mysql跨服务查询之FEDERATED存储引擎的实现
目录
- 一、FEDERATED存储引擎
- 1.1、说明:
- 1.2、局限性
- 1.3、跨服务的方式
- 二、开启FEDERATED存储引擎
- 1.1、查看存储引擎
- 三、跨服务连接示例
- 1.1、 目标:
- 1.2、创建关系
- 1.3、成功效果
- 1.4、增删改查
一、FEDERATED存储引擎
01、从5.1.26开始,默认MySQL不启用federated存储引擎,所以需要在my.cnf中加入federated选项
02、或是在命令行用–federated选项启动mysqld。
1.1、说明:
mysql 提供了一个类似Oracle中的数据库链接(DBLINK)功能的存储引擎–FEDERATED
当我们创建一个以FEDERATED为存储引擎的表时,服务器在数据库目录只创建一个表定义文件。文件由表的名字开始,并有一个frm扩展名。无其它文件被创建,因为实际的数据在一个远程数据库上。这不同于为本地表工作的存储引擎的方式。
1.2、局限性
远程服务器必须是一个MySQL服务器。
远程服务器必须是一个MySQL服务器。
FEDERATED对其它数据库引擎的支持可能会在将来被添加,目前不支持其他数据库,跨服务器远程其他类型数据库可以采用创建远程连接服务器的方式
FEDERATED表指向的远程表在你通过FEDERATED表访问它之前必须存在。
一个FEDERATED表指向另一个FEDERATED表是可能的,但是你必须小心不要创建一个循环。
没有对事务的支持。
如果远程表已经改变,对FEDERATED引擎而言是没有办法知道的。
a、这个的原因是因为这个表必须象数据文件一样工作,除了数据库其它任何都不会被写入。
b、如果有任何对远程数据库的改变,本地表中数据的完整性可能会被破坏。
FEDERATED存储引擎支持SELECT, INSERT, UPDATE, DELETE和索引。
它不支持ALTER TABLE, DROP TABLE或任何其它的数据定义语言语句。当前的实现不使用预先准备好的语句。
执行使用SELECT, INSERT, UPDATE和DELETE,但不用HANDLER。
FEDERATED表不能对查询缓存不起作用。
目前的局限性是这些。
这些限制中的一些在FEDERATED处理机的将来版本可能被消除。
1.3、跨服务的方式
- mysql的FEDERATED存储引擎
- oracle的dblink
- 创建远程连接服务器
- 大数据的presto,接管数据源,然后聚合分析
- fink cdc也是一种方案
二、开启FEDERATED存储引擎
1.1、查看存储引擎
- 存在的FEDERATED存储引擎就配置文件开启
- 不存在就安装
查看
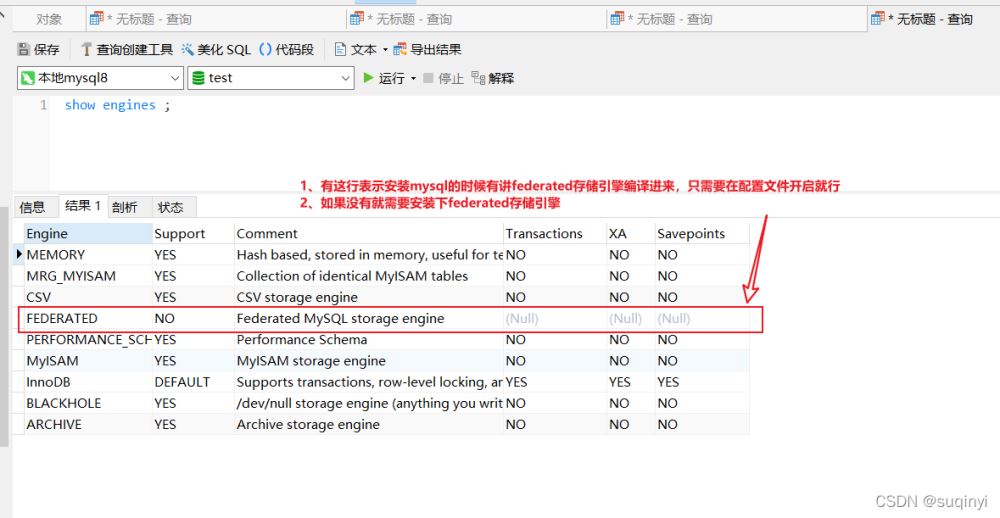
show engines;
Support 的值有以下几个:
- YES 支持并开启
- DEFAULT 支持并开启, 并且为默认引擎
- NO 不支持
- DISABLED 支持,但未开启
如图:
1.1.1、不存在存储引擎-安装
federated是支持动态安装的
install plugin federated soname 'ha_federated.so';
注明:如果不行话,就重新编码安装mysql吧
1.2、开启存储引擎
在mysql的配置文件中加入federated,然后重启mysql
注意:要放在mysqld的模块下,放在其他模块下无法识别变量
如图:

