你真的了解触发器么 数据实时同步更新问题剖析
当我们想更新一张动态表的时候(即:表中的数据不断的添加),也许我们会用数据库代理,通过写作业,然后让他定时查询动态表中最新添加的数据,然后更新数据。这样时能实现更新数据的要求,但是数据却不能实时同步更新。
这个时候,触发器就是我们想要的神器了。我们可以在那张动态表上新建触发器。触发器的实质就是个存储过程,只不过他调用的时间是根据所建的动态表发生该表而执行(即:Insert新数据,Update或者Delete数据)。
具体怎么使用触发器,今天我这里就不介绍了,园子里资料多的很。那么我今天要介绍的是什么呢?
前几天在写sql代码的时候无意间发现了这么个问题:就是我一直以为每当动态表中插入一条数据,触发器就执行一次,但是我这样理解的话,当批量插入数据的时候,触发器执行的次数和插入的行数相同,但是事实不是这样。乘着今天有点时间,就想写出来和大家分享下,讲的不对请大家斧正!
--我们要建触发器的动态表
Create table Table_a
(
ID int identity(1,1),--自增ID
Content nvarchar(50),
UpdateIDForTrigger int
)
Create TRIGGER [dbo].[Table_a_Ins]
ON [dbo].[Table_a]
AFTER INSERT
AS
BEGIN
declare @ID int
set @ID=(select ID from inserted)
--更新Table_a表中的UpdateIDForTrigger字段的值,为了能更明显的看出实时执行的效果
UPDATE Table_a
SET UpdateIDForTrigger = (@ID+10)--为了能看出不同,就直接将比ID大10的值作为变量赋值
WHERE ID = @ID;
END
--给信息表添加数据
insert into Table_a(Content) values('信息一');
insert into Table_a(Content) values('信息二');
select * from Table_a
查询结果如图: 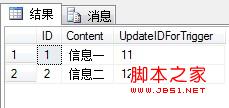
我们可以看到触发器执行了。在每条数据插入的时候触发器同时执行了Update功能。
然后,我们要批量插入数据,为了方便我们插入,我们这里建立一张临时的基本信息表:
代码如下:
--基本信息表
Create table Table_Info
(
ID int identity(1,1),
Content nvarchar(50)
)
insert into Table_Info(Content) values('信息三');
insert into Table_Info(Content) values('信息四');
insert into Table_Info(Content) values('信息五');
insert into Table_Info(Content) values('信息六');
insert into Table_Info(Content) values('信息七');
insert into Table_Info(Content) values('信息八');
insert into Table_Info(Content) values('信息九');
insert into Table_Info(Content) values('信息十');
insert into Table_a(Content)
select Content from Table_Info
这次重点来了,我们在执行这个sql语句的时候消息框中会出现错误提示: 
有经验的朋友会知道,这个错误是由于多个结果用“=”赋值给一个变量导致的。
即:set @变量=(select 多行结果 from Table)
这个时候,我就疑惑了,问题出在哪里了呢?不是触发器在每插一条数据的时候执行一次么?
于是,我将触发器改了下:
代码如下:
Alter TRIGGER [dbo].[Table_a_Ins]
ON [dbo].[Table_a]
AFTER INSERT
AS
BEGIN
select ID from inserted;
END
然后再执行上面的批量插入试试看,看看他inserted表中到底存的是什么值:
果然不出所料,inserted表中的结果并不是一条数据: 
知道错误的原因,我们操作起来就简单了,我们可以给inserted表建游标,然后通过游标来对批量插入的每行数据进行编辑。下面是我们修改后的触发器代码:
代码如下:
Alter TRIGGER [dbo].[Table_a_Ins]
ON [dbo].[Table_a]
AFTER INSERT
AS
BEGIN
declare @ID int
declare cur_Insert cursor
for
select ID from inserted
open cur_Insert
fetch next from cur_Insert into @ID
while @@fetch_status=0
begin
UPDATE Table_a
SET UpdateIDForTrigger = (@ID+10)--为了能看出不同,就直接将比ID大10的值作为变量赋值
WHERE ID = @ID;
fetch next from cur_Insert into @ID
end
close cur_Insert
