThreadingTCPServer(ThreadingMixIn, TCPServer): pass
这让我很疑惑啊,再看看调用:
with socketserver.ThreadingTCPServer((HOST, PORT), MyTCPHandler) as server: # Activate the server; this will keep running until you # interrupt the program with Ctrl-C server.serve_forever()
这更疑惑, ThreadingTCPServer哪来的构造函数, 后来研究了一下, 原来当子类的某个函数或是属性发生调用时, 如果不是重载了父类的方法或是属性, 而且子类中没有这个方法或是属性, 就会去调用父类相对应的方法或是属性, 于是上面的就是调用了TCPServer的初始化函数__init__以及serve_forever(), 随后调用的是子类的Request_handler函数
程序结果:
以上这篇基于python socketserver框架全面解析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现简单的socket server实例
本文实例讲述了python实现简单的socket server的方法.分享给大家供大家参考.具体如下: import socket host = '' port = 55555 myServerSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) myServerSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1) myServerSocket.bind((host,
-

python网络编程之TCP通信实例和socketserver框架使用例子
1.TCP是一种面向连接的可靠地协议,在一方发送数据之前,必须在双方之间建立一个连接,建立的过程需要经过三次握手,通信完成后要拆除连接,需要经过四次握手,这是由TCP的半关闭造成的,一方在完成数据发送后要发送一个FIN来终止这个方向的连接,一个TCP连接在收到一个FIN后仍能发送数据,但应用程序很少这么做,下面是TCP连接建立和拆除的过程: 2.python可以实现TCP服务器和客户端的编程,下面是代码: 服务器端: 复制代码 代码如下: #!/usr/bin/env pythonimport
-
实例讲解Python中SocketServer模块处理网络请求的用法
SocketServer创建一个网络服务框架.它定义了类来处理TCP,UDP, UNIX streams 和UNIX datagrams上的同步网络请求. 一.Server Types 有五个不同的服务器类在SocketServer中. 1.BaseServer定义了API, 而且他不是用来实例化和直接使用的. 2.TCPServer用作TCP/IP的socket通讯. 3.UDPServer使用datagram sockets. 4.UnixStreamServer和UnixDatagramS
-
Python使用SocketServer模块编写基本服务器程序的教程
SocketServer简化了网络服务器的编写.它有4个类:TCPServer,UDPServer,UnixStreamServer,UnixDatagramServer.这4个类是同步进行处理的,另外通过ForkingMixIn和ThreadingMixIn类来支持异步. 创建服务器的步骤.首先,你必须创建一个请求处理类,它是BaseRequestHandler的子类并重载其handle()方法.其次,你必须实例化一个服务器类,传入服务器的地址和请求处理程序类.最后,调用handle_requ
-
基于python socketserver框架全面解析
socketserver框架是一个基本的socket服务器端框架, 使用了threading来处理多个客户端的连接, 使用seletor模块来处理高并发访问, 是值得一看的python 标准库的源码之一 对于select网络框架的理解可以看 << 基于python select.select模块通信的实例讲解 >>.socketserver框架采用了selector框架来供你选择相适应的网络通信框架, 比如select, poll, epoll等.有了这些网络框架我们就能处理高并发
-
Python Django框架url反向解析实现动态生成对应的url链接示例
本文实例讲述了Python Django框架url反向解析实现动态生成对应的url链接.分享给大家供大家参考,具体如下: url反向解析:根据url路由规则,动态生成对应的url链接 (防止硬编码). url反向解析应用在两个地方:模板中的超链接,视图中的重定向. 项目名/urls.py(项目的url路由配置,url反向解析,取namespace名字): from django.conf.urls import include, url from django.contrib import ad
-
基于Python的接口自动化unittest测试框架和ddt数据驱动详解
引言 在编写接口自动化用例时,我们一般针对一个接口建立一个.py文件,一条接口测试用例封装为一个函数(方法),但是在批量执行的过程中,如果其中一条出错,后面的用例就无法执行,还有在运行大量的接口测试用例时测试数据如何管理和加载.针对测试用例加载以及执行控制,python语言提供了unittest单元测试框架,将测试用例编写在unittest框架下,使用该框架可以单个或者批量加载互不影响的用例执行及更灵活的执行控制,对于更好的进行测试数据的管理和加载,这里我们引入数据驱动的模块:ddt,测试数据和
-
基于Python的接口测试框架实例
背景 最近公司在做消息推送,那么自然就会产生很多接口,测试的过程中需要调用接口,我就突然觉得是不是可以自己写一个测试框架? 说干就干,由于现有的接口测试工具Jmeter.SoupUI等学习周期有点长,干脆自己写一个吧,不求人,所有功能自己都能一清二楚. 当然,写工具造轮子只是学习的一种方式,现成成熟的工具肯定比我们自己的写的好用. 开发环境 ------------------------------------------------------------- 操作系统:Mac OS X EI
-
基于Python函数和变量名解析
1.Python函数 函数是Python为了代码最大程度的重用和最小化代码冗余而提供的基本程序结构,用于将相关功能打包并参数化 Python中可以创建4种函数: 1).全局函数:定义在模块中,每个模块都是一个全局作用域,因此,全局作用域的范围仅限于单个程序文 2).局部函数:嵌套在其它函数中 3).lambda函数:表达式 4).方法:与特定数据类型关联的函数表,并且只能与数据类型关联一起使用 Python提供众多内置函数 Python创建.改变.查找变量名都是在名称空间中进行,在代码中变量名被
-
基于Python列表解析(列表推导式)
列表解析--用来动态地创建列表 [expr for iter_var in iterable if cond_expr] 例子一: map(lambda x: x**2, range(6)) [0, 1, 4, 9, 16, 25] [x**2 for x in range(6)] [0, 1, 4, 9, 16, 25] 列表解析式可以取代内建的map()函数以及lambda,而且++效率更高++. 例子二: seq = [11, 10, 9, 8, 7, 6] filter(lambda x
-
基于Python实现ComicReaper漫画自动爬取脚本过程解析
这篇文章主要介绍了基于Python实现ComicReaper漫画自动爬取脚本过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 讲真的, 手机看漫画翻页总是会手残碰到页面上的广告好吧... 要是能只需要指定一本漫画的主页URL就能给我返回整本漫画就好了... 这促使我产生了使用Python 3来实现, 做一个 ComicReaper(漫画收割者) 的想法! 本文所用漫画链接 : http://www.manhuadb.com/manhua/
-
基于python调用psutil模块过程解析
这篇文章主要介绍了基于python调用psutils模块过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 用Python来编写脚本简化日常的运维工作是Python的一个重要用途.在Linux下,有许多系统命令可以让我们时刻监控系统运行的状态,如ps,top,free等等.要获取这些系统信息,Python可以通过subprocess模块调用并获取结果.但这样做显得很麻烦,尤其是要写很多解析代码. 在Python中获取系统信息的另一个好办法是
-
基于Python获取docx/doc文件内容代码解析
这篇文章主要介绍了基于Python获取docx/doc文件内容代码解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 整体思路: 下载文件并修改后缀为zip文件,解压zip文件,所要获取的内容在固定的文件夹下:work/temp/word/document.xml 所用包,全部是python自带,不需要额外下载安装. # encoding:utf-8 import os import re import requests import zipf