可以登入,表示变量识别成功

查看存储引擎
yes表示开启成功

1.3、拓展mysql存储引擎对比

三、跨服务连接示例
FEDERATED存储引擎开启成功了
1.1、 目标:
本地mysql去链接云服务器的mysql

1.2、创建关系
注意:如果远程表已经改变,对FEDERATED引擎而言是没有办法知道的
要了解FEDERATED存储引擎的局限性,看本文1.2的说明
如果有任何对远程数据库的改变,本地表中数据的完整性可能会被破坏
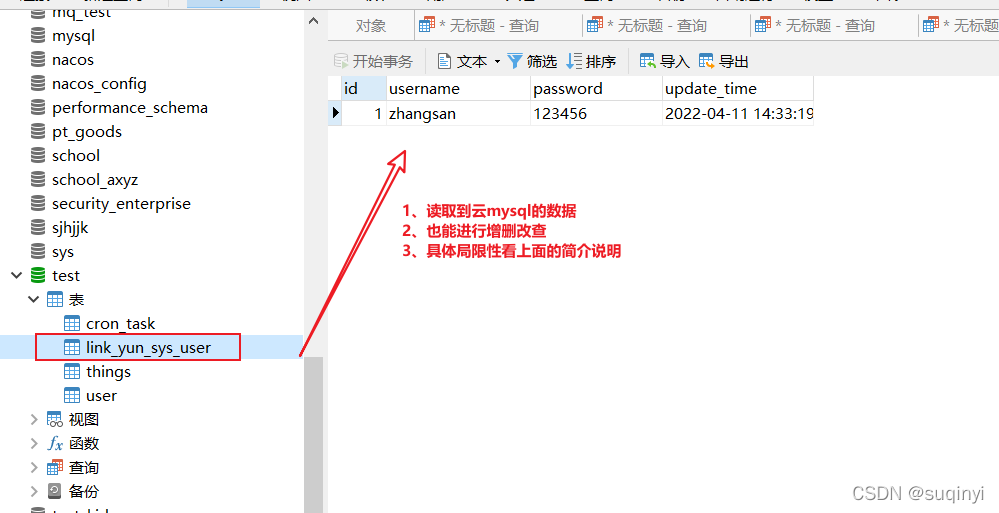
建议:表名要见名知意,知道他是远程连接的表,就像下面的示例:link_xx_xx表
创建
-- 创建出结构一样的表,表名可以不一样 CREATE TABLE `link_yun_sys_user` ( `id` int(50) NOT NULL, `username` varchar(50) DEFAULT NULL, `password` varchar(50) DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = FEDERATED CONNECTION='mysql://root:root@81.1x.2xx.10:3306/testLink/sys_user' -- 指定引擎为 FEDERATED -- 指定用户名、密码、ip、端口、数据库、表
如图:

1.2.1、权限说明
如果数据库有做权限限制,比如用户权限,增删改查权限,要进行授权,才能进行操作
1.3、成功效果
1.4、增删改查
本地新增1条数据
INSERT INTO link_yun_sys_user(id,username,`password`,update_time) VALUES('2','lisi','8888',NOW());

云服务器查看
SELECT * FROM sys_user

到此这篇关于mysql跨服务查询之FEDERATED存储引擎的实现的文章就介绍到这了,更多相关mysql FEDERATED存储引擎内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql自动停止 Plugin FEDERATED is disabled 的完美解决方法
这两天新买的服务器mysql总是自动停止,查了日志 9:13:57 [Note] MySQL: Normal shutdown 9:13:57 [Note] Event Scheduler: Purging the queue. 0 events 9:13:57 InnoDB: Starting shutdown... 9:13:58 InnoDB: Shutdown completed; log sequence number 0 44273 9:13:58 [Note]
-