deallocate cur_Insert
END
然后,我们再按照上面的批量插入数据,然后查询下动态表中的结果:
代码如下:
insert into Table_a(Content)
select Content from Table_Info;
select * from Table_a;
此时运行没有错误提示了,运行结果如下:
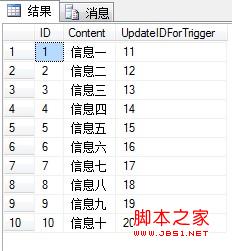
这样,批量插入插入数据时触发器也能用了。
然后结合了几位前辈的建议,再改了下触发器的代码。将上面的游标改成了下面的方式:
代码如下:
Alter TRIGGER [dbo].[Table_a_Ins]
ON [dbo].[Table_a]
AFTER INSERT
AS
BEGIN
UPDATE Table_a
SET UpdateIDForTrigger =inserted.ID+10
FROM inserted
Where Table_a.ID=inserted.ID
END
然后再批量插入了几行数据,结果也是可以的。所以学无止境啊!! 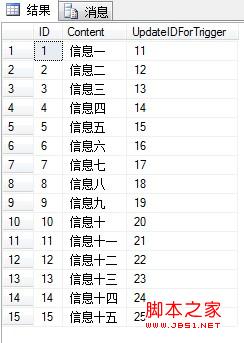
总结下:触发器运行是每次执行一次Insert操作或者是Update,Delete等操作的时候才执行的。它的对象不是针对于修改的行数(即:每行修改的时候执行)。
相关推荐
-
SQL触发器实例讲解
SQL触发器实例1 定义: 何为触发器?在SQL Server里面也就是对某一个表的一定的操作,触发某种条件,从而执行的一段程序.触发器是一个特殊的存储过程. 常见的触发器有三种:分别应用于Insert , Update , Delete 事件. 我为什么要使用触发器?比如,这么两个表: 复制代码 代码如下: Create Table Student( --学生表 StudentID int primary key, --学号 .... ) Create Table BorrowRecord(
-
MySQL触发器学习总结
复制代码 代码如下: #创建触发器,当往order表中添加记录是,更新goods表 delimiter $ CREATE TRIGGER trigger1 AFTER INSERT ON `order` FOR EACH ROW BEGIN UPDATE goods SET num=num-new.much WHERE id=new.gid; END$ 执行 INSERT INTO `order` (gid,much) VALUES(1,5) 后 SELECT * FROM goods WHER
-
SQLServer2005触发器提示其他会话正在使用事务的上下文的解决方法
MSDN上看了一下说是sql server 2005不支持在分布式事务处理中存在指向本地的链接服务器(环回链接服务器)个人尝试了下是由于在双向的sql server访问中采用了链式方式访问(LinkedServer方式),遇到这种情况只需要将原来访问对方数据库的语句: 复制代码 代码如下: select * from linkedServerA.dbo.table1 修改为: 复制代码 代码如下: select * from dbo.table1 即可. 触发器代码如下: 复制代码
-
SQL SERVER 触发器介绍
触发器是一种特殊类型的存储过程,它不同于之前的我们介绍的存储过程.触发器主要是通过事件进行触发被自动调用执行的.而存储过程可以通过存储过程的名称被调用. Ø 什么是触发器 触发器对表进行插入.更新.删除的时候会自动执行的特殊存储过程.触发器一般用在check约束更加复杂的约束上面.触发器和普通的存储过程的区别是:触发器是当对某一个表进行操作.诸如:update.insert.delete这些操作的时候,系统会自动调用执行该表上对应的触发器.SQL Server 2005中触发器可以分为两类:DM
-
Sql Server触发器的使用
Sql Server为每个触发器都创建了两个专用表:Inserted表和Deleted表.这两个表由系统来维护,它们存在于内存中而不是数据库中.这两个表的结构总是与被该触发器作用的表的结构相同,触发器执行完成后,与该触发器相关的这两个表也被删除. 对表的操作 Inserted逻辑表 Deleted逻辑表 增加记录(insert) 存放增加的记录 无 删除记录(delete) 无 存放被删除的记录 修改记录(update) 存放更新后的记录 存放更新前的记录 三.for.after.instead
-

你真的了解触发器么 数据实时同步更新问题剖析
当我们想更新一张动态表的时候(即:表中的数据不断的添加),也许我们会用数据库代理,通过写作业,然后让他定时查询动态表中最新添加的数据,然后更新数据.这样时能实现更新数据的要求,但是数据却不能实时同步更新. 这个时候,触发器就是我们想要的神器了.我们可以在那张动态表上新建触发器.触发器的实质就是个存储过程,只不过他调用的时间是根据所建的动态表发生该表而执行(即:Insert新数据,Update或者Delete数据). 具体怎么使用触发器,今天我这里就不介绍了,园子里资料多的很.那么我今天要介绍的是
-
sersync实现数据实时同步的方法
1.1 第一个里程碑:安装sersync软件 1.1.1 将软件上传到服务器当中并解压 1.上传软件到服务器上 rz -E 为了便于管理上传位置统一设置为 /server/tools 中 2.解压软件包 [root@backup sersync_installdir_64bit]# tree . └── sersync ├── bin │ └── sersync ├── conf │ └── confxml.xml └── logs 1.1.2 二进制包安装方法 二进制包安装软件方法(绿色软件安
-
Linux下sersync数据实时同步
sersync其实是利用inotify和rsync两种软件技术来实现数据实时同步功能的,inotify是用于监听sersync所在服务器上的文件变化,结合rsync软件来进行数据同步,将数据实时同步给客户端服务器. 工作过程:在同步主服务器上开启sersync,负责监听文件系统的变化,然后调用rsync命令把更新的文件同步到目标服务器上,主服务器上安装sersync软件,目标服务器上安装rsync服务. 1.客户端配置 [root@localhost2 ~]# cat /etc/rsyncd.c
-
Linux 通过Rsync+Inotify实现本、异地远程数据实时同步功能
0x0 测试环境 总部生产服务器与分部备份服务器要求实现异地数据备份,环境如下 **centos 6.5** 生产服务器目录: /home/zytest/files 备份服务器目录: /home/zytest/files 用户 / 密码: zytest / zytest 0x1 生产服务器环境搭建 0x1.1 安装gcc编译器和rsync yum install gcc rsync -y 0x1.2 拷贝inotify到服务器并解压 cd /root tar xfvz inotify-tools
-
Linux利用inotify和rsync服务实现数据实时同步的原理解析
目录 文件定时同步的实现: 文件实时同步的实现: inotify inotify-tools包主要工具: inotifywait 命令: rsync工具 rsync有三种工作方式: 两种方式实现rsync服务器 方式一:通过rsync守护进程的方式实现rsync服务 以独立服务方式运行rsync并实现验证功能 工作原理: inotify+rsync+shell 脚本实现实时数据同步 文件定时同步的实现: 利用rsync结合cron计划任务实现: rsync -av --delete /data/
-
SQL Server实时同步更新远程数据库遇到的问题小结
工作中遇到这样的情况,需要在更新表TableA(位于服务器ServerA 172.16.8.100中的库DatabaseA)同时更新TableB(位于服务器ServerB 172.16.8.101中的库DatabaseB). TableA与TableB结构相同,但数据数量不一定相同,应为有可能TableC也在更新TableB.由于数据更新不频繁,为简单起见想到使用了触发器Tirgger.记录一下遇到的一些问题: 1. 访问异地数据库 在ServerA 中创建指向ServerB的链接服务器,并做好
-
inotify+rsync实现实时同步的方法
1.1 什么是实时同步:如何实现实时同步 要利用监控服务(inotify),监控同步数据服务器目录中信息的变化 发现目录中数据产生变化,就利用rsync服务推送到备份服务器上 1.2 实现实时同步的方法 inotify+rsync 方式实现数据同步 sersync 方式实现实时数据同步 详情参照:sersync实现数据实时同步的方法 1.2.1 实时同步原理介绍 1.3 inotify+rsync 方式实现数据同步 1.3.1 Inotify简介 Inotify是一种强大的,细粒度的.异步的文件
-
详解MySQL实时同步到Oracle解决方案
1 需求概述 将MySQL5.6生产库多张表的数据实时同步到Oracle11g数据仓库,MySQL历史数据700G,平均每天产生50G左右日志文件,MySQL日志空间50G,超过后滚动删除日志文件.整个同步过程不可影响MySQL业务操作. 2 技术原理 采用灵蜂数据集成软件BeeDI将MySQL数据实时同步到Oracle,通过ETL全量同步历史数据,通过日志解析方式实时同步增量数据. 受限于日志空间,如果将所有历史数据一次性同步,需要的时间会超过一天,全量同步过程产生的日志会被删除,造成实时日志
-
实现vuex与组件data之间的数据同步更新方式
问题 我们都知道,在Vue组件中,data部分的数据与视图之间是可以同步更新的,假如我们更新了data中的数据,那么视图上的数据就会被同步更新,这就是Vue所谓的数据驱动视图思想. 当我们使用Vuex时,我们也可以通过在视图上通过 $store.state.[DataKey] 来获取Vuex中 state 的数据,且当 state 中的数据发生变化时,视图上的数据也是可以同步更新的,这似乎看起来很顺利. 但是当我们想要通过将 state 中的数据绑定到Vue组件的 data 上,然后再在视图上去
-
如何使用Maxwell实时同步mysql数据
Maxwell简介 maxwell是由java编写的守护进程,可以实时读取mysql binlog并将行更新以JSON格式写入kafka.rabbitMq.redis等中, 这样有了mysql增量数据流,使用场景就很多了,比如:实时同步数据到缓存,同步数据到ElasticSearch,数据迁移等等. maxwell官网:http://maxwells-daemon.io maxwell源代码:https://github.com/zendesk/maxwell Maxwell的配置与使用 m