Mysql 开启Federated引擎的方法
MySQL中针对不同的功能需求提供了不同的存储引擎.所谓的存储引擎也就是MySQL下特定接口的具体实现. FEDERATED是其中一个专门针对远程数据库的实现.一般情况下在本地数据库中建表会在数据库目录中生成相应的表定义文件,并同时生成相应的数据文件. 但通过FEDERATED引擎创建的表只是在本地有表定义文件,数据文件则存在于远程数据库中(这一点很重要). 通过这个引擎可以实现类似Oracle 下DBLINK的远程数据访问功能. 使用show engines 命令查看数据库是否已支持FEDER
-
mysql跨服务查询之FEDERATED存储引擎的实现
目录 一.FEDERATED存储引擎 1.1.说明: 1.2.局限性 1.3.跨服务的方式 二.开启FEDERATED存储引擎 1.1.查看存储引擎 三.跨服务连接示例 1.1. 目标: 1.2.创建关系 1.3.成功效果 1.4.增删改查 一.FEDERATED存储引擎 01.从5.1.26开始,默认MySQL不启用federated存储引擎,所以需要在my.cnf中加入federated选项02.或是在命令行用–federated选项启动mysqld. 1.1.说明: mysql 提供了一个
-
详解mysql跨库查询解决方案
1.第一种跨库查询,是在同一个mysql服务器下两个不同的数据库之间的联查,关系如下图 在同一个mysql服务器下,不同的两个数据直接加上库名就可以实现跨库查询了 select * from t_test1 t1, test2.t_test2 t2 where t1.id = t2.id 执行sql查询到一下结果 2.第二种跨库查询,是在两台不同服务器(物理服务器)上分别安装的mysql服务器,实现跨库查询,其实现原理类似一个虚拟映射,需要用到mysql的另一个存储引擎Federated,FED
-
Mysql详细剖析数据库中的存储引擎
目录 前言 存储引擎 什么是存储引擎? Mysql的体系结构: Mysql的体系结构分为四层: 存储引擎的查看 存储引擎的指定 存储引擎的特点 InnoDB介绍 InnoDB特点 InnoDB文件 存储引擎的选择 总结撒花 前言 哈喽各位友友们,我今天又学到了很多有趣的知识,现在迫不及待的想和大家分享一下!我仅已此文,和大家分享[Mysql系列]——详细剖析数据库中的存储引擎~都是精华内容,可不要错过哟!!! 存储引擎 什么是存储引擎? 存储引擎是数据库中非常关键的部分,它就像是飞机.火箭中的引
-
MySQL跨表查询与跨表更新
有点 SQL 基础的朋友肯定听过 「跨表查询」,那啥是跨表更新啊? 背景 项目新导入了一批人员数据,这些人的有的部门名称发生了变化,有的联系方式发生了变化,暂且称该表为 t_dept_members, 系统中有另外一张表 t_user_info 记录了人员信息.要求将 t_dept_members 中有变化的信息更新到 t_user 表中,这个需求就是「跨表更新」啦 憨B SQL 直接被秒杀 不带脑子出门的就写出了下面的 SQL 看到身后 DBA 小段总在修仙,想着让他帮润色一下
-
mysql 跨表查询、更新、删除示例
下面来谈谈跨表插入,更新和删除 首先讨论的是跨表查询: insert into `table_A` select * from `table_B`;注意*代表全部插入. 接着又讨论关于跨表更新 复制代码 代码如下: update `table_A`, `table_B` set `table_A`.`name` = `table_B`.`name` where `table_A`.`id` = `table_B`.`id`;
-
详解mysql中的存储引擎
mysql存储引擎概述 什么是存储引擎? MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力.通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能. 例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎.内存存储引擎能够在内存中存储所有的表格数据.又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力). 这些不同的技术以及配套的相关
-
基于MySQL的存储引擎与日志说明(全面讲解)
1.1 存储引擎的介绍 1.1.1 文件系统存储 文件系统:操作系统组织和存取数据的一种机制.文件系统是一种软件. 类型:ext2 3 4 ,xfs 数据. 不管使用什么文件系统,数据内容不会变化,不同的是,存储空间.大小.速度. 1.1.2 mysql数据库存储 MySQL引擎: 可以理解为,MySQL的"文件系统",只不过功能更加强大. MySQL引擎功能: 除了可以提供基本的存取功能,还有更多功能事务功能.锁定.备份和恢复.优化以及特殊功能. 1.1.3 MySQL存储引擎种类
-
MySQL中进行跨库查询的方法示例
前言 在MySQL中跨库查询主要分为两种情况,一种是同服务的跨库查询:另一种是不同服务的跨库查询:它们进行跨库查询是不同的,下面就具体介绍这两种跨库查询. 一.同服务的跨库查询 同服务的跨库查询只需要在关联查询的时候带上数据名,SQL的写法是这样的:SELECT * FROM 数据库1.table1 x JOIN 数据库2.table2 y ON x.field1=y.field2:例如: 二.不同服务的跨库查询 不同服务的跨库查询,直接通过数据名加表明是无法进行关联的,这里需要用到MySQL数
-
深入MySQL存储引擎比较的详解
MyISAM是MySQL的默认存储引擎.MyISAM不支持事务.也不支持外键,但其访问速度快,对事务完整性没有要求. InnoDB存储引擎提供了具有提交.回滚和崩溃恢复能力的事务安全.但是比起MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引. MEMORY存储引擎使用存在内存中的内容来创建表.每个MEMORY表只实际对应一个磁盘文件.MEMORY类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用HASH索引.但是一旦服务关闭,表中的数据就会
-
MySQL修改默认存储引擎的实现方法
mysql存储引擎: MySQL服务器采用了模块化风格,各部分之间保持相对独立,尤其体现在存储架构上.存储引擎负责管理数据存储,以及MySQL的索引管理.通过定义的API,MySQL服务器能够与存储引擎进行通信.目前使用最多的是MyISAM和InnoDB.InnoDB被Oracle收购后,MySQL自行开发的新存储引擎Falcon将在MySQL6.0版本引进. MyISAM引擎是一种非事务性的引擎,提供高速存储和检索,以及全文搜索能力,适合数据仓库等查询频繁的应用.MyISAM中,一个table